
逆向分析學習入門教程
前沿
從本篇起,逆向工廠帶大家從程式起源講起,領略計算機程式逆向技術,瞭解程式的執行機制,逆向通用技術手段和軟體保護技術,更加深入地去探索逆向的魅力。
一、程式如何誕生?

1951年4月開始在英國牛津郡哈維爾原子能研究基地正式投入使用的英國數字計算機“哈維爾·德卡特倫”,是當時世界上僅有的十幾臺電腦之一。圖中兩人手持的“紙帶”即是早期的程式,紙帶通過是否穿孔記錄1或0,而這些正好對應電子器件的開關狀態,這便是機器碼,是一種早期計算機程式的儲存形式。

計算機程式是用來實現某特定目標功能,所以需要將人類思維轉換為計算機可識別的語言,從人類語言到電子器件開關的閉合,這中間的媒介便是“程式語言”。
“程式語言”大致分為三類:
1、機器語言,又稱機器碼、原生碼,電腦CPU可直接解讀,因該語言與執行平臺密切相關,故通用性很差,上面提到的利用卡帶記錄的便屬於該類語言;
2、組合語言,是一種用於電子計算機、微處理器、微控制器或其他可程式設計器件的低階語言,亦稱為符號語言。在不同的裝置中,組合語言對應著不同的機器語言指令集, 執行時按照裝置對應的機器碼指令進行轉換,所以組合語言可移植性也較差;

3、高階語言,與前兩種語言相比,該類語言高度抽象封裝,語法結構更接近人類語言,邏輯也與人類思維邏輯相似,因此具有較高的可讀性和程式設計效率。但是高階語言與組合語言相比,因編譯生成的輔助程式碼較多,使執行速度相對“較慢”。 java,c,c++,C#,pascal,python,lisp,prolog,FoxPro,易語言等等 均屬於高階語言。
學會程式語言各種基本語義語法後,就可以實戰了,而實戰場所由IDE提供。IDE(整合開發環境Integrated Development Environment)是用於提供程式開發環境的應用程式,目前IDE的種類繁多,不再敖述,只要自己用得順手、開發效率高、你開心就好。
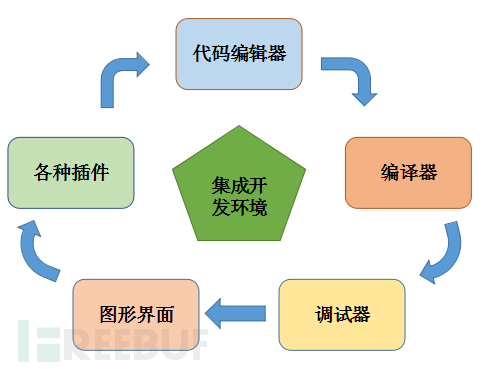
通過IDE可快速生成程式,根據程式的生成和執行過程,程式大致可分為兩類:編譯型程式和解釋型程式。
編譯型程式:程式在執行前編譯成機器語言檔案,執行時不需要重新翻譯,直接供機器執行,該類程式執行效率高,依賴編譯器,跨平臺性差,如C、C++、Delphi等;
解釋型程式:程式在用程式語言編寫後,不需要編譯,以文字方式儲存原始程式碼,在執行時,通過對應的直譯器解釋成機器碼後再執行,如Basic語言,執行時逐條讀取解釋每個語句,然後再執行。由此可見解釋型語言每執行一句就要翻譯一次,效率比較低,但是相比較編譯型程式來說,優勢在於跨平臺性好。
Q : Java屬於編譯型語言OR解釋型語言?
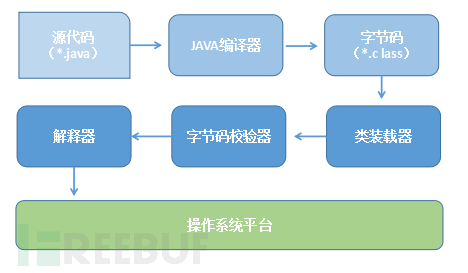
Java首先將原始碼通過編譯器編譯成.class型別檔案(位元組碼),這是java自定義的一種型別,只能由JAVA虛擬機器(JVM)識別。程式執行時JVM從.class檔案中讀一行解釋執行一行。另外JAVA為實現跨平臺,不同作業系統對應不同的JVM。從這個過程來看JAVA程式前半部分經過了編譯,而後半部分又經過解析才能執行,可以說是一種混合型程式,由於該類程式執行依賴虛擬機器,一些地方稱其為“虛擬機器語言”。下圖展現各語言之間關係。
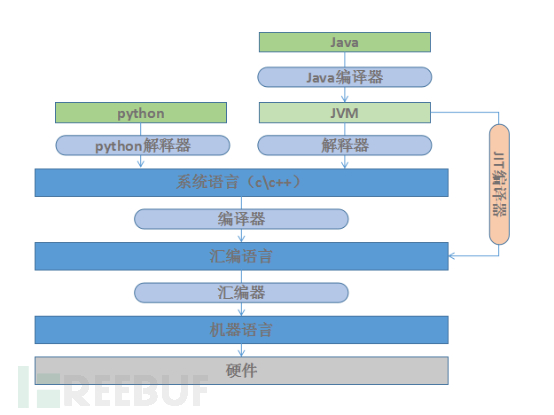
硬體->機器語言->組合語言->系統語言(C和C++)->解釋型語言(python)和虛擬機器語言(java),語言的封裝程度越來越高,也更加抽象,貼近於人類思維,即“造車前不用再考慮車輪怎麼造”。同時,層次越高意味著程式在執行時經歷的轉化步驟越多,畢竟都要轉換為機器語言才能被硬體直接執行,這也是一些高階語言無法應用在效率要求較苛刻場景的原因之一。
Java為了對執行效率進行優化,提出“JIT (Just-In-Time Compiliation)”優化技術,中文為“即時編譯”。JVM會分析Java應用程式的函式呼叫並且達到內部一些閥值後將這些函式編譯為本地更高效的機器碼,當執行中遇到這類函式,直接執行編譯好的機器碼,從而避免頻繁翻譯執行的耗時。
重點看看C\C++語言生成程式的過程及程式是以怎樣的形態儲存。
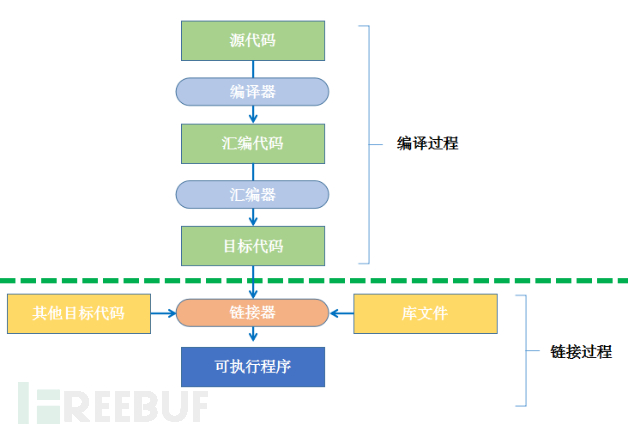
上圖為c語言程式的生成過程,主要經過編譯、連結兩大過程。
編譯是指編譯器將原始碼進行詞法和語法的分析,將高階語言指令轉換為彙編程式碼。主要包含3個步驟:
1、預處理。正式編譯前,根據已放置在檔案中的預處理指令來修改原始檔的內容,包含巨集定義指令,條件編譯指令,標頭檔案包含指令,特殊符號替換等。
2、編譯、優化。編譯程式通過詞法分析和語法分析,將其翻譯成等價的中間程式碼表示或彙編程式碼。
3、目的碼生成。將上面生成的彙編程式碼譯成目標機器指令的過程。目標檔案中所存放著與源程式等效的目標的機器語言程式碼。
連結是指將有關的目標檔案彼此相連線生成可載入、可執行的目標檔案,其核心工作是符號表解析和重定位。連結按照工作模式分靜態和動態連結兩類。
靜態連結:連結器將函式的程式碼從其所在地(目標檔案或靜態連結庫中)拷貝到最終的可執行程式中,整個過程在程式生成時完成。靜態連結庫實際上是一個目標檔案的集合,其中的每個檔案含有庫中的一個或者一組相關函式的程式碼,靜態連結則是把相關程式碼拷貝到原始碼相關位置處參與程式的生成。
動態連結:動態連結庫在編譯連結時只提供符號表和其他少量資訊用於保證所有符號引用都有定義,保證編譯順利通過。程式執行時,動態連結庫的全部內容將被對映到執行時相應程序的虛地址空間,根據可執行程式中記錄的資訊找到相應的函式地址並呼叫執行。
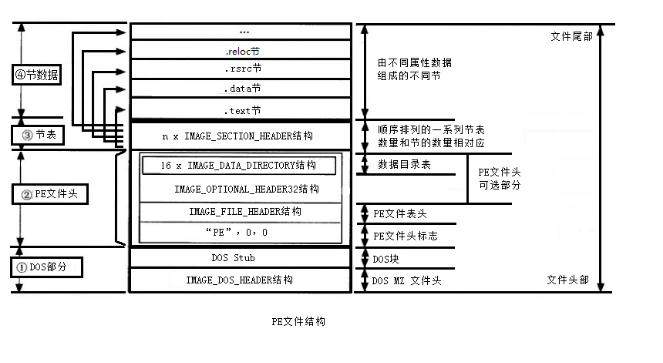
經過編譯連結後,程式生成,windows程式則都已PE檔案形式儲存。
PE檔案全稱Portable Executable,意為可移植可執行檔案,常見的EXE、DLL、OCX、SYS、COM都是PE檔案。 PE檔案以段的形式儲存程式碼和相關資源資料,其中資料段和程式碼段是必不可少的兩個段。
