
python實戰筆記之(5):使用Redis+Flask維護動態代理池
在做爬蟲的時候,可能會遇到IP被封的問題,利用代理就可以偽裝自己的IP進行爬蟲請求。在做爬蟲請求的時候需要很多代理IP,所以我們可以建立一個代理池,對代理池中的IP進行定期的檢查和更新,保證裡面所有的代理都是可用的。這裡我們使用Redis和Flask維護一個代理池,Redis主要用來提供代理池的佇列儲存,Flask是用來實現代理池的一個介面,用它可以從代理池中拿出一個代理,即通過web形式把代理返回過來,就可以拿到可用的代理了。
(1)為什麼要用代理池
- 許多網站有專門的反爬蟲措施,可能遇到封IP等問題。
- 網際網路上公開了大量免費代理,要利用好資源。
- 通過定時的檢測維護同樣可以得到多個可用代理。
(2)代理池的要求
- 多站抓取,非同步檢測
- 定時篩選,持續更新
- 提供介面,易於提取
(3)代理池架構
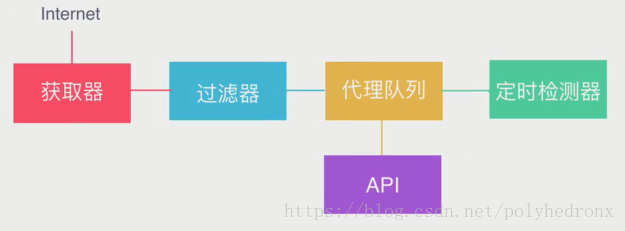
架構最核心的部分是“代理佇列”,我們要維護的就是這個佇列,裡面存了很多代理,佇列可以用python的資料結構來存,也可以用資料庫來存。維護好佇列我們需要做兩件事情:第一,就是向佇列裡新增一些可用的代理,獲取器從各大網站平臺上把代理抓取下來,臨時存到一個數據結構裡面,然後用過濾器對這些代理進行篩選。篩選的方法也很簡單,拿到代理之後,用它請求百度之類的網站,如果可以正常地請求網站,就說明代理可用,否則就將它剔除。過濾完之後將剩餘可用的代理放入代理佇列。第二,就是對代理佇列進行定時檢測,因為經過一段時間之後,代理佇列裡的部分代理可能已經失效,這就需要定時地從裡面拿出一些代理,重新進行檢測,保留可用的代理,剔除已經失效的代理。最後我們還需要做一個API,通過介面的形式拿到代理佇列裡面的一些代理。
(4)代理池實現
修改後的程式可以直接下載
各模組功能
-
getter.py
爬蟲模組
-
class proxypool.getter.FreeProxyGetter
爬蟲類,用於抓取代理源網站的代理,使用者可複寫和補充抓取規則。
-
-
schedule.py
排程器模組
-
class proxypool.schedule.ValidityTester
非同步檢測類,可以對給定的代理的可用性進行非同步檢測。
-
class proxypool.schedule.PoolAdder
代理新增器,用來觸發爬蟲模組,對代理池內的代理進行補充,代理池代理數達到閾值時停止工作。
-
class proxypool.schedule.Schedule
代理池啟動類,執行RUN函式時,會建立兩個程序,負責對代理池內容的增加和更新。
-
-
db.py
Redis資料庫連線模組
-
class proxypool.db.RedisClient
資料庫操作類,維持與Redis的連線和對資料庫的增刪查該,
-
-
error.py
異常模組
-
class proxypool.error.ResourceDepletionError
資源枯竭異常,如果從所有抓取網站都抓不到可用的代理資源,則丟擲此異常。
-
class proxypool.error.PoolEmptyError
代理池空異常,如果代理池長時間為空,則丟擲此異常。
-
-
api.py
API模組,啟動一個Web伺服器,使用Flask實現,對外提供代理的獲取功能。
-
utils.py
工具箱
-
setting.py
設定
使用示例
import os
import sys
import requests
from bs4 import BeautifulSoup
dir = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
sys.path.insert(0, dir)
def get_proxy():
r = requests.get('http://127.0.0.1:5000/get')
proxy = BeautifulSoup(r.text, "lxml").get_text()
return proxy
def crawl(url, proxy):
proxies = {'http': proxy}
r = requests.get(url, proxies=proxies)
return r.text
def main():
proxy = get_proxy()
html = crawl('http://docs.jinkan.org/docs/flask/', proxy)
print(html)
if __name__ == '__main__':
main()
Last but not least:
如果程式執行過程中出現錯誤,很有可能是部分代理網站發生了變化,但“getter.py”檔案裡請求代理網站程式沒有更新導致的。比如有的代理網站不再能夠訪問,或網站不能正常請求,返回503之類的錯誤,就需要對程式作出更改,或者直接去掉不能正常訪問的網站,重新找一些新的可用的代理網站加進去。
另外,這套程式還有一個不足之處,就是代理池中的代理IP很有可能是重複的,而且重複率會隨著執行時間的增加而提高。要解決這個問題,一個是可以增加代理網站的數量,使代理池中的代理有更豐富的來源,此外,還可以在向代理池中增加新的代理時進行重複性檢查,如果代理池中已經有該代理IP,則放棄存入代理池。
更新(2018/8/9/01:20):
針對代理池中的代理IP可能會重複的問題,提出了一種解決方法,實測可行。
代理IP之所以會重複,和Redis資料庫使用的資料結構有很大關係,原程式使用的是列表(list)結構,資料以列表形式存入資料庫後是有序但允許重複的,當有新的資料存入時,並不會對資料的重複性進行檢查和處理。但Redis不僅有列表結構,常見的Redis資料結構有String、Hash、List、Set(集合)和Sorted Set(有序集合),使用Set和Sorted Set結構就不會出現重複元素。
Set是無序集合,元素無序排列,當有重複元素存入時,資料庫是不會發生變化的;Sorted Set是有序集合,有序集合是可排序的,但是它和列表使用索引下標進行排序依據不同的是,它給每個元素設定一個分數(score)作為排序的依據,當存入一個元素時,同時需要存入該元素的分數。
Sorted Set使用起來較複雜,主要是分數分配問題比較難搞,所以這裡使用Set代替原程式中的List作為資料庫的資料結構,將以下內容代替原來的“db.py”檔案中的內容即可:
# db.py
import redis
from proxypool.error import PoolEmptyError
from proxypool.setting import HOST, PORT, PASSWORD
class RedisClient(object):
def __init__(self, host=HOST, port=PORT):
if PASSWORD:
self._db = redis.Redis(host=host, port=port, password=PASSWORD)
else:
self._db = redis.Redis(host=host, port=port)
def get(self, count=1):
"""
get proxies from redis
"""
proxies = []
for i in range(count):
proxies.append(self._db.spop("proxies"))
return proxies
def put(self, proxy):
"""
add proxy to right top
"""
self._db.sadd("proxies", proxy)
def pop(self):
"""
get proxy from right.
"""
try:
return self._db.spop("proxies").decode('utf-8')
except:
raise PoolEmptyError
@property
def queue_len(self):
"""
get length from queue.
"""
return self._db.scard("proxies")
def flush(self):
"""
flush db
"""
self._db.flushall()
if __name__ == '__main__':
conn = RedisClient()
print(conn.pop())
將資料結構改為Set以後,便不會出現代理池中代理IP重複的問題,但這樣做也是有弊端的,因為Set是無序的,所以更新代理池的過程中每次彈出的代理IP也是隨機的,這樣代理池中的某些代理可能永遠也不會被更新,而我們獲取代理時採用pop方法得到的也是代理池中隨機彈出的代理,該代理有可能是很久沒有被更新的已經失效的代理。
總結一下就是使用Set結構可以保證代理池中的代理不會重複,但不能保證呼叫代理池獲取代理時得到的代理是最新的和可用的,而List結構可以保證當前獲取的代理是最新的,但代理池中的代理可能會有很大的重複。總之,兩種方法都是有利有弊的,當然也可以嘗試用有序集合(Sorted Set)構建一種完美的方法了。
參考內容: