
運維架構服務監控Open-Falcon
一、 介紹
監控系統是整個運維環節,乃至整個產品生命週期中最重要的一環,事前及時預警發現故障,事後提供翔實的資料用於追查定位問題。監控系統作為一個成熟的運維產品,業界有很多開源的實現可供選擇。當公司剛剛起步,業務規模較小,運維團隊也剛剛建立的初期,選擇一款開源的監控系統,是一個省時省力,效率最高的方案。之後,隨著業務規模的持續快速增長,監控的物件也越來越多,越來越複雜,監控系統的使用物件也從最初少數的幾個SRE,擴大為更多的DEVS,SRE。這時候,監控系統的容量和使用者的“使用效率”成了最為突出的問題。
監控系統業界有很多傑出的開源監控系統。我們在早期,一直在用zabbix,不過隨著業務的快速發展,以及網際網路公司特有的一些需求,現有的開源的監控系統在效能、擴充套件性、和使用者的使用效率方面,已經無法支撐了。
因此,我們在過去的一年裡,從網際網路公司的一些需求出發,從各位SRE、SA、DEVS的使用經驗和反饋出發,結合業界的一些大的網際網路公司做監控,用監控的一些思考出發,設計開發了小米的監控系統:open-falcon。
二、 特點
1、強大靈活的資料採集:自動發現,支援falcon-agent、snmp、支援使用者主動push、使用者自定義外掛支援、opentsdb data model like(timestamp、endpoint、metric、key-value tags)
2、水平擴充套件能力:支援每個週期上億次的資料採集、告警判定、歷史資料儲存和查詢
3、高效率的告警策略管理:高效的portal、支援策略模板、模板繼承和覆蓋、多種告警方式、支援callback呼叫
4、人性化的告警設定:最大告警次數、告警級別、告警恢復通知、告警暫停、不同時段不同閾值、支援維護週期
5、高效率的graph元件:單機支撐200萬metric的上報、歸檔、儲存(週期為1分鐘)
6、高效的歷史資料query元件:採用rrdtool的資料歸檔策略,秒級返回上百個metric一年的歷史資料
7、dashboard:多維度的資料展示,使用者自定義Screen
8、高可用:整個系統無核心單點,易運維,易部署,可水平擴充套件
9、開發語言: 整個系統的後端,全部golang編寫,portal和dashboard使用python編寫。
三、 架構
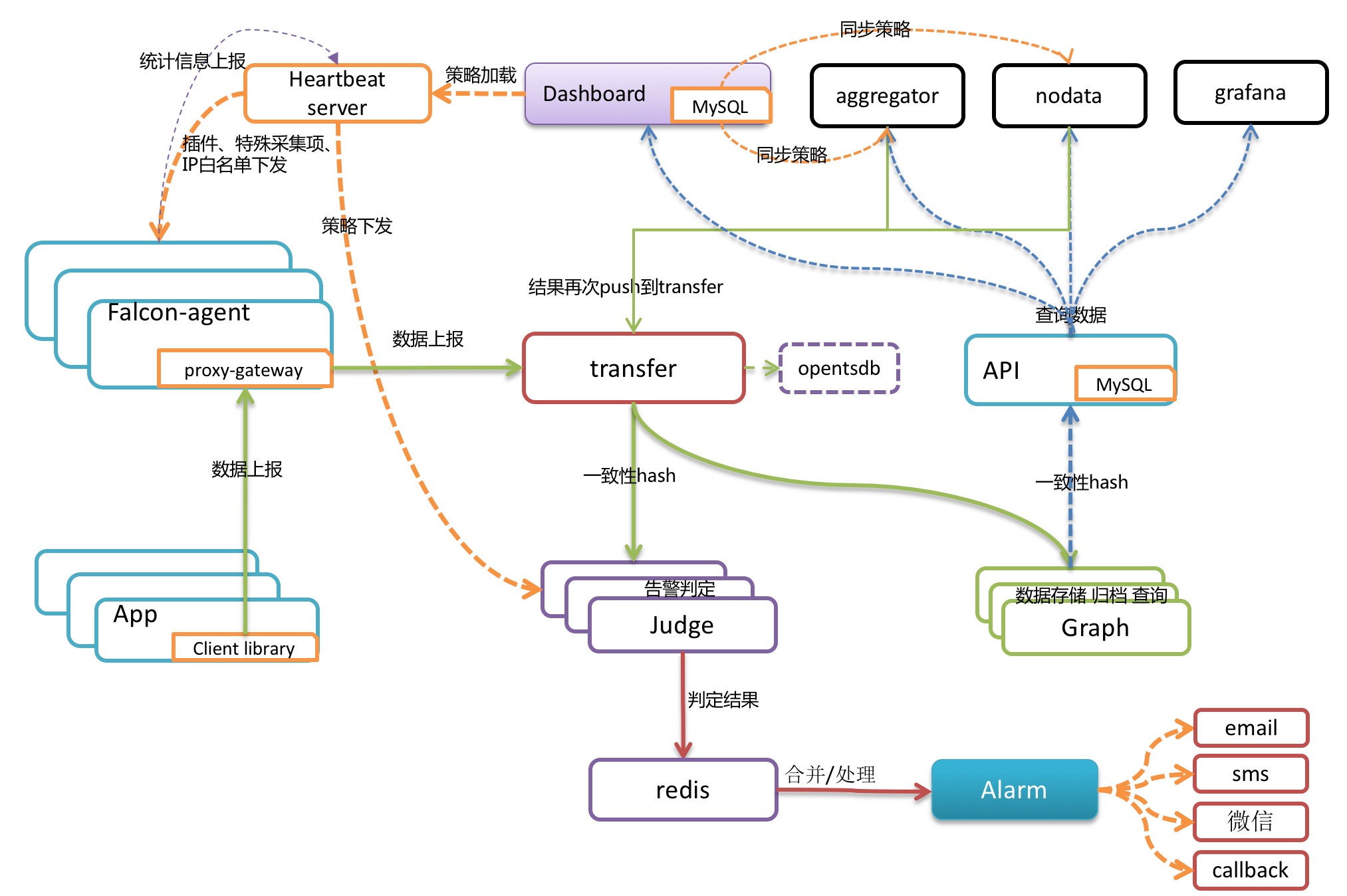
每臺伺服器,都有安裝falcon-agent,falcon-agent是一個golang開發的daemon程式,用於自發現的採集單機的各種資料和指標,這些指標包括不限於以下幾個方面,共計200多項指標。
CPU相關
磁碟相關
IO
Load
記憶體相關
網路相關
埠存活、程序存活
ntp offset(外掛)
某個程序資源消耗(外掛)
netstat、ss 等相關統計項採集
機器核心配置引數
只要安裝了falcon-agent的機器,就會自動開始採集各項指標,主動上報,不需要使用者在server做任何配置(這和zabbix有很大的不同),這樣做的好處,就是使用者維護方便,覆蓋率高。當然這樣做也會server端造成較大的壓力,不過open-falcon的服務端元件單機效能足夠高,同時都可以水平擴充套件,所以自動多采集足夠多的資料,反而是一件好事情,對於SRE和DEV來講,事後追查問題,不再是難題。
另外,falcon-agent提供了一個proxy-gateway,使用者可以方便的通過http介面,push資料到本機的gateway,gateway會幫忙高效率的轉發到server端。
四、 資料模型
Data Model是否強大,是否靈活,對於監控系統使用者的“使用效率”至關重要。比如以zabbix為例,上報的資料為hostname(或者ip)、metric,那麼使用者新增告警策略、管理告警策略的時候,就只能以這兩個維度進行。舉一個最常見的場景:
hostA的磁碟空間,小於5%,就告警。一般的伺服器上,都會有兩個主要的分割槽,根分割槽和home分割槽,在zabbix裡面,就得加兩條規則;如果是hadoop的機器,一般還會有十幾塊的資料盤,還得再加10多條規則,這樣就會痛苦,不幸福,不利於自動化(當然zabbix可以通過配置一些自動發現策略來搞定這個,不過比較麻煩)。
五、 資料收集
transfer,接收客戶端傳送的資料,做一些資料規整,檢查之後,轉發到多個後端系統去處理。在轉發到每個後端業務系統的時候,transfer會根據一致性hash演算法,進行資料分片,來達到後端業務系統的水平擴充套件。
transfer 提供jsonRpc介面和telnet介面兩種方式,transfer自身是無狀態的,掛掉一臺或者多臺不會有任何影響,同時transfer效能很高,每分鐘可以轉發超過500萬條資料。
transfer目前支援的業務後端,有三種,judge、graph、opentsdb。judge是我們開發的高效能告警判定元件,graph是我們開發的高效能資料儲存、歸檔、查詢元件,opentsdb是開源的時間序列資料儲存服務。可以通過transfer的配置檔案來開啟。
transfer的資料來源,一般有三種:
1、falcon-agent採集的基礎監控資料
2、falcon-agent執行使用者自定義的外掛返回的資料
3、client library:線上的業務系統,都嵌入使用了統一的perfcounter.jar,對於業務系統中每個RPC介面的qps、latency都會主動採集並上報
說明:上面這三種資料,都會先發送給本機的proxy-gateway,再由gateway轉發給transfer。
基礎監控是指只要是個機器(或容器)就能加的監控,比如cpu mem net io disk等,這些監控採集的方式固定,不需要配置,也不需要使用者提供額外引數指定,只要agent跑起來就可以直接採集上報上去; 非基礎監控則相反,比如埠監控,你不給我埠號就不行,不然我上報所有65535個埠的監聽狀態你也用不了,這類監控需要使用者配置後才會開始採集上報的監控(包括類似於埠監控的配置觸發類監控,以及類似於mysql的外掛指令碼類監控),一般就不算基礎監控的範疇了。
六、 報警
報警判定,是由judge元件來完成。使用者在web portal來配置相關的報警策略,儲存在MySQL中。heartbeat server 會定期載入MySQL中的內容。judge也會定期和heartbeat server保持溝通,來獲取相關的報警策略。
heartbeat sever不僅僅是單純的載入MySQL中的內容,根據模板繼承、模板項覆蓋、報警動作覆蓋、模板和hostGroup繫結,計算出最終關聯到每個endpoint的告警策略,提供給judge元件來使用。
transfer轉發到judge的每條資料,都會觸發相關策略的判定,來決定是否滿足報警條件,如果滿足條件,則會發送給alarm,alarm再以郵件、簡訊、米聊等形式通知相關使用者,也可以執行使用者預先配置好的callback地址。
使用者可以很靈活的來配置告警判定策略,比如連續n次都滿足條件、連續n次的最大值滿足條件、不同的時間段不同的閾值、如果處於維護週期內則忽略 等等。
另外也支援突升突降類的判定和告警。
七、 API
到這裡,資料已經成功的儲存在了graph裡。如何快速的讀出來呢,讀過去1小時的,過去1天的,過去一月的,過去一年的,都需要在1秒之內返回。
這些都是靠graph和API元件來實現的,transfer會將資料往graph元件轉發一份,graph收到資料以後,會以rrdtool的資料歸檔方式來儲存,同時提供查詢RPC介面。
API面向終端使用者,收到查詢請求後,會去多個graph裡面,查詢不同metric的資料,彙總後統一返回給使用者。
八、 面板
九、 儲存
對於監控系統來講,歷史資料的儲存和高效率查詢,永遠是個很難的問題!
資料量大:目前我們的監控系統,每個週期,大概有2000萬次資料上報(上報週期為1分鐘和5分鐘兩種,各佔50%),一天24小時裡,從來不會有業務低峰,不管是白天和黑夜,每個週期,總會有那麼多的資料要更新。
寫操作多:一般的業務系統,通常都是讀多寫少,可以方便的使用各種快取技術,再者各類資料庫,對於查詢操作的處理效率遠遠高於寫操作。而監控系統恰恰相反,寫操作遠遠高於讀。每個週期幾千萬次的更新操作,對於常用資料庫(MySQL、postgresql、mongodb)都是無法完成的。
高效率的查:我們說監控系統讀操作少,是說相對寫入來講。監控系統本身對於讀的要求很高,使用者經常會有查詢上百個meitric,在過去一天、一週、一月、一年的資料。如何在1秒內返回給使用者並繪圖,這是一個不小的挑戰。
open-falcon在這塊,投入了較大的精力。我們把資料按照用途分成兩類,一類是用來繪圖的,一類是使用者做資料探勘的。
對於繪圖的資料來講,查詢要快是關鍵,同時不能丟失資訊量。對於使用者要查詢100個metric,在過去一年裡的資料時,資料量本身就在那裡了,很難1秒之類能返回,另外就算返回了,前端也無法渲染這麼多的資料,還得采樣,造成很多無謂的消耗和浪費。我們參考rrdtool的理念,在資料每次存入的時候,會自動進行取樣、歸檔。我們的歸檔策略如下,歷史資料儲存5年。同時為了不丟失資訊量,資料歸檔的時候,會按照平均值取樣、最大值取樣、最小值取樣存三份。