
Linux VRF(Virtual Routing Forwarding)的原理和實現
動機
明天,是2017年9月24日,兩年前的明天,我從上海第一次來到深圳參加面試,兩年前的今天,此時我還在上海虹橋機場等候延誤的飛機,兩年前的今晚,我在深圳南山區南新路片區徘徊,企圖能在南方城市找到一家東北燒烤,並且欣賞這座城市(最終我找到了!),兩年前的明晚,我喝了一瓶750ml的威士忌,次日返回上海…面試後,我感覺我被錄取了,然後做了一個決定,舉家再次搬遷,來到了深圳,在上海留下了我的空房和我的足跡…這是個值得紀念的日子。
本文依舊是一篇聊點技術的散文。
馬上要放長假了,放假前的最後一個週末,總結了一個沒有深度但很常用的主題,這便是VRF(虛擬路由轉發),第一次接觸這個概念是在2004年底,也就是在大學的前幾堂課(我相信本科是不會講這個的,我們是真正的技校,就業為導向,所以我們講這個,不過我承認,我那99.99%的同學們直到現在可能就接觸過這僅有的一次VRF概念…),後面就喜歡上了網路和通訊,不過說實話真正使用VRF的時候並不多,畢竟作為程式設計師能接觸到的網路環境非常有限,即便如此,我還是希望這篇文章能幫到想深入瞭解VRF的人們。
寫這篇文章的另外一個動機來自於憤怒,因為當我希望學習一點新東西的時候,我總是找不到中文資料(我的英文水平比較Low,相信大多數人也比我好不到哪去),所以我必須自己寫一篇或者持續寫幾篇,比如nftables,BBR這種…對於Linux的VRF實現而言,它來自於Linux 4.3核心,到如今已經有段時間了,然而網上依然沒有中文資料,這是寫作本文的最大動機。
Linux實現VRF之前
VRF是一個基本上玩網路的人都懂的概念,同時作為一個Linux粉的話,你肯定會問一個問題,Linux如何配置VRF?畢竟Linux誕生於網路,其網路技術一直都是緊隨業界潮流的。
然而搜到的答案几乎千篇一律是使用net namespace
提前劇透一點,VRF就是一臺物理裝置虛擬成多臺路由器,net namespace可以把整個協議棧都給虛擬了,難道還不能虛擬一臺路由器嗎?然而我們知道的一個事實卻是,路由器不需要完整的協議棧的,只需要虛擬到第三層就可以了,因此,net namespace對於VRF而言,太重了。我們看下net namespace的結構:
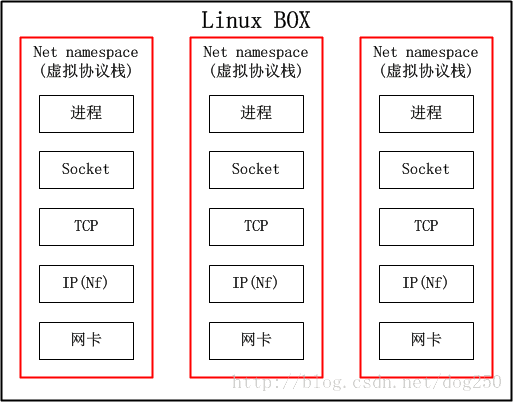
說白了,如果不考慮記憶體,CPU等其它共享的資源,僅僅從網路的角度來看,net namespace就跟個虛擬機器一樣,這樣的隔離對於VRF來講實屬無必要!因此,Linux一定可以有更好的方案實現VRF。不過遺憾的是,直到Linux 4.3核心,VRF都沒有得到實現,我曾經長期基於Linux 2.6.8和2.6.32核心工作,沒有發現VRF,因此我不得不用複雜的策略路由配合同樣複雜的iptables規則來模擬VRF的表現,工作量之巨大讓我放棄了多少個週末和假期…
事實上,我在2012年底的時候就想在Linux實現一個完備的VRF,因為我實在要用到它。後續我用超級複雜的iptables,策略路由,自定義Netfilter模組實現了類似VRF的功能,也就不再想這個事了,再後來,我徹底離開了這個領域,就幾乎把它忘掉了,然而在我例行Review新核心新特性的時候,我發現Linux如今的VRF已經實現得相當好
了。
這就是我寫本文的前奏背景,以下是正文。
VRF的原理
由於本節僅僅介紹原理,為了簡單起見,我是僅僅把Linux BOX當成轉發裝置看待的,這更容易理解,所以我忽略本機始發並路由出去的流量的。因此這部分流量的處理邏輯我並沒有畫在圖中,特此宣告。
考慮下面的拓撲:
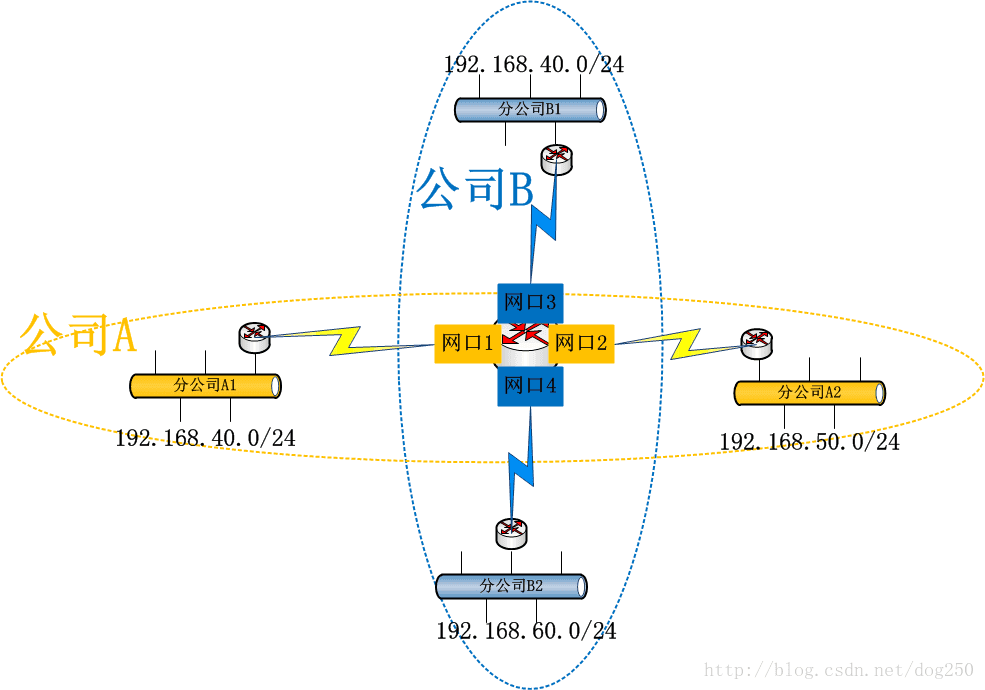
A和B是兩個獨立的公司,通過某種VPN技術來互聯,但是A的分公司A1,A2和B的分公司B1,B2都使用192.168.0.0/16這個私有網段,並且它們的流量全部都通過公共路由器R,這讓路由器R如何抉擇哪個192.168/16段的IP地址是A分公司的,哪個是B分公司的…
也許你會說,這種IP地址分配方案是不合理的,畢竟IP地址的唯一性是構建可路由的IP網路的首要前提啊!但是,你有所不知,VPN的本旨就是要做到專網專用,它本來
可能就沒打算在公網上路由流量,只是邏輯上小機構互通即可,公網對於VPN而言只是一個載體。邏輯上互通的機構可能在地理位置上有所交叉重疊,所以就會帶來上述的問題,如何解決呢?那勢必是策略路由啦!
首先我們來看一下策略路由的原理:
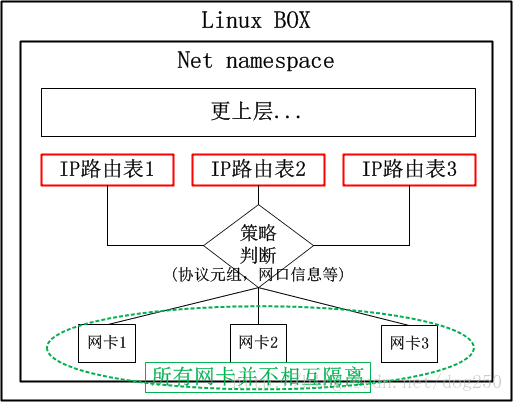
對於上述的場景,很顯然,我們需要以下的策略路由:
in 網口1 table A
in 網口2 table A
in 網口3 table B
in 網口4 table B- 1
- 2
- 3
- 4
系統內建了兩張路由表,公司A和公司B分別有一張路由表,資料從特定網絡卡收到後,各查各的路由表即可。貌似很不錯的一個解決方案,有沒有什麼問題呢?
如果說配置管理員不小心把“網絡卡1”寫成了“網絡卡3”怎麼辦?特別是,如果網絡卡特別多,接入的企業也非常多,豈不是更加難以管理和維護嗎?問題就出在:
這些網絡卡相互之間並非隔離的,依靠策略隔離的僅僅是路由表
那麼,如何解決這個問題呢?換句話說,有沒有什麼解決方案是專門保證三層隔離的前提下隔離網絡卡的呢?答案當然汗牛充棟,比如net namespace就可以,但對於路由器而言,這種方式過於重量級了,對於路由器而言,只需要一個Layer 3的隔離方案即可!在網路技術中,有一個叫做VRF的概念正好就是做這個的。什麼是VRF?
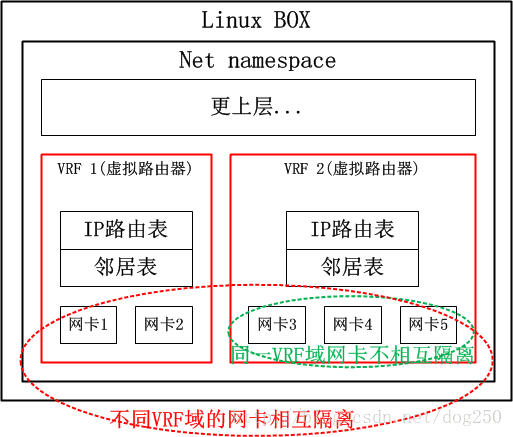
VRF顧名思義就是虛擬路由轉發(Virtual Routing Forwarding),簡單點來講,就是把一臺路由器當多臺虛擬路由器來用,這種技術在二層就是VLan技術,或者更加通用的虛擬交換機(在多網絡卡的Linux BOX上,建立多個bridge裝置並把不同的網絡卡加入其中,就是一臺攜帶多個虛擬交換機的物理交換機),我把二層的方案列如下:

那麼,三層的VRF自然而然就是下面的樣子咯:
現在考慮一個非常常見的場景,即OpenVPN典型的多處理拓撲,在一臺伺服器上會構建超級多的TAP網絡卡,每個TAP服務一個特定的VPN客戶端,有了VRF的支撐後,不同的VPN節點便可以使用相同的IP網段了,所要做的僅僅是將不同的TAP網絡卡置入不同的VRF域即可。
大致明白了VRF的原理之後,我們來看一下VRF和策略路由的關係。
我們已經知道VRF是一臺物理路由器當多臺虛擬路由器使用的,那麼在這多臺虛擬路由器之間就必須做到從物理層到三層路由的全部隔離(請注意,路由器是個三層裝置),而策略路由僅僅是路由表的隔離,甚至在僅僅使能了策略路由的路由器上,其二層三層之間的鄰居表都是共享的。不過,策略路由確實是實現VRF的元件之一,它確實可以完成VRF的路由表隔離,本文的後續可以看到,Linux正是使用策略路由來實現VRF路由表隔離的。
但是僅僅依靠策略路由機制是無法構建完整的VRF體系的,為了實現二層隔離以及網絡卡的隔離,還需要另外的技術,Linux的VRF實現中,採用了一種叫做L3mdev的技術來支援一種三層的虛擬網絡卡,利用這種虛擬網絡卡來隱藏網絡卡之間的可見性。
欲知詳情,請繼續閱讀。
Linux VRF的使用和配置
本節是例行的一節,如果你都沒讓系統跑起來就去研究它的原理,那勢必是本末倒置的,研究技術的目的是更好地使用技術,所以必然要先用起來VRF。
但我不準備在本節著墨太多,因此我選擇了引用的方式。因為幾個老外已經把使用和配置寫得淋漓盡致了,這些東西,我再寫也只是複製貼上,顯得毫無意義,因此我引用他們寫好的東西,同時,作為補充,本節以下我寫一些他們沒有提到的東西。
本節的重點就是下面幾個連結,文章都不長,全部都是Step by step式的Howto,請把它們看完,你將學會Linux VRF的使用方法!
這些文章詳細描述了Linux VRF的配置技巧,同時提到了一些版本實現的差異所帶來的後果,你必須看完並且親自動手實踐了,然後再去了解Linux VRF的實現。
以下的內容是為懶人準備的,如果你看了Linux VRF的實現沒有看明白,或者說根本就不想看,那麼請接著看本文下面的部分。
Linux VRF實現概覽
要說實現,虛擬網絡卡!虛擬網絡卡!還是虛擬網絡卡!不然的話我也不會寫下本文的,我是在Review新特性的時候,例行掃描drivers/net目錄時掃到了vrf.c說是實現了一塊虛擬網絡卡,然後才進一步分析的。
我很喜歡這目錄裡的玩意兒,從OpenVPN使用Tap/Tun,IPSec VTI,到Bridge,Bonding,VLan,VXLan…這些在Linux系統中,全部基於虛擬網絡卡來實現!總體來講,所有這些虛擬網絡卡,最終都要有真實的東西附著在上面,比如:
- 附著字元裝置在上面的:OpenVPN的Tun/Tap網絡卡
- 附著物理網絡卡的:Bridge,Bonding,VLan
- 附著加密引擎的:VTI
…
本文提到的VRF也是基於虛擬網絡卡實現,每一個VRF域都表現為一個虛擬網絡卡,然後將具體的物理網絡卡(或者是別的虛擬網絡卡)新增到特定的VRF虛擬網絡卡,從而實現隔離:

可見,VRF虛擬網絡卡實現了三層邏輯,該三層邏輯就是VRF路由表隔離,具體的實現細節下面的小節會結合程式碼詳述,本節只是給出概覽。
Linux VRF的實現細節
Linux核心在4.3版本中引入了VRF的支援,說實話這讓我等了好久,等到Linux真的提供了VRF機制時,我早已不做這東西了!
總體來講,Linux的VRF機制的實現過程和Linux CFS排程器實現的過程非常類似,也是分了兩個階段:
-
CFS實現兩階段:
- 2.6.23核心~2.6.27核心:第一階段基礎版。複雜版的CFS
- 2.6.27核心以後:第二階段完備版。樸素版的CFS
-
VRF實現兩階段:
- 4.3核心~4.8核心:第一階段基礎版。基礎設施不完善,需要外部策略路由規則配合才可用
- 4.8核心以後:第二階段完備版。引入了L3mdev,完善的基礎設施支援
在第一階段的實現中,VRF的實現非常簡單。我先給出一個總的圖景,再細說:
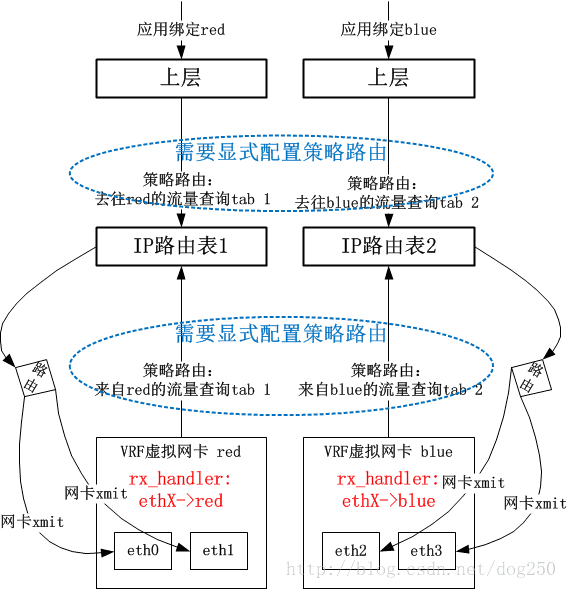
