
阿里自然語言處理部總監分享:NLP技術的應用及思考
本文整理自阿里巴巴iDST自然語言處理部總監郎君博士的題為“NLP技術的應用及思考”的演講。本文從NLP背景開始談起,重點介紹了AliNLP平臺,接著分享了NLP相關的應用例項,最後對NLP的未來進行了思考。
背景介紹
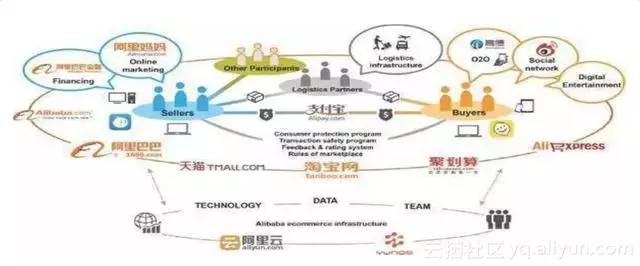
阿里巴巴的生態系統下面有很多的計算平臺,上面有各種各樣的業務層,最中間是買家和賣家之間包括銷售、支付等等之間的關係,外面建了一圈從娛樂到廣告到金融到購物到物流等等各方面這樣一個生態,中間有非常多的資料能夠關聯起來,所以對於阿里巴巴而言,這個圖可以非常簡練的概括我們在做什麼,中間是最重要的資料,下面資料包含了最核心的也是阿里巴巴最早起家的來自於電商的資料,所以電商對於我們而言是非常重要的,後來又擴展出了金融、菜鳥物流、健康和娛樂,比如我們有大文娛事業群,去做了優酷土豆等各種各樣的資料,資料當中包含了很多的文字。
比如阿里的電商平臺裡面有數十億的商品,每一個商品都包含詳細的標題、副標題、詳情頁、評價區,甚至問答區,這裡面的資訊構成了一個非常豐富的商品資訊,還有上億的文章,阿里在兩年前開始進入內容時代,比如現在各種各樣的內容營銷、直播還有一些問答的場景圓桌等等,文章裡面可以包含各種各樣的標題、正文和評論等大量的資料,這只是電商的例子,還有金融、物流、健康、娛樂,加在一起還會有海量的資料,就會孕育出大量文字處理的工作需求。
自然語言處理是什麼呢?
-
語言是生物同類之間由於溝通需要而制定的具有統一編碼解碼標準的聲音(影象)指令。包含手勢、表情、語音等肢體語言,文字是顯像符號。
-
自然語言通常是指一種自然地隨文化演化的語言。例如英語、漢語、日語等。有別於人造語言,例如世界語、程式語言等。
-
自然語言處理包括自然語言理解和自然語言生成。自然語言理解是將自然語言變成計算機能夠理解的語言,及非結構化文字轉變為結構化資訊。
-
NLP的 四大經典“AI 完全 ” 難題:問答、複述、文摘、翻譯,只要解決其中一個,另外三個就都解決了。問答就是讓機器人很開放的回答你提的各種各樣問題,就像真人一樣;複述是讓機器用另外一種方式表達出來;文摘就是告訴你一篇很長的文章,讓你寫一個100字的文摘,把它做出來是非常難做的;翻譯也是很困難的,英語思維方式和中文思維方式轉換過來,中間會涉及到很多複雜的問題。
阿里巴巴需要什麼樣的自然語言處理技術?
阿里的生態是非常複雜的,我們不能用一個簡單的自然語言處理技術去解決所有的問題,以往自然語言處理是比較簡單的,甚至一個詞表放上去就解決所有問題了,隨著電商生態的擴充套件,就需要非常複雜的技術,所以我們需要完備且高效能的自然語言處理技術,高效能體現在演算法精度還有執行效率,IDST的定位如下:
-引領技術前沿-趕超市場最佳的競爭者,完備和完善AliNLP平臺的技術體系及服務能力;
-賦能核心業務-幫助核心業務快速成長,尋找和解決業務方的最痛點;
-創造商業機會-創造看似不可能的商業技術,深度理解語言,深度理解需求,變革產品體驗。
AliNLP 自然語言技術平臺
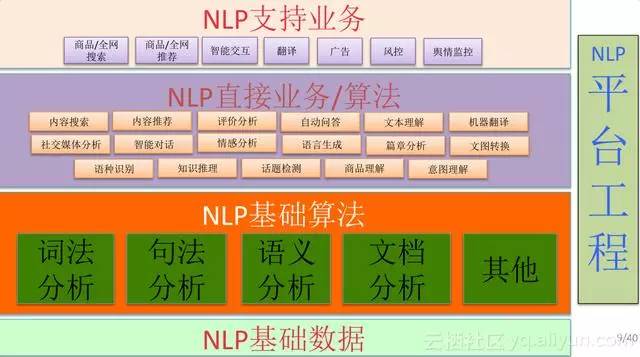
圖為我們整個自然語言處理平臺最核心的框圖,底層是各種各樣的基礎資料,中間層包含基本的詞法分析、句法分析、語義分析、文件分析,還有其他各種各樣跟深度學習相關的一些技術;上層是自然語言處理能夠直接掌控和變革的一些演算法和業務,比如內容搜尋、內容推薦、評價、問答、文摘、文字理解等等一系列問題,最上層我們直接支援大業務的單元,比如商品搜尋、推薦、智慧互動、翻譯。商業翻譯和普通機器翻譯是不一樣的,還有廣告、風控、輿情監控等等。這個層次結構是比較傳統的方式,為了讓我們平臺具有非常好的落地能力,右邊有一列平臺工程,專門解決如何讓演算法能夠快速的用到業務裡面去。
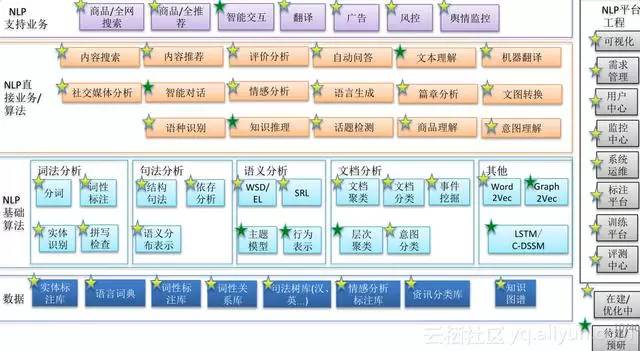
將核心框圖細化,底層有各種各樣的資料,比如實體庫、源學辭典、詞性標註庫、詞性關係庫、句法樹庫、情感分析標註庫,還有情感詞典、資訊庫、圖譜等等。這些是詞法分析,包括分詞、詞性、實體識別,拼寫檢查等一些基礎的元件,句法分析有結構句法分析、依存句法分析、語義分佈表示等等,還有語義分析,包含詞義消歧、語義角色標註、主題模型、行為表示等。還有文件分析,比如普通的文件聚類、文件分類、事件挖掘、層次聚類和意圖分類,其他部分就是我們嘗試比較多的偏深度學習的一些自然語言演算法。
右邊的平臺工程我們做了很多嘗試。團隊經過幾年的發展,不停的去反思如何把我們的技術快速的跟業務對接起來,經過不停的嘗試之後,我們做了很多的視覺化、需求管理、使用者中心、監控中心、系統運維,還有自動的標註平臺、訓練平臺、評測中心等等,經過一系列的封裝,才會使得平臺越來越完善。
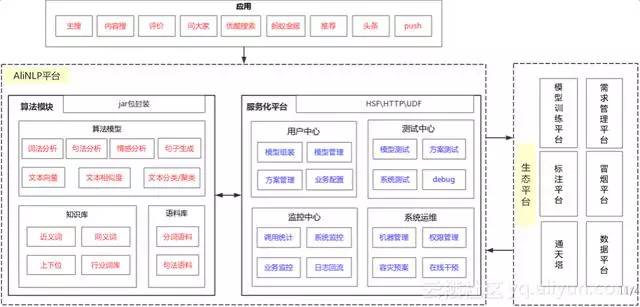
圖為阿里AliNLP系統架構圖,左邊是演算法模組,包括知識庫、語料庫、演算法模型,中間是服務化平臺,比如我們的服務分為線上服務和離線服務。離線服務有阿里巴巴最大的計算平臺ODPS,裡面做了很多這方面的UDF操作,線上有HSF和HTTP服務,可以很好的對接各種各樣的相關服務方;中間有使用者中心、監控中心、測試中心、系統運維等比較複雜的一套體系。右邊是我們對接的一套生態平臺,上面可以通過我們的介面層直接對接各種各樣的應用。我們迭代了很多輪才出現這樣的結構,現在大概支援30多個業務方,平均每天的呼叫量在數百億規模。
