JSP頁面請求響應過程中的編碼解碼
該片簡要講述:JSP頁面傳輸過程中,瀏覽器與伺服器的編碼解碼以及HTTP協議對URL進行的編碼解碼。
問題如下:
//所有的JSP頁面的編碼都是UTF-8的格式 //test1.jsp <%@ page language="java" import="java.util.*,java.net.*" pageEncoding="UTF-8"%> <a href="test2.jsp?str=<%=URLEncoder.encode("中國人","gb2312") %>">連結</a> //test2.jsp <%@ page language="java" import="java.util.*,java.net.*" pageEncoding="UTF-8"%> <% String name= URLDecoder.decode(request.getParameter("str"),"gb2312"); name =new String(name1.getBytes("ISO-8859-1"),"gb2312"); %> <%=name %>
首先簡要描述點選連結到頁面顯示過程:
點選連結 – 瀏覽器編碼(HTTP URL 編碼) – 伺服器解碼 – 構建返回資料體–伺服器編碼 – 瀏覽器解碼。
POST請求不再多說,亂碼主要發生在GET請求且URL後面追加了中文引數。
上述例子,過程應該是這樣:
① 首先在頁面中進行了URL編碼:
結果如下:
<a href="test2.jsp?str=%D6%D0%B9%FA%C8%CB">連結</a> //這裡手動進行URL編碼,等效於瀏覽器對中文進行編碼。 //因為引數在url上面,是GET請求,故而URL編碼解碼是瀏覽器和伺服器的關係,與我們無關。 //如果不做設定,預設編碼方式為是ISO-8859-1。
② 瀏覽器編碼
-
因為GET請求,只有URL(引數附加於URL),故只對URL進行編碼。
-
因為非直接在瀏覽器輸入地址進行請求,而是點選文件內連結。故編碼依據文件編碼 —UTF-8
-
因為JSP頁面手動指定了編碼格式,且進行了URL編碼。
③ HTTP傳輸
資料在網路中以報文的形式,二進位制流的格式進行傳輸。伺服器拿到的path之後需進行解析。這個過程預設編碼方案為ISO-8859-1。
至此,是這樣子的:ISO-8859-1(UTF-8(<a href="test2.jsp?str=%D6%D0%B9%FA%C8%CB">連結</a>))。
④ 伺服器解碼
web伺服器接收到客戶端的請求後,會將其內容轉給web容器來處理;
因為接到的請求path(url)是編碼過的二進位制流,所以在處理前會將其轉換成ASCII碼 。但是請求中可能還有部分引數和訊息體的資料是經過編碼的(例如中文字元被編碼),這裡就涉及到對請求內容和引數進行解碼的問題。
Tomcat 預設對url 使用 ISO-8859-1解碼。注意:ISO-8859-1 為單位元組表示。
所以,無論你前面瀏覽器進行了什麼編碼,塵歸塵,土歸土,一切都還原到位元組(不過這裡的位元組是由特定字符集轉換而來的,即 第一個頁面的GB2312)!!!
在這裡,剝去了外面的ISO-8859-1,剩下UTF-8(<a href="test2.jsp?str=%D6%D0%B9%FA%C8%CB">連結</a>)。
⑤ 過程描述
原URL---->GET時瀏覽器根據HTTP頭的Content-Type的charset,POST根據(content="text/html; charset=utf-8")對URL進行編碼或者利用JavaScript(如果JavaScript編碼了則瀏覽器一看都是ASCII字元就不再編碼)使用GBK或者UTF-8等編碼對URL進行編碼
---->ASCII字元 + %
---->以iso-8859-1編碼方式轉換為二進位制
---->隨請求頭一起傳送出去(GET沒有請求實體, POST有)
---->伺服器接收到經過iso-8859-1編碼後的URL
---->伺服器用iso-8859-1編碼進行解碼
---->得到值(這裡得到URL中文引數的位元組資訊)
⑥ Tomcat 返回響應
構建資料體,設定響應型別和編碼(UTF-8)。。。
ContentType : text/html;charset=UTF-8
該過程中會拿到請求傳過來的引數:
方法一:
String name= URLDecoder.decode(request.getParameter("str"),"gb2312");
//此時name仍舊為亂碼
name=new String(name2.getBytes("ISO-8859-1"));
//預設使用系統編碼,可使用System.getProperty("file.encode");進行檢視
Charset.defaultCharset()方法如下所示:
public static Charset defaultCharset() {