Windows NT 預定義的段分別為
.text、.bss、.rdata、.data、.rsrc、.edata、.idata、.pdata和.debug。這些段並不是都是必須的,另外也可以根據需要定義更多的段,常見的一些加殼程式則擁有自己命名的段。
在應用程式中最常出現的段有以下6種:
1、執行程式碼段,.text命名;
2、資料段,.data、.rdata 命名;
3、資源段,.rsrc命名;
4、匯出表,.edata命名;
5、匯入表,.idata命名;
6、除錯資訊段,.debug命名。
下圖為一個標準的PE檔案結構。
[NOTE]
到此為止,程式就誕生了,如果你對檔案形態足夠了解,就完全可以向網上的某些大牛一樣,純手工打造一個PE檔案。
二、程式如何執行
程式誕生後,我們就可以運行了,也就是雙擊程式後的事兒(本節重點描述windows平臺程式)。需要說明的是,上面產生的程式檔案是儲存在硬碟(外存)裡的二進位制資料,當你雙擊程式後,windows系統會根據字尾名進行登錄檔查詢相應的啟動程式,這裡我們編譯出的是以exe字尾的可執行程式,則系統對程式進行執行。
Q:系統如何執行可執行程式?
系統並非在硬碟上直接執行程式,而是將其裝載進記憶體裡,包括其中的程式碼段、資料段等。
Q:為什麼在這會多此一舉,把程式複製到記憶體再執行呢?
記憶體直接由CPU控制,享受與CPU通訊的最優頻寬,然而硬碟是通過主機板上的橋接晶片與CPU相連,所以速度比較慢。再加上傳統機械式硬碟靠電機帶動碟片轉動來讀寫資料,磁頭尋道等機械操作耗費時間,而記憶體條通過電路來讀寫資料,顯然電機的轉速肯定沒有電的傳輸速度快。後來的固態硬碟則大大提升了讀寫速度,但是由於控制方式依舊不同於記憶體,讀寫速度任然慢於記憶體。
為了程式執行速率,任何程式在執行時,都是有一個叫做“裝載器”的程式先將硬碟上的資料複製到記憶體,然後才讓CPU來處理,這個過程就是程式的裝載。裝載器根據程式的PE頭中的各種資訊,進行堆疊的申請和程式碼資料的對映裝載,在完成所有的初始化工作後,程式從入口點地址進入,開始執行程式碼段的第一條指令。
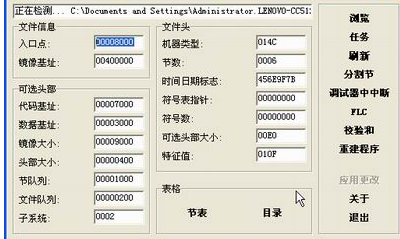
程式從入口點開始順序執行,CPU直接與記憶體中的程式打交道,讀取記憶體中的資料進行處理,並將結果儲存到記憶體,除非程式碼段中還有儲存資料到硬碟的程式碼,否則程式全程都不會在硬碟中儲存任何資料。這就好比我們開啟文件編輯器去編譯文件,不管輸入多少內容,在我們點選“儲存”前,硬碟上的程式檔案都沒有變動,輸入的資料都只是儲存在記憶體上,如果此時很不幸斷電了,記憶體上的資料會立刻丟失。為了應對這種尷尬局面,一些編輯軟體會定期自動儲存新資料至硬碟上,以防意外丟失資料的情況發生。
既然程式在執行時需要載入到記憶體中才能執行,那麼問題來了,對於目前體積越來越龐大的遊戲來說,豈不是要把40~50G(可見使命召喚系列)的資料全塞進記憶體裡。在某貓上搜索某品牌電腦,按價格排序後,某款3w RMB的移動工作站的記憶體也只是32G,這顯然不滿足一下子裝載一款遊戲的需求。而檢視該遊戲的執行配置需求,記憶體需求也只是幾個G而已,這是怎麼回事呢?
原來,作業系統為解決此問題:當程式執行需要的空間大於記憶體容量時,會將記憶體中暫時不用的資料寫回硬碟;需要時再從硬碟中讀取,並將另外一部分不用的資料寫入硬碟。這樣,硬碟中部分空間會用於儲存記憶體中暫時不用的資料,這一部分空間就叫做虛擬記憶體(Virtual Memory)。其中記憶體交換、記憶體管理等詳細過程,感興趣的同學可以查閱作業系統相關書籍。

一些同學看到這,就單純的認為,調整虛擬記憶體空間即可變向提高記憶體空間,從而提升執行速度。硬碟的讀寫速度遠遠慢於記憶體,所以虛擬記憶體和記憶體頻繁進行資料交換會浪費很多時間,嚴重影響計算機的執行速度。所以同學們還是要努力學習,早日當上高富帥白富美,換高配置電腦吧。
三、逆向目的和原理
簡要了解計算機程式基礎知識後,我們進入【逆向工廠】的正題——逆向。
Q:為什麼要逆向?
1、破解正版軟體的授權
由於一些軟體採用商業化運營模式,並不開源,同時需要付費使用。為此這些軟體採用各種保護技術對使用做了限制,而一些想享受免費的童鞋則對這些保護技術發起進攻,其中的主要技術便是逆向,通過逆向梳理出保護技術的執行機制,從而尋找突破口。
2、挑戰自我、學習提高
crackme是一些公開給別人嘗試破解的小程式,製作 crackme 的人可能是程式設計師,想測試一下自己的軟體保護技術,也可能是一位 cracker,想挑戰一下其它 cracker 的破解實力,也可能是一些正在學習破解的人,自己編一些小程式給自己破,不管是什麼目的,都是通過crackme提高了自身能力。另外, 一些網際網路安全公司也會在面試中採取這種形式對應聘者進行測試。
3、挖掘漏洞與安全性檢測
一些安全性要求較高的行業,為確保所用軟體的安全,而又無法獲取原始碼時,也需逆向還原軟體的執行過程,確保軟體的安全可靠。另外,挖洞高手在挖掘漏洞時,經常採用逆向手段,尋找可能存在的溢位點。病毒分析師通過逆向,分析病毒的執行機制,提取特徵。
4、還原非開源專案
當你想模仿某優秀軟體實現某功能時,發現該軟體並未開源,而又很難從其他渠道獲取該軟體的具體技術細節,那麼逆向也許會幫你敲開思想的大門。
Q:既然逆向這麼神通廣大,可以解決很多問題,那麼它的原理機制是什麼?
“逆向”顧名思義,就是與將原始碼變為可執行程式的順序相反,將編譯連結好的程式反過來恢復成“程式碼級別”。這裡之所以用到“程式碼級別”一詞,是因原始碼編譯是“不可逆”過程,無法從編譯後的程式逆推出原始碼。
“逆向”通常通過工具軟體對程式進行反編譯,將二進位制程式反編譯成彙編程式碼,甚至可以將一些程式恢復成更為高階的虛擬碼狀態。C\C++程式在經過編譯連結後,程式為機器碼,直接可供CPU使用,對於這類程式我們使用IDA、OD等逆向程式,只能將其恢復成彙編程式碼狀態,然後通過讀彙編程式碼來解讀程式的執行過程機制,顯然這對於新手來說,直接閱讀彙編程式碼門檻較高,所以一些逆向工具提供外掛可以將一些函式恢復成虛擬碼級別。
相比C\C++這一類編譯執行類程式,依靠java虛擬機器、.NET等執行的程式,由於所生成的位元組碼(供虛擬機器解釋執行)仍然具有高度抽象性,所以對這類程式的逆向得到的虛擬碼可讀性更強,有時甚至接近與原始碼。但是在生成位元組碼的過程中,變數名、函式名是丟失的,所以逆向出的虛擬碼中這些名稱也是隨機命名的,從而給程式碼的閱讀製造的一定障礙。而對於這類易反編譯的程式,為了保護軟體不被逆向,通常採用程式碼混淆技術,打亂其中的命名,加入干擾程式碼來設定各種障礙。
至此,我們把程式恢復成了可讀程式碼,如果你僅僅依靠閱讀這些程式碼來梳理程式執行過程,這叫做“靜態除錯”。與此對應的“動態除錯”則是讓程式執行起來,更加直觀的觀察程式的執行過程。經常編寫程式的同學在debug時常常用到“斷點”,而在動態除錯中,斷點起著很大的作用,否則程式將不會暫停下來讓你慢慢觀察各暫存器狀態。
Q:“斷點”是如何工作的?
x86系列處理器從8086開始就提供了一條專門用來支援除錯的指令,即INT 3。簡單地說,這條指令的目的就是使CPU中斷(break)到偵錯程式,以供除錯者對執行現場進行各種分析。我們可以在想要觀察的指令處設定一個斷點,則程式會執行到該處後自動停下來;“單步除錯”則是每條語句後面都會有INT3指令來阻斷程式的執行,而這些INT3是對使用者透明的,逆向工具並未將這些指令顯示出來。
四、反彙編的多樣性
現在大多數程式是利用高階語言如C,C++,Delphi等進行編寫 ,然後再經過編譯連結,生成可被計算機系統直接執行的檔案。不同的作業系統,不同的程式語言,反彙編出的程式碼大相庭徑。反彙編工具如何選擇?彙編程式碼如何分析?如何除錯修改程式碼?這些問題都會讓剛入門的新童鞋困惑。
下面我們簡單對比c++和c#程式反彙編後得到的程式碼:
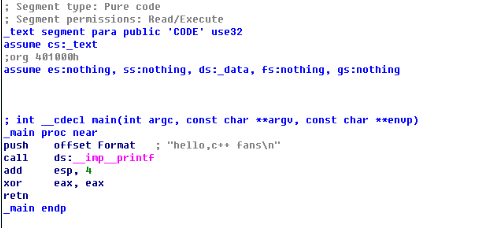
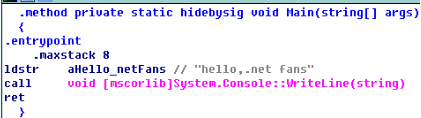
圖1是c++程式反彙編結果,圖2為.net程式反彙編結果,兩者功能都只是列印一句話。C++以push指令將字串壓入棧中,而.net以ldstr指令將字串壓入棧中,呼叫列印函式結束後,.net反彙編程式碼直接以ret指令返回結束,而c++反彙編程式碼先平衡完棧,再執行retn指令返回結束。
由此可見,在反彙編過程中,我們確認好程式的編寫語言和執行環境,才可選擇適當的工具來反彙編程式。在分析反彙編程式碼時,如果熟悉高階語言的開發、執行過程及其反彙編指令,那更是事半功倍。
五、常用的軟體分析工具
對於軟體逆向分析,分為靜態分析和動態分析,常用的軟體如下:
靜態分析工具
IDA Pro(Interactive Disassembler Professional )
IDA Pro是總部位於比利時列日市(Liège)的Hex-Rayd公司的一款產品。IDA 的主要目標之一,在於呈現儘可能接近原始碼的程式碼,而且通過派生的變數和函式名稱來盡其所能地註釋生成的反彙編程式碼,適用於三大主流操作 系統:Microsoft Windows.Mac OS X 和 Linux。IDA Pro提供了許多強大功能,例如函式的交叉引用檢視、函式執行流程圖及虛擬碼等,並且也有一定的動態除錯功能。同時,IDA pro可以在windows、linux、ios下進行二進位制程式的動態除錯和動態附加,支援檢視程式執行記憶體空間,設定記憶體斷點和硬體斷點。
IDA Pro是許多軟體安全專家和黑客所青睞的“神兵利器”。
c32asm
c32asm 是款非常好用的反彙編程式,具有反彙編模式和十六進位制編輯模式,能跟蹤exe檔案的斷點,也可直接修改軟體內部程式碼 ,提供輸入表、輸出表、參考字元、跳轉、呼叫、PE檔案分析結果等顯示 ,提供彙編語句逐位元組分析功能,有助於分析花指令等干擾程式碼。
Win32Dasm
Win32dasm可以將應用程式靜態反編譯為WIN 32彙編程式碼,利用Win32dasm我們可以對程式進行靜態分析,幫助快速找到程式的破解突破口。筆者下載的 Win32Dasm還可以附加到正在執行的程序,對程序進行動態除錯,但如果原程式經過了加密變換處理或著是被EXE壓縮工具壓縮過,那麼用Win32dasm對程式進行反彙編就沒有任何意義了。
VB Decompiler pro
VB Decompiler pro是一個用來反編譯VB編寫的程式的工具。VB Decompiler反編譯成功後,能夠修改VB窗體的屬性,檢視函式過程等 ,VB Decompiler Pro 能反編譯Visual Basic 5.0/6.0的p-code形式的EXE, DLL 或 OCX檔案。對native code形式的EXE, DLL或OCX檔案,VB Decompiler Pro 也能給出反編譯線索。
還有對.net程式和delphi程式的靜態反彙編分析工具,在以後的章節中會使用到,到時再詳細講解。
動態分析工具
Ollydbg
Ollydbg執行在windows平臺上,是 Ring 3級偵錯程式,可以對程式進行動態除錯和附加除錯,支援對執行緒的除錯同時還支援外掛擴充套件功能, 它會分析函式過程、迴圈語句、選擇語句、表[tables]、常量、程式碼中的字串、欺騙性指令、API呼叫、函式中引數的數目,import表等等 ;支援除錯標準動態連結庫(Dlls),目前已知 OllyDbg 可以識別 2300 多個 C 和 Windows API 中的常用函式及其使用的引數,是 Ring3級功能最強大的一款動態除錯工具。
Windbg
Windbg是Microsoft公司免費偵錯程式除錯集合中的GUI的偵錯程式,支援Source和Assembly兩種模式的除錯。Windbg不僅可以除錯應用程式,還可以 對核心進行除錯。結合Microsoft的Symbol Server,可以獲取系統符號檔案,便於應用程式和核心的除錯。Windbg支援的平臺包括X86、IA64、AMD64。Windbg 安裝空間小,具有圖形操作介面,但其最強大的地方是有豐富的除錯指令。
其它對.net,delphi等程式的動態除錯工具在以後的章節中介紹。
輔助工具
系統監視工具:
Wireshark (免費軟體,網路監視和包分析類軟體)
Outpost Firewall (共享軟體,使用hook技術的Windows防火牆)
ProcExp (免費軟體,強大的程序分析軟體)
FileMon (免費軟體,強大的檔案讀寫監視軟體)
RegMon (免費軟體,強大的登錄檔讀寫監視軟體)
反保護工具:
LordPE (Win32 PE檔案修改,轉存工具)
ImportREC (Win32 PE檔案結構修復軟體)
AIl versions ASPack unpacker (免費軟體,ASPack壓縮殼脫殼工具)
UnPECompact(免費軟體,PECompact壓縮殼脫殼工具)
UPX(自由軟體,UPX壓縮殼加殼和脫殼工具)
其它:
Hedit (共享軟體,16進位制編輯器)
PEiD (免費較件,軟體資訊和編寫語言分析工具)
以上只是常用的一些程式分析工具,還有很多工具這裡沒有提到,有興趣的讀者可以根據自身需求查詢下載。
六、從hello world說起
為了讓大家直觀地瞭解逆向的過程,我們就從大家最初學習程式設計時的hello world程式開始講解:
#include <stdio.h>
void main()
{
printf("hello world!\n");
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
這是我們編寫的列印hello world程式,是不是看起來很親切,接下來將編譯好的hello
world程式用IDA反彙編,生成的程式碼如下圖:
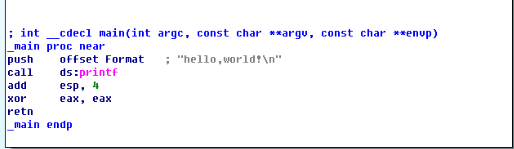
第一行main函式名前面的__cdecl,是C Declaration的縮寫(declaration,宣告),表示C語言預設的函式呼叫方法:所有引數從右到左依次入棧,這些引數由呼叫者清除 。還有__fastcall與__stdcall,三者都是呼叫約定(Calling convention),它決定以下內容:
1、函式引數的壓棧順序
2、由呼叫者還是被呼叫者把引數彈出棧
3、產生函式修飾名的方法
push offset Format是將引數壓入棧,在這裡就是講要列印的“hello world!\n”壓入棧,供printf函式使用,在反彙編程式程式碼中,如果呼叫的函式有引數,都是先將函式的引數先用push指令壓入棧中,例如:add(int a,int b),呼叫add函式前,先將引數a和b壓入棧,根據 __cdecl呼叫規則,先push b,再push a,最後再呼叫add函式。
call ds:printf就是呼叫printf函式列印“hello world“字元。
add esp, 4是平衡棧,平衡掉剛才壓入的函式引數。
xor eax, eax將eax暫存器清零。
retn 返回,程式執行結束。
這就是hello world程式的逆向程式碼分析,只是舉一個簡單的例子,真正要逆向分析一個較大較複雜的程式還是有一定難度,需要更多的知識與經驗。
七、Crackme
crackme(通常簡稱CM)是用來測試程式設計人員的逆向工程技能的小程式。
KeygenMe、ReverseMe、UnpackMe,KeygenMe是要求別人做出程式對應的 keygen (序號產生器)。
ReverseMe 要求別人把它的演算法做出逆向分析。
UnpackMe 是則是要求別人把它成功脫殼 。
分析這些程式都能提高個人的程式分析能力,這些程式都有各自側重的知識點。
下面就以一個驗證序列號的crackme小程式作為例子進行破解,得到正確的序列號。
直接執行程式是這樣的
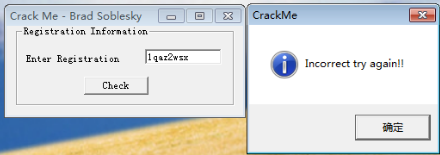
開始破解程式,首先用IDA開啟檔案
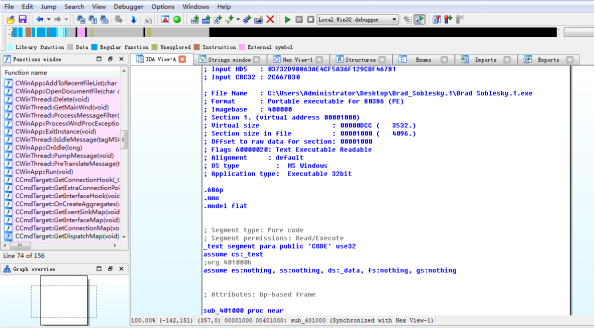
在函式(Function name)視窗中看見CWinApp,CCmdTarget更類,熟悉的同學已經知道該程式使用MFC編寫,結合自己的開發經驗,就能猜到獲取編輯框中的內容用的函式是GetDlgItemText(),定位到呼叫該函式的位置0×00401557。在之前有三個指令,
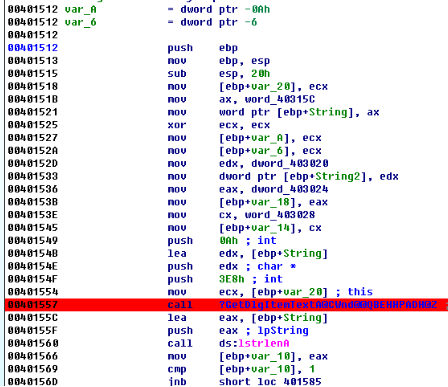
在呼叫GetDlgItemText()之前有三個push指令,
.text:00401549 push 0Ah ; int //字串最大長度
.text:0040154B lea edx, [ebp+String]
.text:0040154E push edx ; char * //字串快取區
.text:0040154F push 3E8h ; int //指向輸入框控制元件
.text:00401554 mov ecx, [ebp+var_20] ;
注意到剛才彈框的提示內容“Incorrect try again!!”,可以在IDA字串視窗中找到,定位到使用該字串的位置
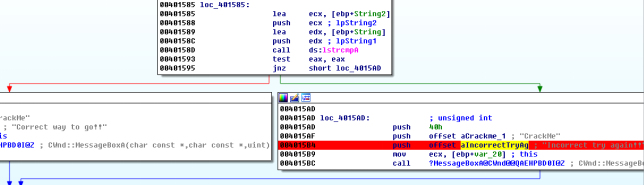
細心的同學已經發現了,在上面loc_401585程式碼段處有字串比較(lstrcmpA),比較完成後有兩個分支,一個提示輸入正確“Correct way to go!!”,另一個提示輸入錯誤 “Incorrect try again!!”,結合上面獲取文字輸入框內容的程式碼段資訊可以判斷,lpString2和lpString1中有一個儲存正確的驗證碼,另一個儲存輸入的內容,接下來我們用兩種方法讓我們的驗證碼通過驗證。
獲取正確的驗證碼
在0040158D call ds:lstrcmpA處設定斷點,點選Debugger->Start Process或按F9開始動態除錯,在程式輸入框中隨便輸入一串字元,實驗中輸入的是‘1qaz2wsx’,然後點選“Check”控制元件,程式停在我們設定的斷點處,然後檢視暫存器ecx和edx中的值,所示如下:

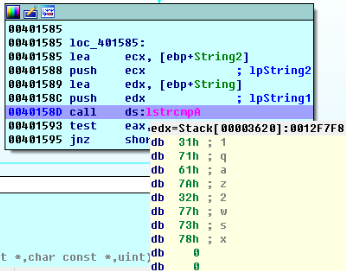
如圖所示,ecx暫存器存放的是lpString2:‘’,edx暫存器存放的是lpString1:‘1qaz2wsx’,獲得正確驗證碼”’”’,接下來在程式中試驗一下:
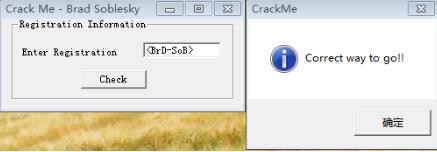
結果正確!
修改二進位制程式碼
修改PE檔案,使輸入的內容顯示正確。在上一小節,程式比較完lpString1和lpString2有兩個分支,一個是正確輸入的提示框,另一個是錯誤輸入提示框。修改程式碼跳轉,只要跳轉到彈出“Correct way to go!!”程式碼段就可以了,結合程式碼,當兩個字串不同時會執行jnz short loc_4015AD指令,跳轉到loc_4015AD程式碼段,將jnz指令改為jz,可在兩個字串不同時跳轉到“Correct way to go!!”程式碼段。jnz的十六進位制碼為75,jz的十六進位制碼為74,只需將可執行程式中的75改為74就可以。
通過IDA Pro檢視十六進位制檔案視窗找到該跳轉指令

用Hedit開啟程式,找到該跳轉指令

在二進位制的檔案中該跳轉指令在0×00001595處,而不是IDA顯示的0×00401595,發生了什麼?這涉及到PE檔案記憶體對映方面的基礎知識,童鞋們可查閱相關資料。
將跳轉指令75修改為74,儲存修改後執行,隨意輸入一段字串看執行結果: 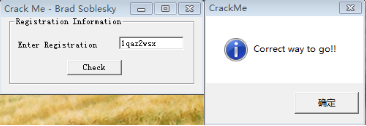
結果正確!那麼,如果輸入原來程式的驗證碼‘’,結果會是什麼?為什麼會是這樣?
REFERENCE
1. 逆向工廠(一):從hello world開始
2. 逆向工廠(二):靜態分析技術