資料包在被物理網絡卡ethX接收後,在netif_receive_skb中,會有rx_handler回撥來截獲資料包。VRF會註冊一個rx_handler回撥,該回調中將skb的dev欄位替換為VRF虛擬網絡卡Device物件,這個處理是和Bridge處理一致的。接下來,系統依賴以下的事實來實現VRF邏輯:
- 資料包skb的dev欄位已經是VRF裝置,表明資料包看起來是通過VRF X來接收的
- 使用者顯式配置的Policy Routing的rule要求來自VRF X接收的資料包要查詢X號路由表
這就實現了VRF邏輯。
可以看到,使用者需要自己來手工完成策略路由表的定向操作,這個配置是重點,沒有它的話,便不會讓VRF網絡卡接收的資料包查詢策略路由表。
這明顯是一種很初級但可用(我的做法確實Low,但是就是可用!這是Linux的一種典型的文化)的做法。很自然的,Linux 4.8核心開始,VRF有了第二階段的實現方法,省略了使用者自己手工配置策略路由這個步驟。
在Linux 4.8核心以及以後,系統提供了一種更加優雅的做法,即引入了一個叫做L3mdev(Layer 3 master device)的機制,有了這個L3mdev機制,便省去了顯式配置策略路由的必要。在建立一個VRF虛擬網絡卡的時候,系統便將其與一個特定的策略路由表自動關聯,L3mdev機制基於這種關聯來完成策略路由表的定向操作。
這種L3mdev機制事實上相當於又一個3層的Hook,該Hook將感興趣流量偽裝成從一個虛擬網絡卡接收,用該虛擬網絡卡來實現一些特定於3層的處理邏輯,這種風格實際上只是利用了虛擬網絡卡,而並不是非用不可。
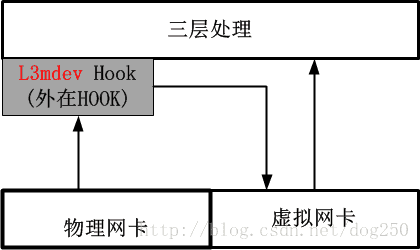
我們對比一下4.8核心之前的處理方法,就知道如今的L3mdev有多麼高尚了,老的註冊rx_handler回撥的方法如下圖:
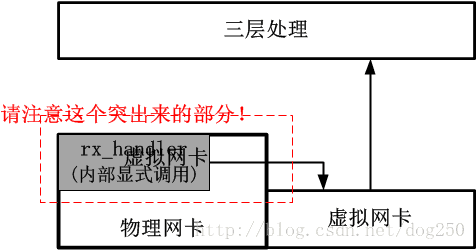
可以看出,4.8核心之後的方法十分優雅,它幾乎不觸動不影響不破壞任何既有的處理邏輯。新的實現是高尚的!
現在,我給出採用新的L3mdev機制的VRF實現框圖(請與老的rx_handler回撥方式做對比):
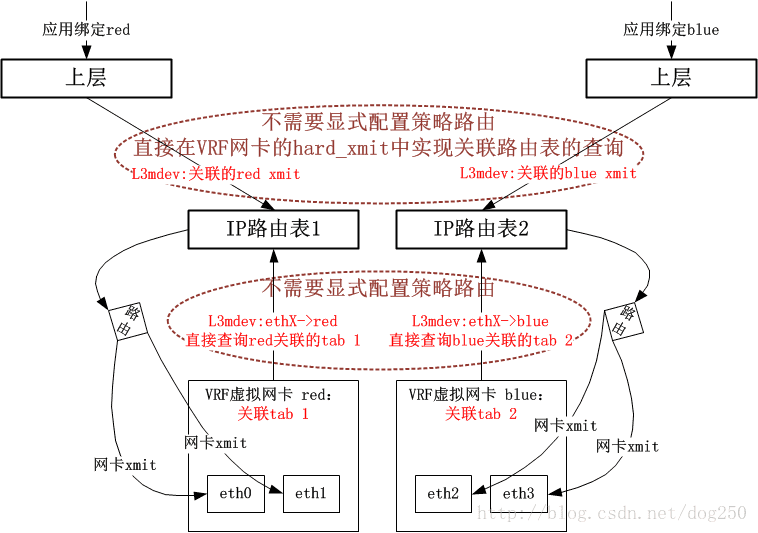
以上就是VRF實現的總體架構了,接下來我會給出一些細節,在分析這些細節之前,我先將VRF的實現分成了兩個部分:
- 控制路徑部分
這部分主要控制VRF虛擬網絡卡的建立,策略路由表的關聯等。 - 資料路徑部分
這部分主要描述資料時如何通過VRF路由的。
控制路徑的實現邏輯
當我們建立了一個VRF域的時候,發生了什麼?我想下圖是可以解釋的:
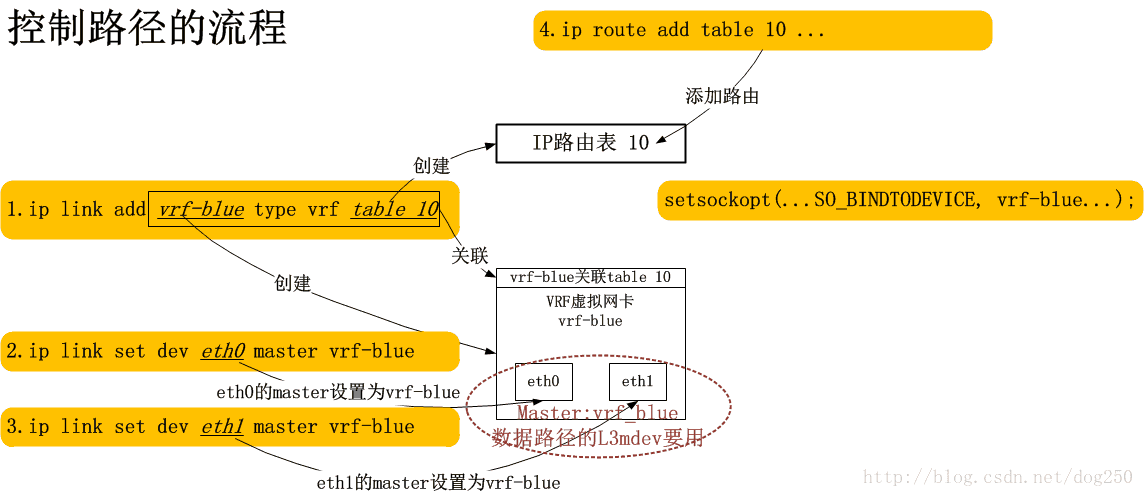
簡單點說,每一條命令都為最終的資料通道基礎設在施添磚加瓦,最終構建一條完備的資料通道。
資料路徑的實現邏輯
以下(即Linux 4.8及以後的VRF核心實現)來用兩個情景分析的方式闡述VRF的實現,通過這兩個情景分析,基本上VRF的實現也就瞭然於胸了。(如果我這裡的論述顯得晦澀,那就權當是提綱吧,這部分程式碼很簡單,自己走讀一下即可)
網絡卡收包過程的VRF實現分析
從獨立的物理網絡卡,比如eth0收到資料包,依次經過網絡卡驅動程式,netif_receive_skb,ip_rcv等呼叫,直到ip_rcv_finish被呼叫之前,VRF的邏輯和非VRF邏輯並沒有任何不同支援,在ip_rcv_finish中,事情起了變化:
static int ip_rcv_finish(struct net *net, struct sock *sk, struct sk_buff *skb)
{
const struct iphdr *iph = ip_hdr(skb);
struct rtable *rt;
struct net_device *dev = skb->dev;
/* if ingress device is enslaved to an L3 master device pass the
* skb to its handler for processing
*/
// 這裡增加了這麼一個L3mdev呼叫,正是該L3mdev邏輯的處理,實現了VRF的核心:路由表使用與VRF域關聯的策略路由表
skb = l3mdev_ip_rcv(skb);
// 後面的邏輯直到定位路由表,VRF邏輯和常規邏輯沒有任何不同
...
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
具體來講,l3mdev_ip_rcv的邏輯非常簡單,對於VRF而言,實現l3mdev_l3_rcv回撥函式完成的功能僅僅是:
- 將skb的dev欄位重新修改為該dev的master裝置,即該物理網絡卡附著的VRF虛擬網絡卡裝置
僅此而已!
我們接下來看下上述的l3mdev_ip_rcv裡做的關於skb的dev欄位的修改在什麼時候會用到。可以想象的是,當然是在定位策略路由表的時候用的咯,問題是,在程式碼層面這是怎麼實現的。
我們跳過中間步驟,直達策略路由表的定位,在定位路由表的時候,實際上是在定位一個rule,系統會遍歷所有的rules連結串列,比較典型的rules連結串列可以通過下面的命令檢視:
ip rule ls- 1
一般情況下,我們會看到以下結果:
0: from all lookup local
32766: from all lookup main
32767: from all lookup default - 1
- 2
- 3
然而,當我們配置了至少一個VRF域的時候,我們將會看到如下的結果:
0: from all lookup local
1000: from all lookup [l3mdev-table]
32766: from all lookup main
32767: from all lookup default - 1
- 2
- 3
- 4
嗯,多了一個l3mdev-table,系統在遍歷rules連結串列的時候,遇到[l3mdev-table]表的時候,採用的是一種隱式的處理方式。意思是說,即便你建立了多個VRF域,關聯了多張策略路由表,系統中依然只能看到一張[l3mdev-table]表。既然這樣,系統又是如何定位到與特定的VRF域關聯的那張路由表呢?比如說,vrf-blue關聯了路由表10,vrf-red關聯了路由表20,此時正在處理的包屬於vrf-blue,系統如何定位到要查詢路由表10而不是路由表20呢?
為了瞭解[l3mdev-table]的工作方式,就需要看下fib_rule_match的邏輯:
static int fib_rule_match(struct fib_rule *rule, struct fib_rules_ops *ops,
struct flowi *fl, int flags,
struct fib_lookup_arg *arg)
{
int ret = 0;
...
// 前面的邏輯是常規的iif,oif,mark等匹配,以下的這個l3mdev不一般!
// rule->l3mdev即ip rule ls看到的那個[l3mdev-table]
if (rule->l3mdev && !l3mdev_fib_rule_match(rule->fr_net, fl, arg))
goto out;
ret = ops->match(rule, fl, flags);
out:
return (rule->flags & FIB_RULE_INVERT) ? !ret : ret;
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
我們重點看下l3mdev_fib_rule_match:
int l3mdev_fib_rule_match(struct net *net, struct flowi *fl,
struct fib_lookup_arg *arg)
{
struct net_device *dev;
int rc = 0;
rcu_read_lock();
... // 我們僅僅分析iif情景
dev = dev_get_by_index_rcu(net, fl->flowi_iif);
// 如果這個dev是一個VRF master虛擬網絡卡裝置
if (dev && netif_is_l3_master(dev) &&
dev->l3mdev_ops->l3mdev_fib_table) {
// 那麼便通過其自身的回撥函式取出和該VRF關聯的策略路由表!
arg->table = dev->l3mdev_ops->l3mdev_fib_table(dev);
rc = 1;
goto out;
}
out:
rcu_read_unlock();
return rc;
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
到此為止呢,我們的一幅圖景就閉合了:
- 首先在ip_rcv_finish的l3mdev_ip_rcv呼叫中定位到與收包物理網絡卡關聯的VRF master虛擬網絡卡
- 然後在fib_lookup內層的l3mdev_fib_rule_match呼叫中取出與VRF master虛擬網絡卡關聯的策略路由表
- 最終在該特定的路由表中進行路由查詢
畢!
本地始發包的VRF實現分析
接下來我們看下本地發包的情景。
由於本地的資料包全部來自於某個socket而不是網絡卡,socket是不和網絡卡關聯的,所以IP層在查路由之前無法知道一個數據包和哪個網絡卡關聯,就更別提去選擇使用哪張路由表了…
因此,如若一個socket程式想使用VRF機制,就必須為一個socket去繫結一個特定的網絡卡:
setsockopt(sd, SOL_SOCKET, SO_BINDTODEVICE, vrf_dev, strlen(vrf_dev)+1);- 1
有了這個呼叫,在ip_queue_xmit中查詢路由的時候,自然就會在fib_rule_match中定位到與引數vrf_dev關聯的策略路由表了,然而,如果socket程式並不知情,它只是bind了一個隸屬於該vrf_dev的slave物理網絡卡,比如eth0,那要怎麼處理呢?
顯然SO_BINDTODEVICE引數會為資料包在__ip_route_output_key_hash呼叫中的路由查詢失敗而負責,為其暫時繫結一個dummy dst_entry,從而邏輯可以到達__ip_local_out:
int __ip_local_out(struct net *net, struct sock *sk, struct sk_buff *skb)
{
struct iphdr *iph = ip_hdr(skb);
iph->tot_len = htons(skb->len);
ip_send_check(iph);
/* if egress device is enslaved to an L3 master device pass the
* skb to its handler for processing
*/
skb = l3mdev_ip_out(sk, skb);
...
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
和網絡卡收包過程的l3mdev呼叫一樣,我們看下這個與l3mdev_ip_rcv相對的l3mdev_ip_out呼叫裡做了什麼文章,實現對應回撥函式的是vrf_ip_out:
static struct sk_buff *vrf_ip_out(struct net_device *vrf_dev,
struct sock *sk,
struct sk_buff *skb)
{
struct net_vrf *vrf = netdev_priv(vrf_dev);
...
// 取出VRF關聯的那個唯一的dst_entry,以便將資料包定向到vrf_xmit
rth = rcu_dereference(vrf->rth);
if (likely(rth)) {
dst = &rth->dst;
dst_hold(dst);
}
...
skb_dst_set(skb, dst);
return skb;
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
很簡單,在這裡僅僅是將skb的那個dummy dst_entry換成了和VRF裝置繫結的那個dst_entry。
事實上,與VRF裝置繫結的dst_entry只有一個且只做一件事,那就是,呼叫VRF裝置的dev_hard_xmit回撥函式,VRF機制正是在該dev_hard_xmit回撥函式中實現了真正的路由查詢,在dev_hard_xmit回撥中真正做事的函式是vrf_process_v4_outbound:
static netdev_tx_t vrf_process_v4_outbound(struct sk_buff *skb,
struct net_device *vrf_dev)
{
struct iphdr *ip4h = ip_hdr(skb);
int ret = NET_XMIT_DROP;
struct flowi4 fl4 = {
/* needed to match OIF rule */
// 這個會讓l3mdev_fib_rule_match定位到正確的路由表
.flowi4_oif = vrf_dev->ifindex,
.flowi4_iif = LOOPBACK_IFINDEX,
.flowi4_tos = RT_TOS(ip4h->tos),
.flowi4_flags = FLOWI_FLAG_ANYSRC | FLOWI_FLAG_SKIP_NH_OIF,
.daddr = ip4h->daddr,
};
struct net *net = dev_net(vrf_dev);
struct rtable *rt;
// 真實查路由
rt = ip_route_output_flow(net, &fl4, NULL);
...
// 真實發送skb
ret = vrf_ip_local_out(dev_net(skb_dst(skb)->dev), skb->sk, skb);
...
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
整個流程就這樣結束了!
到此為止,我可以給出一幅整個的圖景了,結合原始碼觀摩,定有收穫:
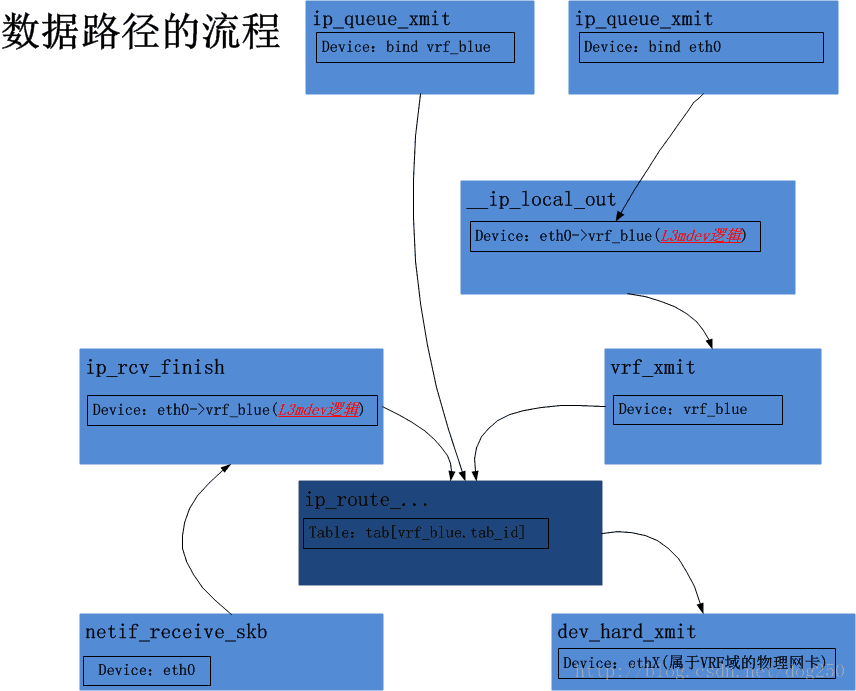
關於Linux VRF的小Trick
突然覺得Linux自2.6.32以來真的更新了太多,和本文相關的,有兩個問題,首先是local路由表的問題,其次是TCP Listener的問題,和本文不相關的還有一個命令列問題,聽我細說。
Local路由表問題
早在幾年前的時候,我曾經抱怨說:
資料包來了之後首先要看看是不是本地接收的
要想理解這個,首先你得知道Linux系統中策略路由表匹配的原理。很簡單,就是一個典型的switch-case語句:
switch elements:
case rule1:
table=tab1
break;
case rule1:
table=tab1
//fall through; 即匹配下一條rule
case rule1:
table=tab1
break;
default:
unreachable? // 或者任意別的什麼...- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
這在Linux的網路協議棧實現中體現為要先強制查詢Local路由表,然後再查Main路由表…這個順序並不意味著什麼大不了的事,關鍵在於,曾經Local路由表全系統僅此一張,因此,如果本機的應用層有兩個屬於不同VRF域但是卻偵聽同一個IP地址的服務,勢必會造成混亂,早先的系統中,唯一的Local路由表是IP路由系統第一個無條件要查詢的,它可以繞過任何其它的路由判斷,包括策略路由表,即Local路由表必須在策略路由表之前被匹配,如果不成功才Fall through到後面的路由表。
然而,在引入VRF後,Local表不再是全域性唯一的了,每一個VRF域都有一張Local路由表,當你把一個網絡卡新增進一個VRF域的時候,此網絡卡相關的Local路由將全部重置到此VRF域的Local路由表中。
然而,全域性來看,系統中還是會有一張Local路由表,它看起來在所有rule匹配之前被匹配,不過事情起了變化。當你看到下面的策略路由表時:
0: from all lookup local
1000: from all lookup [l3mdev-table]
32766: from all lookup main
32767: from all lookup default- 1
- 2
- 3
- 4
你可通過下面的命令刪除Local表(請注意,這在低版本的核心以及iproute2中是不允許的):
ip rule del pref 0- 1
但為了避免你使用的ssh即時中斷(其實是為了做到無縫切換),你要在del之前先add,因此整個切換過程的指令碼變成了下面的樣子:
ip rule add pref 30000 table local
ip rule del pref 0- 1
- 2
即你在新增一條策略路由前,必須先新增一條。
這也是人之常情了。然後,你會發現,事情的局面變成了下面的樣子(當你再次執行ip rule ls時):
1000: from all lookup [l3mdev-table]
30000: from all lookup local
32766: from all lookup main
32767: from all lookup default - 1
- 2
- 3
- 4
瞭解了這個事實之後,我們明白了,解決之道當然是隔離。看懂了這個ip rule ls的顯式,我們的心情安頓了,是的,Linux的VRF做到了完全的三層隔離。
TCP Listener問題
對於本地始發的流量,我們知道,必須要為其通過顯式的setsockopt呼叫繫結一個VRF裝置才能終安,道理是這樣,事實也是這樣。
由於繫結VRF虛擬網絡卡裝置的setsockopt是針對特定socket的,如果我們僅僅針對Listener socket做了這樣的setsocketopt(事實上我們也僅僅能這麼做),那麼對於別的那些被這個Listener socket給Accept的那些socket,誰來負責呢(需要一種機制,讓所有相關的socket都繫結VRF網絡卡)?
嗯,我們實在沒有必要在accept返回後為每一個返回的client socket都去bind一個VRF device,系統可以自動做到這一點:
sysctl -w net.ipv4.tcp_l3mdev_accept=0- 1
OK,這就好了!
該核心引數的另一個作用是,自動識別那些從隸屬於某個VRF域的網絡卡上收到的資料包所屬的具體VRF域
VRF的命令列
不像net namespcace那樣,可以在任意namespace執行網路程式,比如:
ip netns exec ns1 ping 1.1.1.1- 1
它的意思是,在名稱空間ns1執行ping 1.1.1.1這個命令,然而我無法說出下面的祈使句:
在VRF vrf-blue這個虛擬路由器裡執行ssh [email protected]
至少,目前為止我沒有看到有類似:
ip vrf exec vrf-blue ssh [email protected]- 1
這樣的命令列。如果有了,請告訴我…
相關推薦
Linux VRF Virtual Routing Forwarding 的原理和實現
動機 明天,是2017年9月24日,兩年前的明天,我從上海第一次來到深圳參加面試,兩年前的今天,此時我還在上海虹橋機場等候延誤的飛機,兩年前的今晚,我在深圳南山區南新路片區徘徊,企圖能在南方城市找到一家東北燒烤,並且欣賞這座城市(最終我找到了!),兩年前的明晚,我喝了一瓶750ml的威士忌,次日返回
Linux VRF(Virtual Routing Forwarding)的原理和實現
動機 明天,是2017年9月24日,兩年前的明天,我從上海第一次來到深圳參加面試,兩年前的今天,此時我還在上海虹橋機場等候延誤的飛機,兩年前的今晚,我在深圳南山區南新路片區徘徊,企圖能在南方城市找到一家東北燒烤,並且欣賞這座城市(最終我找到了!),兩年前的明晚,我喝
動態替換Linux核心函數的原理和實現
c函數 路徑 pla ges sta images 語句 堆棧 mit 轉載:https://www.ibm.com/developerworks/cn/linux/l-knldebug/ 動態替換Linux核心函數的原理和實現 在調試Linux核心模塊時,有時需要
Linux時間子系統之六:高精度定時器(HRTIMER)的原理和實現
3.4 size 屬於 running return repr 而是 復雜度 ctu 上一篇文章,我介紹了傳統的低分辨率定時器的實現原理。而隨著內核的不斷演進,大牛們已經對這種低分辨率定時器的精度不再滿足,而且,硬件也在不斷地發展,系統中的定時器硬件的精度也越來越高,這也給
API Hook基本原理和實現
use 概率 缺省 後綴 origin gif object cati mov API Hook基本原理和實現 2009-03-14 20:09 windows系統下的編程,消息message的傳遞是貫穿其始終的。這個消息我們可以簡單理解為一個有特定
jsonp的原理和實現
pty 方法 www 三方庫 .get 設定 部分 nbsp blog 什麽是JSONP? javascript高級程序設計中是這樣介紹jsonp的: jsonp是JSON with padding(填充式JSON或參數式JSON )的簡寫,是應用JSON的一種新方法,在
詳解PHP文件下載的原理和實現
利用 ring php代碼 按鈕 功能 span 所有 編號 變量 通常文件下載過程是十分簡單的,建立一個鏈接指向到目標文件就可以了。例如下面的鏈接: XML/HTML代碼 <a href=http://www.xxx.com/xxx.rar>點擊下載文件&
慕課網 星級評分原理和實現(上)
方法 click down cti 原理 als row rep ava 源碼下載 <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8">
express 如何上傳文件的原理和實現
rip .net 文件 note receiving 過濾 console 執行 sage express 上傳文件的原理和實現 原理 formidable multer COS 1.原理 1.1 要想了解express上傳 我們先看看 nodejs原生上傳是怎麽實現的
CSS 0.5px 細線邊框的原理和實現方式
bottom back 先決條件 device min style ati 而且 origin 細線邊框的具體實現方法有:偽元素縮放或漸變,box-shadow模擬,svg畫線,border-image裁剪等。要實現小於1px的線條,有個先決條件:屏幕的分辨率要足夠高,
[NLP] TextCNN模型原理和實現
puts 窗口 ima () weight ica alt fine NPU 1. 模型原理 1.1 論文 Yoon Kim在論文(2014 EMNLP) Convolutional Neural Networks for Sentence Classification
JAVA 動態代理原理和實現
ror binary lose ole jdk 動態代理 參數 try lob rac 在 Java 中動態代理和代理都很常見,幾乎是所有主流框架都用到過的知識。在面試中也是經常被提到的話題,於是便總結了本文。 Java動態代理的基本原理為:被代理對象需要實現某個接口(這是
登入許可權驗證之token驗證的原理和實現
原理 後端不在儲存認證資訊,而是在使用者登入的時候生成一個token,然後返回給前端,前端進行儲存,在需要進行驗證的時候將token一併傳送到後端,後端進行驗證 加密的方式:對稱加密和非對稱加密,對稱加密指的是加密解密使用同一個金鑰,非對稱加密使用公鑰和私鑰,加密用私鑰加密,解密用公鑰解密
登入的許可權驗證session的原理和實現
儲存方式原理: 登入成功後,儲存登入資訊到檔案/資料庫種,同時儲存建立時間和過期時間,下次驗證的時候取出來做驗證 使用express-session中介軟體來進行session的操作 1.安裝express-session npm install express-sess
詳解ROI Align的基本原理和實現細節
ROI Align是在Mask-RNN這篇論文裡提出的一種區域特徵聚集方式,很好地解決了ROI Pooling操作中兩次量化造成的區域不匹配(mis-alignment)的問題。實驗顯示,在檢測任務中將ROI Pooling替換為ROI Align可以提升檢測模型的準確性。 1、ROI Pool
Taglib原理和實現 第六章:標籤內常用方法總結
1。支援el表示式: import org.apache.taglibs.standard.lang.support.ExpressionEvaluatorManager; private Object value = null; this.valu
Taglib原理和實現 第五章:再論支援El表示式和jstl標籤
1。問題:你想和jstl共同工作。比如,在用自己的標籤處理一些邏輯之後,讓jstl處理餘下的工作。 2。看這個jsp例子: .... <% String name="diego"; request.setAttribute("name",name); %> <c:out&
Taglib 原理和實現:第四章 迴圈的Tag
1。問題:在request裡的 People 物件,有個屬性叫 men ,men 是一個Collection ,有許多個man 。現在,把 collection裡的man的名字都顯示出來 顯然,這是一個巢狀T
Taglib 原理和實現:第三章 tag之間的巢狀和屬性讀取
1。問題:在request裡有一個 Man 物件,它有兩個屬性:name和age。現在,我們想用一個巢狀的tag,父tag取得物件,子tag取得name屬性並顯示在頁面上。例如,它的形式如下: <diego:with object="${Man}"&g