if (defaultCharset == null) {
synchronized (Charset.class) {
String csn = AccessController.doPrivileged(
new GetPropertyAction("file.encoding"));
Charset cs = lookup(csn);
if (cs != null)
defaultCharset = cs;
else
defaultCharset = forName("UTF-8");
}
}
return defaultCharset;
}
使用request.getParameter()獲取的資料是被伺服器誤認為ISO-8859-1編碼的,也就是說客戶端傳送過來的資料無論是UTF-8還是GBK,伺服器都認為是ISO-8859-1,這就說明我們需要在使用request.getParameter()獲取資料後,再轉發成正確的編碼。
如下所示,則正確解碼:
String name=URLDecoder.decode("%D6%D0%B9%FA%C8%CB", "gb2312");
// name 中國人
注意,%D6%D0%B9%FA%C8%C直接使用gb2312解碼可得到正確結果。但是如果使用request.getParameter獲取str則會得到亂碼ÖйúÈË。
那麼,為什麼不直接使用ISO-8859-1獲取位元組,然後再使用GBK或者gb2312解碼呢?URLDecoder.decode(request.getParameter("str"),"gb2312");完全就是多餘了。
ISO-8859-1向下相容ASCII,並且HTTP通訊過程中預設使用的就是ISO-8859-1編碼。
方法二:
String name=new String(request.getParameter("str").getBytes("ISO-8859-1"),"GBK");
//GBK GB2312
//String name2 = new String(request.getParameter("str").getBytes("ISO-8859-1"),"UTF-8")
//name2 ���
其中方法一首先進行了URL解碼,其次直接使用new String([]bytes,charset)進行構建字串。
方法二則直接使用new String([]bytes,charset)進行構建字串。
伺服器拿到的是位元組流,因為 Tomcat 預設對URL使用ISO-8859-1進行解碼,所以可以直接直接使用new String([]bytes,charset)進行構建字串!需要注意的是這裡的charset需要與頁面進行URL編碼時候的編碼集一致。
方法三,使用request.getQueryString();獲取Query String。
既然引數在URL後面,那麼就在Query Data裡面可以使用request.getQueryString();方法獲取,如下所示:
String queryData = request.getQueryString();
//queryData: str=%D6%D0%B9%FA%C8%CB
//擷取str 值,再使用URLDecoder.decode()即可。
⑦ 瀏覽器解析響應
瀏覽器拿到響應資訊,開始進行解析。
首先會獲取解碼型別:UTF-8
【Tips】:
這裡說明一下何為URL編碼解碼:
編碼:
URLEncoder.encode("中國人","gbk")
**即:`%D6%D0%B9%FA%C8%CB`**
將字串以特定的編碼格式轉化成application/x-www-form-urlencoded 格式
根據2005年釋出的RFC3986“%編碼”規範:
- 對URL中屬於ASCII字符集的非保留字不做編碼;
- 對URL中的保留字需要取其ASCII內碼,然後加上“%”字首將該字元進行替換(編碼);
- 對於URL中的非ASCII字元需要取其Unicode內碼,然後加上“%”字首將該字元進行替換(編碼)。
由於這種編碼是採用“%”加上字元內碼的方式,所以,有些地方也稱其為“百分號編碼”。
JAVA原始碼翻譯:

題外話 :
如果 第一個頁面不進行URL編碼呢?
<a href="test2.jsp?str=中國人 ">連結</a>-->
測試的谷歌瀏覽器:
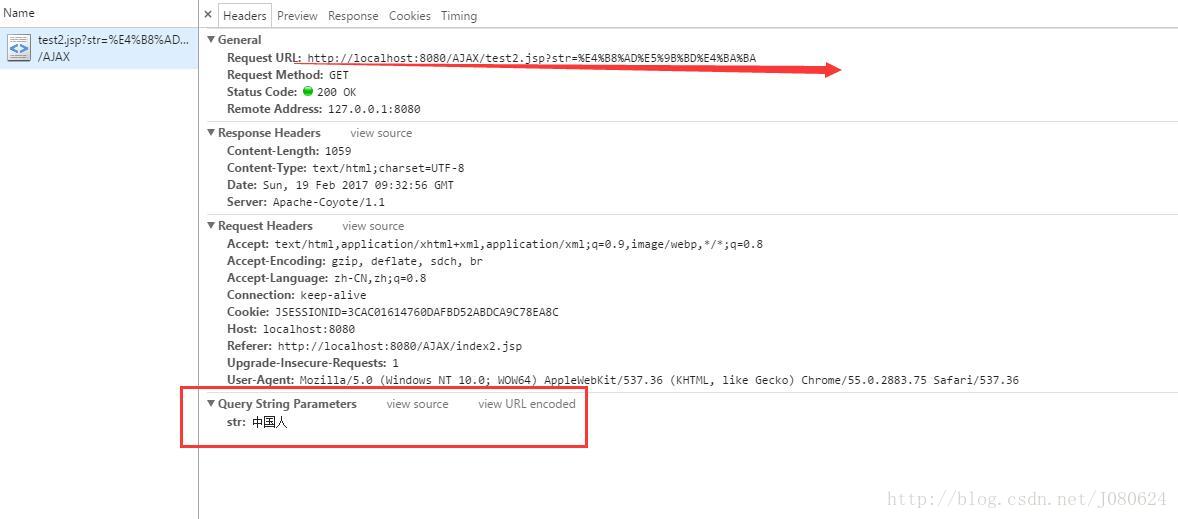
如上圖所示,瀏覽器會自動根據頁面編碼(UTF-8)進行URL編碼。
可直接使用上述方法二進行獲取。
String name=new String(request.getParameter("str").getBytes("ISO-8859-1"),"UTF-8");
//注意頁面編碼為UTF-8
需要注意JSP頁面中的Java程式碼<%=name %>,其實對應編譯後的 out.print(name);故而不需要再加;。另外out變數宣告的物件為JspWriter,其類繼承示意圖如下: