
R----stringr包介紹學習
1. stringr介紹
stringr包被定義為一致的、簡單易用的字串工具集。所有的函式和引數定義都具有一致性,比如,用相同的方法進行NA處理和0長度的向量處理。
字串處理雖然不是R語言中最主要的功能,卻也是必不可少的,資料清洗、視覺化等的操作都會用到。對於R語言本身的base包提供的字串基礎函式,隨著時間的積累,已經變得很多地方不一致,不規範的命名,不標準的引數定義,很難看一眼就上手使用。字串處理在其他語言中都是非常方便的事情,R語言在這方面確實落後了。stringr包就是為了解決這個問題,讓字串處理變得簡單易用,提供友好的字串操作介面。
2. stringr的API介紹
stringr包1.0.0版本,一共提供了30個函式,方便我們對字串處理。常用的字串的處理以str_開頭來命名,方便更直觀理解函式的定義
字串拼接函式
- str_c: 字串拼接。
- str_join: 字串拼接,同str_c。
- str_trim: 去掉字串的空格和TAB(\t)
- str_pad: 補充字串的長度
- str_dup: 複製字串
- str_wrap: 控制字串輸出格式
- str_sub: 擷取字串
- str_sub<- 擷取字串,並賦值,同str_sub
字串計算函式
- str_count: 字串計數
- str_length: 字串長度
- str_sort: 字串值排序
- str_order: 字串索引排序,規則同str_sort
字串匹配函式
- str_split: 字串分割
- str_split_fixed: 字串分割,同str_split
- str_subset: 返回匹配的字串
- word: 從文字中提取單詞
- str_detect: 檢查匹配字串的字元
- str_match: 從字串中提取匹配組。
- str_match_all: 從字串中提取匹配組,同str_match
- str_replace: 字串替換
- str_replace_all: 字串替換,同str_replace
- str_replace_na:把NA替換為NA字串
- str_locate: 找到匹配的字串的位置。
- str_locate_all: 找到匹配的字串的位置,同str_locate
- str_extract: 從字串中提取匹配字元
- str_extract_all: 從字串中提取匹配字元,同str_extract
字串變換函式
- str_conv: 字元編碼轉換
- str_to_upper: 字串轉成大寫
- str_to_lower: 字串轉成小寫,規則同str_to_upper
- str_to_title: 字串轉成首字母大寫,規則同str_to_upper
引數控制函式,僅用於構造功能的引數,不能獨立使用。
- boundary: 定義使用邊界
- coll: 定義字串標準排序規則。
- fixed: 定義用於匹配的字元,包括正則表示式中的轉義符
- regex: 定義正則表示式
stringr包中的重要函式
| 函式 | 功能說明 | R Base中對應函式 |
|---|---|---|
| 使用正則表示式的函式 | ||
str_extract() | 提取首個匹配模式的字元 | regmatches() |
str_extract_all() | 提取所有匹配模式的字元 | regmatches() |
str_locate() | 返回首個匹配模式的字元的位置 | regexpr() |
str_locate_all() | 返回所有匹配模式的字元的位置 | gregexpr() |
str_replace() | 替換首個匹配模式 | sub() |
str_replace_all() | 替換所有匹配模式 | gsub() |
str_split() | 按照模式分割字串 | strsplit() |
str_split_fixed() | 按照模式將字串分割成指定個數 | - |
str_detect() | 檢測字元是否存在某些指定模式 | grepl() |
str_count() | 返回指定模式出現的次數 | - |
| 其他重要函式 | ||
str_sub() | 提取指定位置的字元 | regmatches() |
str_dup() | 丟棄指定位置的字元 | - |
str_length() | 返回字元的長度 | nchar() |
str_pad() | 填補字元 | - |
str_trim() | 丟棄填充,如去掉字元前後的空格 | - |
str_c() | 連線字元 | paste(),paste0() |
3.1 字串拼接函式
3.1.1 str_c,字串拼接操作,與str_join完全相同,與paste()行為不完全一致。
函式定義:
str_c(..., sep = "", collapse = NULL)
str_join(..., sep = "", collapse = NULL)
引數列表:
…: 多引數的輸入
sep: 把多個字串拼接為一個大的字串,用於字串的分割符。
collapse: 把多個向量引數拼接為一個大的字串,用於字串的分割符。
str_c(c('a','a1'),c('b','b1'),sep='-')
str_c(letters[1:5], " is for", "...")
str_c('a','b',sep='-')#sep可設定連線符
str_c('a','b',collapse = "-") # collapse引數,對多個字串無效
str_c(c('a','a1'),c('b','b1'),collapse='-')
str_c(head(letters), collapse = "") #把多個向量引數拼接為一個大的字串
str_c(head(letters), collapse = ", ")
str_c(letters[-26], " comes before ", letters[-1])
str_c(letters)
############
#對比str_c()函式和paste()函式之間的不同點。
############
str_c('a','b') #把多個字串拼接為一個大的字串。
paste('a','b') # 多字串拼接,預設的sep引數行為不一致
# 向量拼接字串,collapse引數的行為一致
str_c(letters, collapse = "") #collapse 將一個向量的所有元素連線成一個字串,collapse設定元素間的連線符
paste(letters, collapse = "")
#拼接有NA值的字串向量,對NA的處理行為不一致
str_c(c("a", NA, "b"), "-d") #若為空,則無法連線
paste(c("a", NA, "b"), "-d") #即使空,也可連線
str_c(str_replace_na(c("a", NA, "b")), "-d") #即使空,也可連線


3.1.2 str_trim:去掉字串的空格和TAB(\t)
函式定義:str_trim(string, side = c("both", "left", "right"))
引數列表:
string: 字串,字串向量。
side: 過濾方式,both兩邊都過濾,left左邊過濾,right右邊過濾
去掉字串的空格和TAB(\t)
str_trim(string, side = c(“both”, “left”, “right”))
string:需要處理的字串
side:指定剔除空格的位置,both表示剔除首尾兩端空格,left表示剔除字串首部空格,right表示剔除字串末尾空格
string <- ‘ Why is me? I have worded hardly! ‘
str_trim(string, side = ‘left’)
str_trim(string, side = ‘right’)
str_trim(string, side = ‘both’)

3.1.3 str_pad:補充字串的長度
函式定義:str_pad(string, width, side = c("left", "right", "both"), pad = " ")
引數列表:
string: 字串,字串向量。
width: 字串填充後的長度
side: 填充方向,both兩邊都填充,left左邊填充,right右邊填充
pad: 用於填充的字元
> string<-'ning xiao li'
> str_pad(string,10)
[1] "ning xiao li"
> str_pad(string,20)
[1] " ning xiao li"
> str_pad(string,20,side = 'both',pad = '*')
[1] "****ning xiao li****"
> string<-'ning xiao li'
> str_pad(string,10) ##注若指定的長度少於string長度時,將只返回原string
[1] "ning xiao li"
> str_pad(string,20) ## 從右邊補充空格,直到字串長度為20
[1] " ning xiao li"
> str_pad(string,20,side = 'left',pad = '*') # # 從左邊補充空格,直到字串長度為20
[1] "********ning xiao li"
> str_pad(string,20,side = 'left',pad = '*') # # 從右邊補充空格,直到字串長度為20
[1] "********ning xiao li"
> str_pad(string,20,side = 'both',pad = '*') # 從左右兩邊各補充x字元,直到字串長度為20
[1] "****ning xiao li****"

3.1.4 str_dup: 複製字串
函式定義:str_dup(string, times)
引數列表:
string:需要重複處理的字串
times:指定重複的次數
複製一個字串向量。
> val <- c("abca4", 123, "cba2")
# 複製2次
> str_dup(val, 2)
# 按位置複製
> str_dup(val, 1:3)

3.1.5 str_wrap,控制字串輸出格式
函式定義:str_wrap(string, width = 80, indent = 0, exdent = 0)
引數列表:
- string: 字串,字串向量。
- width: 設定一行所佔的寬度。
- indent: 段落首行的縮排值
- exdent: 設定第二行後每行縮排
thanks_path <- file.path(R.home("doc"), "THANKS")
thanks <- str_c(readLines(thanks_path), collapse = "\n")
thanks <- word(thanks, 1, 3, fixed("\n\n"))
cat(str_wrap(thanks), "\n")
cat(str_wrap(thanks, width = 70), "\n") # 設定寬度為70個字元
cat(str_wrap(thanks, width = 80, indent = 6, indent = 2), "\n") # 設定寬度為80字元,首行縮排2字元
cat(str_wrap(thanks, width = 80, indent = 6, exdent = 2), "\n") # 設定寬度為80字元,非首行縮排2字元
3.1.6 str_sub,擷取字串
函式定義:str_sub(string, start = 1L, end = -1L)
引數列表:
- string: 字串,字串向量。
- start : 開始位置
- end : 結束位置
str_sub(string, start = 1L, end = -1L) 提取子字串
str_sub(string, start = 1L, end = -1L) <- value 替換子字串
擷取字串。
txt <- "I am a little bird"
str_sub(txt, 1, 4) # 擷取1-4的索引位置的字串
str_sub(txt, end=6) # 擷取1-6的索引位置的字串
str_sub(txt, 6) # 擷取6到結束的索引位置的字串
str_sub(txt, c(1, 4), c(6, 8)) # 分2段擷取字串
str_sub(txt, -3) # 通過負座標擷取字串
str_sub(txt, end = -3)
x <- "AAABBBCCC" #對擷取的字串進行賦值。
str_sub(x, 1, 1) <- 1; x ## 在字串的1的位置賦值為1
str_sub(x, 2, -2) <- "2345"; x ## 在字串從2到-2的位置賦值為2345

3.2 字串計算函式
3.2.1 str_count, 字串計數
函式定義:str_count(string, pattern = "")
引數列表:
- string: 字串,字串向量。
- pattern: 匹配的字元。
# Word boundaries 單詞邊界
words <- c("These are some words.")
str_count(words) #統計語句中單詞的個數
[1] 21
str_count(words, boundary("word"))
str_split(words, " ")[[1]] #將語句分割成單個片語,最後一個單詞帶有標點
str_split(words, boundary("word"))[[1]]#最後一個單詞不帶有標點

string<-c('ning xiao li','zhang san','zhao guo nan')
str_count(string,'i')

3.2.2 str_length,字串長度
函式定義:str_length(string)
引數列表:
string: 字串,字串向量。
計算字串的長度:
> str_length(c("I", "am", "寧小麗", NA))
[1] 1 2 3 NA
str_length(),字元長度函式,該函式類似於nchar()函式,但前者將NA返回為NA,而nchar則返回2
3.2.3 str_sort, 字串值排序,同str_order索引排序
函式定義:
str_sort(x, decreasing = FALSE, na_last = TRUE, locale = "", ...)
str_order(x, decreasing = FALSE, na_last = TRUE, locale = "", ...)
str_order和str_sort的區別在於前者返回排序後的索引(下標),後者返回排序後的實際值
引數列表:
x: 字串,字串向量。
decreasing: 排序方向。
na_last:NA值的存放位置,一共3個值,TRUE放到最後,FALSE放到最前,NA過濾處理
locale:按哪種語言習慣排序
#str_sort, 字串值排序,同str_order索引排序
str_order(c('wo','love','five','stars','red','flag'),locale = "en")
str_sort(c('wo','love','five','stars','red','flag'),locale = "en") # 按ASCII字母排序
str_sort(c('wo','love','five','stars','red','flag'),,decreasing=TRUE) # 倒序排序
str_sort(c('我','愛','五','星','紅','旗'),locale = "zh") # 按拼音排序

對NA值的排序處理
#把NA放最後面
> str_sort(c(NA,'1',NA),na_last=TRUE)
[1] "1" NA NA
#把NA放最前面
> str_sort(c(NA,'1',NA),na_last=FALSE)
[1] NA NA "1"
#去掉NA值
> str_sort(c(NA,'1',NA),na_last=NA)
[1] "1"
3.3 字串匹配函式
3.3.1 str_split,字串分割,同str_split_fixed
函式定義:
str_split(string, pattern, n = Inf)
str_split_fixed(string, pattern, n)
引數列表:
string: 字串,字串向量。
pattern: 匹配的字元。
n: 分割個數 #最後一組就不會被分割
對字串進行分割。
### str_split與str_split_fixed的區別
### 在於前者返回列表格式,後者返回矩陣格式
val <- "abc,123,234,iuuu"
s1<-str_split(val, ","); s1 # 以,進行分割
s2<-str_split(val, ",",2); s2 # 以,進行分割,保留2塊
class(s1) # 檢視str_split()函式操作的結果型別list
s3<-str_split_fixed(val, ",",2); s3 # 用str_split_fixed()函式分割,結果型別是matrix
class(s3)

3.3.2 str_subset:返回的匹配字串函式定義:
str_subset(string, pattern)
引數列表:
string: 字串,字串向量。
pattern: 匹配的字元。
fruit <- c("apple", "banana", "pear", "pinapple")
str_subset(fruit, "a") ## 全文匹配
str_subset(fruit, "ap") ##返回含字元'ap'的單詞
str_subset(fruit, "^a") ## 開頭匹配
str_subset(fruit, "a$") ## 結尾匹配
str_subset(fruit, "b") ##返回含字元'b'的單詞
str_subset(fruit, "[aeiou]") ##返回含'aeiou'任一個字元的單詞
str_subset(c("a", NA, "b"), ".") #丟棄空值
#該函式與word()函式的區別在於前者提取字串的子串,後者提取的是單詞,而且str_sub也可以其替換的作用。
string <- 'My name is ABDATA, I’m 27.'
str_sub(string, -3,-2) <- 25; string

str_subset()函式與word()函式的區別在於前者提取字串的子串,後者提取的是單詞,而且str_sub也可以其替換的作用。
3.3.3word, 從文字中提取單詞(適用於英語環境下的使用)
函式定義:word(string, start = 1L, end = start, sep = fixed(" "))
引數列表:
- string: 字串,字串向量。
- start: 開始位置。
- end: 結束位置。
- sep: 匹配字元。
sentences <- c("nxl saw a cat", "nxl sat down")
word(sentences, 1) #提取第一個單詞
word(sentences, 2) #提取第二個單詞
word(sentences, -1) #提取句子的最後一個單詞
word(sentences, 2, -1) #提取第二個單詞到最後一個單詞
word(sentences[1], 1:3, -1) #整個句子從第一個單詞遞減掉三個單詞
word(sentences[1], 1:6, -1) #整個句子從第一個單詞遞減掉的單詞
word(sentences[1], 1, 1:4) #從句子的第一個單詞遞增到第四個單詞
str <- 'abc.def..123.4568.999'
word(str, 1, sep = fixed('..')) # 指定分隔符
word(str, 2, sep = fixed('..'))
word(str, 3, sep = fixed('..'))
val<-'111,222,333,444'
word(val, 1, sep = fixed(',')) # 以,分割,取第一個位置的字串
word(val, 3, sep = fixed(','))

3.3.4 str_detect匹配字串的字元-- 檢測函式,用於檢測字串中是否存在某種匹配模式
函式定義:str_detect(string, pattern)
引數列表:
string: 字串,字串向量。
pattern: 匹配字元。
> val <- c("abca4", 123, "cba2")
# 檢查字串向量,是否包括a
> str_detect(val, "a")
# 檢查字串向量,是否以a為開頭
> str_detect(val, "^a")
# 檢查字串向量,是否以a為結尾
> str_detect(val, "a$")
3.3.6 str_match,從字串中提取匹配組
函式定義:
str_match(string, pattern)
str_match_all(string, pattern)
引數列表:
string: 字串,字串向量。
pattern: 匹配字元。
val <- c("abc", 123, "cba") # 從字串中提取匹配組
str_match(val, "a") # 匹配字元a,並返回對應的字元
str_match(val, "[0-9]") # 匹配字元0-9,限1個,並返回對應的字元
str_match(val, "[0-9]*") # 匹配字元0-9,不限數量,並返回對應的字元
str_match_all(val, "a") #從字串中提取匹配組,以字串matrix格式返回
str_match_all(val, "[0-9]")


str_match()和str_match_all()區別在於前者只提取一次滿足條件的匹配物件,而後者可以提取所有匹配物件
3.3.7 str_replace,字串替換
函式定義:str_replace(string, pattern, replacement)
引數列表:
string: 字串,字串向量。
pattern: 匹配字元。
replacement: 用於替換的字元。
val <- c("abc", 123, "cba")
str_replace(val, "[ab]", "-") #替換第一個匹配的字元# 把目標字串第一個出現的a或b,替換為-
str_replace_all(val, "[ab]", "-") #替換所有匹配的字元 # 把目標字串所有出現的a或b,替換為-
str_replace_all(val, "[a]", "\1\1") # 把目標字串所有出現的a,替換為被轉義的字元
str_replace與str_replace_all的區別在於前者只替換一次匹配的物件,而後者可以替換所有匹配的物件

3.3.8 str_replace_na把NA替換為NA字串
函式定義:str_replace_na(string, replacement = "NA")
引數列表:
- string: 字串,字串向量。
- replacement : 用於替換的字元。
把NA替換為字串
> str_replace_na(c(NA,'NA',"abc"),'x')
[1] "x" "NA" "abc"
3.3.9 str_locate,找到的模式在字串中的位置。
str_locate()和str_locate_all()的區別在於前者只匹配首次,而後者可以匹配所有可能的值
> str_locate(val, "a")
start end
[1,] 1 1
[2,] NA NA
[3,] 3 3
# 用向量匹配
> str_locate(val, c("a", 12, "b"))
start end
[1,] 1 1
[2,] 1 2
[3,] 2 2
# 以字串matrix格式返回
> str_locate_all(val, "a")
[[1]]
start end
[1,] 1 1
[2,] 4 4
[[2]]
start end
[[3]]
start end
[1,] 3 3
# 匹配a或b字元,以字串matrix格式返回
> str_locate_all(val, "[ab]")
[[1]]
start end
[1,] 1 1
[2,] 2 2
[3,] 4 4
[[2]]
start end
[[3]]
start end
[1,] 2 2
[2,] 3 3
string <- c('nxl123','zhazha234')
str_locate(string,'z')
str_locate(string,'n')
str_locate_all(string,'n')

3.3.10 str_extract從字串中提取匹配模式
函式定義:
str_extract(string, pattern)
str_extract_all(string, pattern, simplify = FALSE)
引數列表:
string: 字串,字串向量。
pattern: 匹配字元。
simplify: 返回值,TRUE返回matrix,FALSE返回字串向量
shopping_list <- c("apples 4x4", "bag of flour", "bag of sugar", "milk x2")
str_extract(shopping_list, "\\d") # 提取數字 #提取匹配模式的第一個字串
str_extract(shopping_list, "[a-z]+") #提取字母
str_extract_all(shopping_list, "[a-z]+") # 提取所有匹配模式的字母,結果返回一個列表
str_extract_all(shopping_list, "\\d") # 提取所有匹配模式的數字
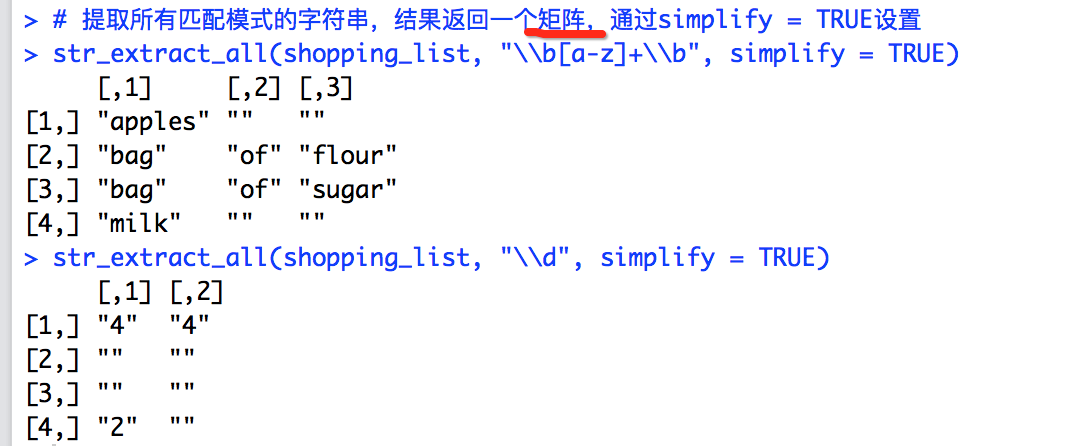
# 提取所有匹配模式的字串,結果返回一個矩陣,通過simplify = TRUE設定
str_extract_all(shopping_list, "\\b[a-z]+\\b", simplify = TRUE)
str_extract_all(shopping_list, "\\d", simplify = TRUE)

str_extract(string, pattern) 提取匹配的第一個字串
str_extract_all(string, pattern, simplify = FALSE) 提取匹配的所有字串
功能與str_match(),str_match_all()函式類似
3.4 字串變換函式3.4.1 str_conv:字元編碼轉換
函式定義:str_conv(string, encoding)
引數列表:
- string: 字串,字串向量。
- encoding: 編碼名。
對中文進行轉碼處理。
# 把中文字元位元組化
> x <- charToRaw('你好');x
[1] c4 e3 ba c3
# 預設win系統字符集為GBK,GB2312為GBK字集,轉碼正常
> str_conv(x, "GBK")
[1] "你好"
> str_conv(x, "GB2312")
[1] "你好"
# 轉UTF-8失敗
> str_conv(x, "UTF-8")
[1] "���"
Warning messages:
1: In stri_conv(string, encoding, "UTF-8") :
input data \xffffffc4 in current source encoding could not be converted to Unicode
2: In stri_conv(string, encoding, "UTF-8") :
input data \xffffffe3\xffffffba in current source encoding could not be converted to Unicode
3: In stri_conv(string, encoding, "UTF-8") :
input data \xffffffc3 in current source encoding could not be converted to Unicode
把unicode轉UTF-8
> x1 <- "\u5317\u4eac"
> str_conv(x1, "UTF-8")
[1] "北京"
3.4.2 str_to_upper,字串大寫轉換。
函式定義:
str_to_upper(string, locale = "")
str_to_lower(string, locale = "")
str_to_title(string, locale = "")
引數列表:
- string: 字串。
- locale:按哪種語言習慣排序
字串大寫轉換:
> val <- "I am conan. Welcome to my blog! http://fens.me"
# 全大寫
> str_to_upper(val)
[1] "I AM CONAN. WELCOME TO MY BLOG! HTTP://FENS.ME"
# 全小寫
> str_to_lower(val)
[1] "i am conan. welcome to my blog! http://fens.me"
# 首字母大寫
> str_to_title(val)
[1] "I Am Conan. Welcome To My Blog! Http://Fens.Me"
字串在平常的資料處理中經常用過,需要對字串進行分割、連線、轉換等操作,本篇中通過介紹stringr,靈活的字串處理庫,可以有效地提高程式碼的編寫效率。有了好的工具,在用R語言處理字串就順手了。
---------------------------------
常用功能:
# 合併字串
fruit <- c("apple10", "banana"," ", "pe1ar", "pina22222pple","NA")
res <- str_c(1:4,fruit,sep=' ',collapse=' ')
str_c('I want to buy ',res,collapse=' ')
# 計算字串長度
str_length(c("i", "like", "programming R", 123,res))
# 按位置取子字串
str_sub(fruit, 1, 3)
# 子字串重新賦值
capital <-toupper(str_sub(fruit,1,1))
str_sub(fruit, rep(1,4),rep(1,4)) <- capital
# 重複字串
str_dup(fruit, c(1,2,3,4))
# 加空白
str_pad(fruit, 10, "both")
# 去除空白
str_trim(fruit)
# 根據正則表示式檢驗是否匹配
str_detect(fruit, "a$")
str_detect(fruit, "[aeiou]")
# 找出匹配的字串位置(字元定位函式,返回匹配物件的首末位置)
str_locate(fruit, "a")
# 提取匹配的部分
str_extract(fruit, "[a-z]+")
str_match(fruit, "[a-z]+")
# 替換匹配的部分
str_replace(fruit, "[aeiou]", "-")
# 分割
str_split(res, " ")
str_extract(fruit, "\\d") # 提取數字
str_extract(fruit, "[a-z]+") #提取字母
注:R語言中正則表示式的不同之處是轉義符號是“\\”,其他方面和通常的“正則表示式”是一樣的
正則表示式定義
轉義字元
\o NUL字元(\u0000)
\t 製表符(\0009)
\n 換行符(\000A)
\v 垂直製表符(\u000B)
\f 換頁符(\000C)
\r 回車符(\000D)
\xnn 十六進位制拉丁字元
\uxxxx十六進位制unicode字元
\cX 控制字元
這些轉義字元中比較常用的就是換行符了,其他記不住可以上網查。還有一些字元具有特殊含義,如果需要匹配這些字元的時候需要在前面加上反斜槓進行轉義。
^ $ . * + ? = ! : | \ / ( ) [ ] { }
字元類
[...] 方括號內任意字元
[^...] 不在方括號內任意字元
. 除換行符和其他unicode行終止符之外的任意字元
\w 等價於[a-zA-Z0-9]
\W 等價於[^a-zA-Z0-9]
\s 任何unicode空白符
\S 任何非unicode空白符
\d 等價於[0-9]
\D 等價於[^0-9]
[\b] 退格
這個字元類很重要,需要記憶。
描述方式:重複
知識點
{n,m} 匹配前一項至少n次,不超過m次
{n,} 匹配前一項至少n次
{n} 匹配前一項n次
? 等價於{0,1}
+ 等價於{1,}
* 等價於{0,}
x? 描述符後跟隨一個"?"表示非貪婪匹配:從字串中第一個可能匹配的位置,儘量少的匹配。如“??”、“{1,5}?”等。
描述方式:選擇、分組和引用
“|”與邏輯表示式中的或類似,前後兩者任意一個匹配,很好理解。而圓括號用來分組和引用,功能就比較複雜了。
把單獨的項組合成子表示式,以便重複、選擇等操作。
完整的模式中定義子模式,從而在匹配成功後從目標串中抽出和圓括號中的子模式匹配的部分。
同一個正則表示式中後部引用前部的正則表示式,注意因為子表示式可以巢狀,所以它的位置是參與計數的左括號的位置。如果不建立帶數字編碼的引用,可以用"(?"和")"表示。
舉個簡單的例子,如果要匹配單引號或雙引號中的字元,可能會寫成下面這樣:
/['"][^'"]*['"]/
但是如果我們是想成對的匹配'abc'而不是匹配'abc"的話需要這麼改寫:
/(['"])[^'"]*\1/
錨
指定匹配位置的元素稱為錨。
^ 匹配字串開頭,多行匹配一行的開頭
$ 匹配字串結尾,多行匹配一行的結尾
\b 匹配一個單詞的邊界,位於\w和\W之間的位置
\B 匹配非單詞邊界
(?=p) 要求接下來的字元都與p匹配,但不能包括匹配p的那些字元
(?!p) 要求接下來的字元不與p匹配
修飾符
i。忽略大小寫
m。多行匹配模式
g。全域性匹配
字串中的模式匹配
search
查詢匹配的字串,不支援全域性匹配,返回第一個子串的起始位置。
"JavaScript".search(/script/i) //4
match
返回由匹配結果組成的陣列,預設返回第一個匹配的字串,如果全域性匹配則返回所有匹配字串。當使用括號分組的時候第一個元素為匹配的字串,其後為圓括號中各個匹配的子字串。
split
這是將字串轉化為陣列的方法。一般用字串做分隔符匹配,如果使用正則表示式,則在匹配字串的前後方斷開。同時注意以下幾點:
匹配到開頭內容,返回陣列第一個元素為空字串。
匹配到結尾內容,返回陣列最後一個元素為空字串。
未匹配,返回陣列只包含未切分的字串。
replace
$n 匹配第n個匹配正則表示式中的圓括號子表示式文字
$& 匹配正則表示式的子串
$` 匹配子串左邊的文字
$' 匹配子串右邊的文字
$$ 匹配美元符號
RegExp物件
屬性
source 正則表示式文字
global 只讀布林值,是否有修飾符g
ignoreCase 只讀