
輕量級開源記憶體資料庫SQLite效能測試
SQLite是一款輕型的資料庫,它佔用資源非常的低,同時能夠跟很多程式語言相結合,但是支援的SQL語句不會遜色於其他開源資料庫。它的設計目標是嵌入式的,而且目前已經在很多嵌入式產品中使用了它,它佔用資源非常的低,在嵌入式裝置中,可能只需要幾百K的記憶體就夠了。它能夠支援Windows/Linux/Unix等等主流的作業系統,同時能夠跟很多程式語言相結合,比如Tcl、PHP、Java 等,還有ODBC介面,同樣比起Mysql、PostgreSQL這兩款開源世界著名的資料庫管理系統來講,它的處理速度比他們都快。
SQLite雖然很小巧,但是支援的SQL語句不會遜色於其他開源資料庫,它支援的SQL包括:
BEGIN TRANSACTION
comment
COMMIT TRANSACTION
COPY
CREATE INDEX
CREATE TABLE
CREATE TRIGGER
CREATE VIEW
DELETE
DETACH DATABASE
DROP INDEX
DROP TABLE
DROP TRIGGER
DROP VIEW
END TRANSACTION
EXPLAIN
expression
INSERT
ON CONFLICT clause
PRAGMA
REPLACE
ROLLBACK TRANSACTION
UPDATE
同時它還支援事務處理功能等等。也有人說它象Microsoft的Access,有時候真的覺得有點象,但是事實上它們區別很大。比如SQLite 支援跨平臺,操作簡單,能夠使用很多語言直接建立資料庫,而不象Access一樣需要Office的支援。如果你是個很小型的應用,或者你想做嵌入式開發,沒有合適的資料庫系統,那麼現在你可以考慮使用SQLite。它的官方網站是:http://www.SQLite.org或者http://www.SQLite.com.cn,能在上面獲得原始碼和文件。同時因為資料庫結構簡單,系統原始碼也不是很多,也適合想研究資料庫系統開發的專業人士。
下面是訪問SQLite官方網站: http://www.SQLite.org/ 時第一眼看到關於SQLite的特性:
• 零配置 – 無需安裝和管理配置
• 儲存在單一磁碟檔案中的一個完整的資料庫
• 資料庫檔案可以在不同位元組順序的機器間自由的共享
• 支援資料庫大小至2TB
• 足夠小, 大致3萬行C程式碼, 250K
• 比一些流行的資料庫在大部分普通資料庫操作要快
• 簡單, 輕鬆的API
• 包含TCL繫結, 同時通過Wrapper支援其他語言的繫結
• 良好註釋的原始碼, 並且有著90%以上的測試覆蓋率
• 獨立: 沒有額外依賴
• Source完全的Open, 你可以用於任何用途, 包括出售它
• 支援多種開發語言,C, PHP, Perl, Java, ASP.NET,Python
安裝配置
要使用SQLite,需要從SQLite官網下載到三個檔案,分別為SQLite3.a,SQLite3.h,然後再在自己的工程中配置好標頭檔案和庫檔案,同時將dll檔案放到當前目錄下,就完成配置可以使用SQLite了。
使用的過程根據使用的函式大致分為如下幾個過程:
• SQLite3_open()• SQLite3_prepare()
• SQLite3_step()
• SQLite3_column()
• SQLite3_finalize()
• SQLite3_close()
這幾個過程是概念上的說法,而不完全是程式執行的過程,如SQLite3_column()表示的是對查詢獲得一行裡面的資料的列的各個操作統稱,實際上在SQLite中並不存在這個函式。
SQLite3_open():開啟資料庫
在操作資料庫之前,首先要開啟資料庫。這個函式開啟一個SQLite資料庫檔案的連線並且返回一個數據庫連線物件。這個操作同時程式中的第一個呼叫的SQLite函式,同時也是其他SQLite api的先決條件。許多的SQLite介面函式都需要一個數據庫連線物件的指標作為它們的第一個引數。
1.函式定義:
int SQLite3_open(const char *filename, /* Database filename (UTF-8) */
SQLite3 **ppDb /* OUT: SQLite db handle */
);
int SQLite3_open16(
const void *filename, /* Database filename (UTF-16) */
SQLite3 **ppDb /* OUT: SQLite db handle */
);
int SQLite3_open_v2(
const char *filename, /* Database filename (UTF-8) */
SQLite3 **ppDb, /* OUT: SQLite db handle */int flags, /* Flags */const char *zVfs /* Name of VFS module to use */
);
2.說明:
假如這個要被開啟的資料檔案不存在,則一個同名的資料庫檔案將被建立。如果使用SQLite3_open和SQLite3_open_v2的話,資料庫將採用UTF-8的編碼方式,SQLite3_open16採用UTF-16的編碼方式
3.返回值:
如果SQLite資料庫被成功開啟(或建立),將會返回SQLITE_OK,否則將會返回錯誤碼。SQLite3_errmsg()或者SQLite3_errmsg16可以用於獲得資料庫開啟錯誤碼的英文描述,這兩個函式定義為:
const char *SQLite3_errmsg(SQLite3*);const void *SQLite3_errmsg16(SQLite3*);
4.引數說明:
· filename:需要被開啟的資料庫檔案的檔名,在SQLite3_open和SQLite3_open_v2中這個引數採用UTF-8編碼,而在SQLite3_open16中則採用UTF-16編碼
· ppDb:一個數據庫連線控制代碼被返回到這個引數,即使發生錯誤。唯一的一場是如果SQLite不能分配記憶體來存放SQLite物件,ppDb將會被返回一個NULL值。
· flags:作為資料庫連線的額外控制的引數,可以是SQLITE_OPEN_READONLY,SQLITE_OPEN_READWRITE和SQLITE_OPEN_READWRITE|SQLITE_OPEN_CREATE中的一個,用於控制資料庫的開啟方式,可以和SQLITE_OPEN_NOMUTEX,SQLITE_OPEN_FULLMUTEX, SQLITE_OPEN_SHAREDCACHE,以及SQLITE_OPEN_PRIVATECACHE結合使用,具體的詳細情況可以查閱文件。
SQLite3_prepare()
這個函式將sql文字轉換成一個準備語句(prepared statement)物件,同時返回這個物件的指標。這個介面需要一個數據庫連線指標以及一個要準備的包含SQL語句的文字。它實際上並不執行(evaluate)這個SQL語句,它僅僅為執行準備這個sql語句
1.函式定義(僅列出UTF-8的):
int SQLite3_prepare(SQLite3 *db, /* Database handle */const char *zSql, /* SQL statement, UTF-8 encoded */int nByte, /* Maximum length of zSql in bytes. */
SQLite3_stmt **ppStmt, /* OUT: Statement handle */const char **pzTail /* OUT: Pointer to unused portion of zSql */
);
int SQLite3_prepare_v2(
SQLite3 *db, /* Database handle */const char *zSql, /* SQL statement, UTF-8 encoded */int nByte, /* Maximum length of zSql in bytes. */
SQLite3_stmt **ppStmt, /* OUT: Statement handle */const char **pzTail /* OUT: Pointer to unused portion of zSql */
);
2.引數:
db:資料指標
zSql:sql語句,使用UTF-8編碼
nByte:如果nByte小於0,則函式取出zSql中從開始到第一個0終止符的內容;如果nByte不是負的,那麼它就是這個函式能從zSql中讀取的位元組數的最大值。如果nBytes非負,zSql在第一次遇見’/000/或’u000’的時候終止
pzTail:上面提到zSql在遇見終止符或者是達到設定的nByte之後結束,假如zSql還有剩餘的內容,那麼這些剩餘的內容被存放到pZTail中,不包括終止符
ppStmt:能夠使用SQLite3_step()執行的編譯好的準備語句的指標,如果錯誤發生,它被置為NULL,如假如輸入的文字不包括sql語句。呼叫過程必須負責在編譯好的sql語句完成使用後使用SQLite3_finalize()刪除它。
3.說明:
如果執行成功,則返回SQLITE_OK,否則返回一個錯誤碼。推薦在現在任何的程式中都使用SQLite3_prepare_v2這個函式,SQLite3_prepare只是用於前向相容
4.備註:
<1>準備語句(prepared statement)物件:
typedef struct SQLite3_stmt SQLite3_stmt;準備語句(prepared statement)物件一個代表一個簡單SQL語句物件的例項,這個物件通常被稱為“準備語句”或者“編譯好的SQL語句”或者就直接稱為“語句”。
語句物件的生命週期經歷這樣的過程:
• 使用SQLite3_prepare_v2或相關的函式建立這個物件• 使用SQLite3_bind_*()給宿主引數(host parameters)繫結值
• 通過呼叫SQLite3_step一次或多次來執行這個sql
• 使用SQLite3——reset()重置這個語句,然後回到第2步,這個過程做0次或多次
• 使用SQLite3_finalize()銷燬這個物件
在SQLite中並沒有定義SQLite3_stmt這個結構的具體內容,它只是一個抽象型別,在使用過程中一般以它的指標進行操作,而SQLite3_stmt型別的指標在實際上是一個指向Vdbe的結構體得指標
<2>宿主引數(host parameters)
在傳給SQLite3_prepare_v2()的sql的語句文字或者它的變數中,滿足如下模板的文字將被替換成一個引數:
• ? ?• ? ?NNN,NNN代表數字
• ? :VVV,VVV代表字元
• ? @VVV
• ? $VVV
在上面這些模板中,NNN代表一個數字,VVV代表一個字母數字標記符(例如:222表示名稱為222的標記符),sql語句中的引數(變數)通過上面的幾個模板來指定,如
“select ? from ? “這個語句中指定了兩個引數,SQLite語句中的第一個引數的索引值是1,這就知道這個語句中的兩個引數的索引分別為1和2,使用”?”的話會被自動給予索引值,而使用”?NNN”則可以自己指定引數的索引值,它表示這個引數的索引值為NNN。”:VVV”表示一個名為”VVV”的引數,它也有一個索引值,被自動指定。
可以使用SQLite3_bind_*()來給這些引數繫結值。
SQLite3_setp()
這個過程用於執行有前面SQLite3_prepare建立的準備語句。這個語句執行到結果的第一行可用的位置。繼續前進到結果的第二行的話,只需再次呼叫SQLite3_setp()。繼續呼叫SQLite3_setp()知道這個語句完成,那些不返回結果的語句(如:INSERT,UPDATE,或DELETE),SQLite3_step()只執行一次就返回
1.函式定義
int SQLite3_step(SQLite3_stmt*);2.返回值
函式的返回值基於建立SQLite3_stmt引數所使用的函式,假如是使用老版本的介面SQLite3_prepare()和SQLite3_prepare16(),返回值會是 SQLITE_BUSY, SQLITE_DONE, SQLITE_ROW, SQLITE_ERROR 或 SQLITE_MISUSE,而v2版本的介面SQLite3_prepare_v2()和SQLite3_prepare16_v2()則會同時返回這些結果碼和擴充套件結果碼。
對所有V3.6.23.1以及其前面的所有版本,需要在SQLite3_step()之後呼叫SQLite3_reset(),在後續的SQLite3_ step之前。如果呼叫SQLite3_reset重置準備語句失敗,將會導致SQLite3_ step返回SQLITE_MISUSE,但是在V3. 6.23.1以後,SQLite3_step()將會自動呼叫SQLite3_reset。
int SQLite3_reset(SQLite3_stmt *pStmt);SQLite3_reset用於重置一個準備語句物件到它的初始狀態,然後準備被重新執行。所有sql語句變數使用SQLite3_bind*繫結值,使用SQLite3_clear_bindings重設這些繫結。SQLite3_reset介面重置準備語句到它程式碼開始的時候。SQLite3_reset並不改變在準備語句上的任何繫結值,那麼這裡猜測,可能是語句在被執行的過程中發生了其他的改變,然後這個語句將它重置到繫結值的時候的那個狀態。
SQLite3_column()
這個過程從執行SQLite3_step()執行一個準備語句得到的結果集的當前行中返回一個列。每次SQLite3_step得到一個結果集的列停下後,這個過程就可以被多次呼叫去查詢這個行的各列的值。對列操作是有多個函式,均以SQLite3_column為字首:
const void *SQLite3_column_blob(SQLite3_stmt*, int iCol);int SQLite3_column_bytes(SQLite3_stmt*, int iCol);
int SQLite3_column_bytes16(SQLite3_stmt*, int iCol);
double SQLite3_column_double(SQLite3_stmt*, int iCol);
int SQLite3_column_int(SQLite3_stmt*, int iCol);
SQLite3_int64 SQLite3_column_int64(SQLite3_stmt*, int iCol);
const unsigned char *SQLite3_column_text(SQLite3_stmt*, int iCol);
const void *SQLite3_column_text16(SQLite3_stmt*, int iCol);
int SQLite3_column_type(SQLite3_stmt*, int iCol);
SQLite3_value *SQLite3_column_value(SQLite3_stmt*, int iCol);
1.說明
第一個引數為從SQLite3_prepare返回來的prepared statement物件的指標,第二引數指定這一行中的想要被返回的列的索引。最左邊的一列的索引號是0,行的列數可以使用SQLite3_colum_count()獲得。
這些過程會根據情況去轉換數值的型別,SQLite內部使用SQLite3_snprintf()去自動進行這個轉換,下面是關於轉換的細節表:
|
內部型別 |
請求的型別 |
轉換 |
|
NULL |
INTEGER |
結果是0 |
|
NULL |
FLOAT |
結果是0.0 |
|
NULL |
TEXT |
結果是NULL |
|
NULL |
BLOB |
結果是NULL |
|
INTEGER |
FLOAT |
從整形轉換到浮點型 |
|
INTEGER |
TEXT |
整形的ASCII碼顯示 |
|
INTEGER |
BLOB |
同上 |
|
FLOAT |
INTEGER |
浮點型轉換到整形 |
|
FLOAT |
TEXT |
浮點型的ASCII顯示 |
|
FLOAT |
BLOB |
同上 |
|
TEXT |
INTEGER |
使用atoi() |
|
TEXT |
FLOAT |
使用atof() |
|
TEXT |
BLOB |
沒有轉換 |
|
BLOB |
INTEGER |
先到TEXT,然後使用atoi |
|
BLOB |
FLOAT |
先到TEXT,然後使用atof |
|
BLOB |
TEXT |
如果需要的話新增0終止符 |
注:BLOB資料型別是指二進位制的資料塊,比如要在資料庫中存放一張圖片,這張圖片就會以二進位制形式存放,在SQLite中對應的資料型別就是BLOB
int SQLite3_column_bytes(SQLite3_stmt*, int iCol),int SQLite3_column_bytes16(SQLite3_stmt*, int iCol)兩個函式返回對應列的內容的位元組數,這個位元組數不包括後面型別轉換過程中加上的0終止符。
下面是幾個最安全和最簡單的使用策略
• 先SQLite3_column_text() ,然後 SQLite3_column_bytes()• 先SQLite3_column_blob(),然後SQLite3_column_bytes()
• 先SQLite3_column_text16(),然後SQLite3_column_bytes16()
SQLite3_finalize
int SQLite3_finalize(SQLite3_stmt *pStmt);這個過程銷燬前面被SQLite3_prepare建立的準備語句,每個準備語句都必須使用這個函式去銷燬以防止記憶體洩露。
在空指標上呼叫這個函式沒有什麼影響,同時可以準備語句的生命週期的任一時刻呼叫這個函式:在語句被執行前,一次或多次呼叫SQLite_reset之後,或者在SQLite3_step任何呼叫之後不管語句是否完成執行
SQLite3_close
這個過程關閉前面使用SQLite3_open開啟的資料庫連線,任何與這個連線相關的準備語句必須在呼叫這個關閉函式之前被釋放。
Benchmark測試
1.測試環境
本次測試使用的軟硬體環境如下:
硬體配置:Intel(R) Core(TM) i7 CPU 860 @ 2.80GHz,4核8執行緒, 記憶體8GB。
作業系統: Redhat Enterprise Linux 6.0 X64。
2.測試假定
本次測試為充分展示記憶體資料庫的效能,使用SQLite的記憶體方式,以嵌入方式來完成測試。
3.資料結構
create table Record (id int, i1 int,i2 int,d1 double,d2 double, s1 VARCHAR(30), s2 VARCHAR(30))插入測試
1.單執行緒
首先進行單執行緒的插入測試,向資料庫中插入10000000條記錄,效能如下:
|
執行緒ID |
記錄數 |
耗時(毫秒) |
|
1 |
10000000 |
65631 |
|
每條記錄所花費的時間(微秒) |
6.56 |
|
|
每秒吞吐率(object/s) |
152439 |
|
單執行緒插入10000000條記錄的耗時為65.6秒,每條記錄的花費時間為6.56微秒,每秒處理的記錄數為15.2萬。
2.四執行緒
之後我們增加執行緒數為4.四個執行緒同時插入10000000條記錄,效能如下:
|
執行緒ID |
記錄數 |
耗時(毫秒) |
|
1 |
2500000 |
123733 |
|
2 |
2500000 |
124221 |
|
3 |
2500000 |
126657 |
|
4 |
2500000 |
126677 |
|
插入10000000條記錄所花費的總時間(秒) |
125.3 |
|
|
每條記錄所花費的時間(微秒) |
12.5322 |
|
|
每秒吞吐率(object/s) |
79794.4495 |
|
四個執行緒插入10000000條記錄的總耗時為125.3秒,平均每條記錄耗時12.5微秒,每秒處理8萬條資料。
3.八執行緒
最後將執行緒數增加到八個執行緒,向資料庫中新增10000000條記錄,每個執行緒的效能和總體效能如下:
|
執行緒ID |
記錄數 |
耗時(毫秒) |
|
1 |
1250000 |
147201 |
|
2 |
1250000 |
149193 |
|
3 |
1250000 |
150958 |
|
4 |
1250000 |
153391 |
|
5 |
1250000 |
153699 |
|
6 |
1250000 |
154038 |
|
7 |
1250000 |
155079 |
|
8 |
1250000 |
155119 |
|
插入10000000條記錄所花費的總時間(秒) |
152.33475 |
|
|
每條記錄所花費的時間(微秒) |
15.233475 |
|
|
每秒吞吐率(object/s) |
65644 |
|
可以看到8個併發寫入10000000條記錄所花費的時間大概為152秒,平均每秒可以新增65644條記錄。
4.總結
插入操作的總體吞吐率:
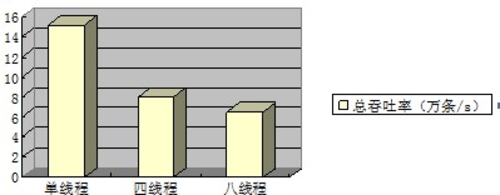
可以看到,插入操作的效能,單個執行緒併發操作時,吞吐率最大。這是由於SQLite在記憶體模式時,對於多執行緒的支援很弱。
更新測試
1.單執行緒
首先進行單執行緒的更新測試,在資料庫中進行10000000次更新,每次更新一條記錄的所有欄位,效能如下:
|
執行緒ID |
記錄數 |
耗時(毫秒) |
|
1 |
10000000 |
67519 |
|
每條記錄所花費的時間(微秒) |
6.75 |
|
|
每秒吞吐率(object/s) |
148106 |
|
單執行緒更新10000000條記錄的耗時為67秒,每條記錄的更新花費時間為6.75微秒,每秒處理的記錄數為14.8萬。
2.四執行緒
之後我們增加執行緒數為4.
四個執行緒同時更新10000000條記錄,效能如下:
|
執行緒ID |
記錄數 |
耗時(毫秒) |
|
1 |
2500000 |
121080 |
|
2 |
2500000 |
124996 |
|
3 |
2500000 |
125923 |
|
4 |
2500000 |
125936 |
|
插入10000000條記錄所花費的總時間(秒) |
124.5 |
|
|
每條記錄所花費的時間(微秒) |
12.44838 |
|
|
每秒吞吐率(object/s) |
80331.77 |
|
四個執行緒更新10000000條記錄的總耗時為124.5秒,平均每條記錄耗時12.4微秒,每秒處理8萬條資料。
3.八執行緒
更新測試是通過八個執行緒,同時更新資料庫中記錄,共10000000次操作,每個執行緒的效能和總體效能如下:
|
執行緒ID |
記錄數 |
耗時(毫秒) |
|
1 |
1250000 |
130750 |
|
2 |
1250000 |
132481 |
|
3 |
1250000 |
137324 |
|
4 |
1250000 |
137781 |
|
5 |
1250000 |
139837 |
|
6 |
1250000 |
141223 |
|
7 |
1250000 |
141283 |
|
8 |
1250000 |
141357 |
|
更新10000000條記錄的耗時(秒) |
137.7545 |
|
|
更新每條記錄所的耗時(微秒) |
13.77545 |
|
|
每秒吞吐率(object/s) |
72593 |
|
可以看到8個併發同時更新10000000條記錄所花費的時間大概為138秒,平均每秒可以更新72593萬條記錄。此處的更新為涉及到了每條記錄的每個欄位。
4.總結
更新操作的總體吞吐率:
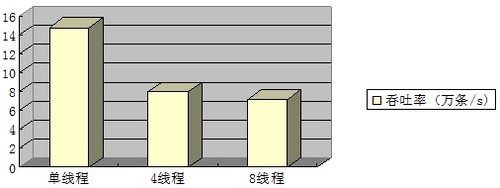
可以看到,更新操作的效能,同樣也是單個執行緒併發操作時,吞吐率最大。
查詢測試
1.單執行緒
首先進行單執行緒的查詢測試,在資料庫中進行10000000次查詢,效能如下:
|
執行緒ID |
記錄數 |
耗時(毫秒) |
|
1 |
10000000 |
36248 |
|
每條記錄所花費的時間(微秒) |
3.6248 |
|
|
每秒吞吐率(object/s) |
275877 |
|
單執行緒進行10000000次查詢的耗時為36.2秒,每次查詢花費時間為3.6微秒,每秒處理的運算元為27.6萬。
2.四執行緒
之後我們增加執行緒數為4.
四個執行緒進行10000000次查詢操作,效能如下:
|
執行緒ID |
記錄數 |
耗時(毫秒) |
|
1 |
2500000 |
71445 |
|
2 |
2500000 |
77419 |
|
3 |
2500000 |
79154 |
|
4 |
2500000 |
79806 |
|
插入10000000條記錄所花費的總時間(秒) |
76.956 |
|
|
每條記錄所花費的時間(微秒) |
7.6956 |
|
|
每秒吞吐率(object/s) |
129944.3838 |
|
四個執行緒進行10000000次查詢操作的總耗時為79.9秒,平均每條記錄耗時7.7微秒,每秒處理13萬次查詢操作。
3.八執行緒
查詢測試是通過八個執行緒,同時查詢資料庫中記錄,共10000000次查詢,每個執行緒的效能和總體效能如下:
|
執行緒ID |
記錄數 |
耗時(毫秒) |
|
1 |
1250000 |
77051 |
|
2 |
1250000 |
79457 |
|
3 |
1250000 |
81595 |
|
4 |
1250000 |
83005 |
|
5 |
1250000 |
83341 |
|
6 |
1250000 |
83752 |
相關推薦輕量級開源記憶體資料庫SQLite效能測試SQLite是一款輕型的資料庫,它佔用資源非常的低,同時能夠跟很多程式語言相結合,但是支援的SQL語句不會遜色於其他開源資料庫。它的設計目標是嵌入式的,而且目前已經在很多嵌入式產品中使用了它,它佔用資源非常的低,在嵌入式裝置中,可能只需要幾百K的記憶體就夠了。它能夠支援Windows/Lin H2:開源記憶體資料庫引擎本資源由 伯樂線上 - 劉立華 整理 H2是一個開源的記憶體資料庫。Java編寫、快速、小巧(1.5MB jar包)還提供了Web控制檯管理資料庫內容。 主要功能 非常快速的資料庫引擎。 開源。 Java編寫。 支援標準SQL、 大量資料情況下單執行緒插入和多執行緒insert資料庫的效能測試之前一直沒有遇到過大批量資料入庫的場景,所以一直沒有思考過在大量資料的情況下單執行緒插入和多執行緒插入的效能情況。今天在看一個專案原始碼的時候發現使用了多執行緒insert操作。 於是簡單的寫了一個測試程式來測試一批資料在N個執行緒下的insert情況。 public class ThreadImport 兩種開源聊天機器人的效能測試(一)——ChatterBot因為最近在學習自然語言處理的相關知識,QQ小冰這個東西最近又很熱,所以就試著玩了下兩個開源聊天機器人,在這裡分享一點小經驗,希望對有共同興趣的人能起到那麼一點作用。 我主要測試了兩個聊天機器人,一個是ChatterBot,另外一個是基於tensorf 通過sysbench工具實現MySQL資料庫的效能測試1.背景 sysbench是一款壓力測試工具,可以測試系統的硬體效能,也可以用來對資料庫進行基準測試。sysbench 支援的測試有CPU運算效能測試、記憶體分配及傳輸速度測試、磁碟IO效能測試、POSIX執行緒效能測試、互斥性測試測試、資料庫效能測試(OLTP基準測試)。目前支援的資料庫主要是 .NET Core之單元測試(二):使用記憶體資料庫處理單元測試中的資料庫依賴目錄 定義一個待測試API 測試用例 為減少篇幅,隱藏了SampleEntity和SqliteDbContext 定義一個待測試API 如下,我們定義了一個名為Sample的API,其中有一個外部依賴項Sqli JVM的堆記憶體洩漏排查-效能測試JVM異常說明 https://testerhome.com/articles/24259 一文中已介紹了,JVM每個執行時區域——程式計數器 、Java虛擬機器棧、本地方法棧、Java堆、方法區、直接記憶體發生OutOfMemoryError的不同原因和不同錯誤資訊。 Java堆,是執行緒共享記憶體,幾乎 記憶體資料庫fastdb的效能測試報告【從我原來blog搬來的】 IBM AIX 伺服器上 <一>利用SUBSQL介面手工進行測試 ----------<Some test Data>----------------------------------------- 1.Record(i 效能測試過程中oracle資料庫報ORA-27301 ORA-27302錯最近在效能測試過程中發現,發現虛擬使用者數上不去,載入到一定的數量應用端就報錯,提示連線資料庫出錯。在測試的過程中檢視web容器的執行緒池 資料來源的連線池 都還有空閒,同時檢視oracle的v$session檢視 發現session數到了一定數量就上不去了。檢視資料庫引數 process 設定的是1000 效能測試監控平臺:InfluxDB+Grafana+Jmeter linux環境執行jmeter並生成報告 時序資料庫InfluxDB:簡介及安裝 視覺化工具Grafana:簡介及安裝前面的部落格介紹了InfluxDB、Telegraf、Grafana的安裝和使用方法,這篇部落格,介紹下如何利用這些開源工具搭建效能測試監控平臺。。。 前言 效能測試工具jmeter自帶的監視器對效能測試結果的實時展示,在Windows系統下的GUI模式執行,渲染和效果不是太好,在linu 資料庫之redis篇(2)—— redis配置檔案,常用命令,效能測試工具redis配置 如果你是找網上的其他教程來完成以上操作的話,相信你見過有的啟動命令是這樣的: 啟動命令帶了這個引數:redis.windows.conf,由於我測試環境是windows平臺,所以是這個,有的是redis.conf。顧名思義,redis.conf就是配置檔案,然後啟動時加 基於Bloom-Filter演算法和記憶體資料庫的大量資料輕量級100%排重方案總體模組:一次排重模組(基於布隆演算法) + 二次排重方案(基於記憶體資料庫) 一次排重 //雜湊函式,返回型別為int型 //int型數的總數量[4294967296] (範圍大約在正負21億) //int型別4個位元組,32bits //排重標誌陣列的總長度[4294967296/(4* Emmagee——開源Android效能測試工具工具:Emmagee作者:孔慶雲 網易(杭州)質量保證部 開源地址:https://github.com/NetEase/Emmagee Wiki:https://github.com/NetEase/Emmagee/wiki 問題:https://github.com/NetEase/Emmag Odoo:全球第一免費開源ERP權威效能測試報告完整版(絕對珍藏)Odoo平臺簡介 Odoo(以前叫OpenERP)是世界排名第一的開源ERP系統,最早由比利時一家公司開發,經過十幾年發展,目前全世界Odoo的使用者超過2百萬人,Odoo被翻譯成幾十種語言,Odoo社群活躍的開發人員超過5000人。從2012年開始,美國著名IT雜誌Info 效能測試工具操作資料庫(九)-Loadrunner與MongoDB1、在loadrunner中新建指令碼(本文以LoadRunner11為例),要求選擇協議型別為Java->Java Vuser 2、在Run-time Settings設定JDK路徑,由於LoadRunner11不支援jdk1.8,本次測試是拷貝了一份低版本的JDK1.6,所以路徑選擇固 【Web效能測試】記憶體洩漏測試方法之chrome記憶體快照首先明確一下我們測試的目的:客戶端瀏覽器的js記憶體是否存在洩漏,伺服器端的話可不是這麼測,防止使用者使用時瀏覽器卡頓或崩潰。 F12開啟開發者工具,選中Memory頁簽下的Heap snapshot。 每次我們記錄快照前都要點選那個小垃圾桶,清一下快取,因為我們測記憶體洩漏是看 【資料庫效能測試實戰】測試不同分頁儲存過程在10w,100w以及1000w資料量下面的表現前言 資料庫的效能與每一行程式碼息息相關,所以,每次寫程式碼可以考慮一下在不同級別的資料量下面測試一下效能。 本文參考了: Postgresql生成大量測試資料 以及 準備測試用資料 此次測試我們將分別用10w,100w以及1000w級別的表來測試,下面先建立 OLTP系統REDIS資料庫效能測試紀錄為什麼想到用REDIS: 由於客戶追求較大大的併發交易極限,想盡可能提高資料庫承載足夠的壓力。所以選擇嘗試測試一下REDIS的效果。 測試構思: 1.對於OLTP系統,使用REDIS資料庫來快取交易資料庫(ORACLE)中長期不修改,或者修改頻率較低資料(引數) 效能測試-java記憶體溢位問題排查背景: 最近測試一個智慧呼叫系統,就是AI代替人工客服批量給客戶打電話作推廣活動,在測試的過程中,應用伺服器和資料庫伺服器資源使用都挺正常的,但是長久不重啟應用,過個2-3天,執行個幾次同時呼叫600個電話撥打任務後,就可能存在: org.springframework sqlserver資料庫效能測試第一步:在test plan 頁面新增JDBC驅動程式sqljdbc4.jar,在bin目錄下 第二步:新增一個執行緒組 第三步:右擊執行緒組,新增配置原件下的JDBC Connection Configuration,如下圖: 第四步:新增jdbc請求 右擊 |