AliNLP平臺核心價值
AliNLP平臺核心價值就是解耦。我們希望通過做這樣一個平臺,去面對整個阿里巴巴的生態系統:
-
演算法超市。我們希望平臺是NLP演算法超市,業務方可以清晰看到分門別類的NLP演算法;
-
工程小白。我們希望平臺解決一切工程問題,演算法工程師可以是工程小白只需專注演算法研發;
-
系統生態。對於系統,以此為中心形成一個系統生態體系,從各個環節切入服務NLP演算法和業務;
-
服務底線。對於產品運營,平臺只做底層模型的服務輸出,不直接對接業務。
經過各種各樣的迭代、打磨、思考、反思,5月初會發布2.0版本,我們希望做持續的改進。我們平臺中最核心的三個概念如下:
1.模型:最基本的演算法邏輯複用單元,如果用演算法超市的概念解釋,模型就是原材料,模型是演算法工程師的主要產出成果;
2.方案:是多個模型的組合,用於真正解決某一方向的具體問題,類似於待售的超市商品。方案是業務、演算法的結合之處,我們負責“演算法售賣”的同學會應用手頭已有的模型通過不同的組合配置,產生出不同的商品供最終業務方的使用者使用;
3.場景:是多個方案在線上部署的最終形態,是最終服務的提供者,是業務方真正使用我們的演算法大禮包的地方。按目前的設計,不同的業務方可以在相互隔離的多個場景中使用演算法服務。
只有理解這三個概念,才會知道平臺怎麼去很好的使用。
NLP演算法舉例
下面對我們的演算法做一些比較簡單的舉例。
1.詞法分析(分詞、詞性、實體):
–演算法:基於Bi-LSTM-CRF演算法體系,以及豐富的多領域詞表
–應用:優酷、YunOS、螞蟻金服、推薦演算法、資訊搜尋等
2.句法分析(依存句法分析、成分句法分析):
–演算法:Shift-reduce,graph-based,Bi-LSTM
–新聞領域、商品評價、商品標題、搜尋Query
–應用:資訊搜尋、評價情感分析
3.情感分析(情感物件、情感屬性、情感屬性關聯):
–演算法:情感詞典挖掘,屬性級、句子級、篇章級情感分析
–應用:商品評價、商品問答、品牌輿情、網際網路輿情
4.句子生成(句子可控改寫、句子壓縮):
–演算法:Beam Search、Seq2Seq+Attention
–應用:商品標題壓縮,資訊標題改寫,PUSH訊息改寫
5.句子相似度(淺層相似度、語義相似度):
–演算法:Edit Distance,Word2Vec,DSSM
–應用:問大家相似問題、商品重發檢測、影視作品相似等
6.文字分類/聚類(垃圾防控、資訊聚合):
–演算法:ME,SVM,FastText
–應用:商品類目預測、問答意圖分析、文字垃圾過濾、輿情聚類、名片OCR後語義識別等
7.文字表示(詞向量、句子向量、篇章向量、Seq2Seq):
–Word2Vec、LSTM、DSSM、Seq2Seq為基礎進行深入研究
8.知識庫
–資料規模:電商同義詞,通用同義詞,電商上下位,通用上下位,領域詞庫(電商詞、娛樂領域詞、通用實體詞),情感詞庫
–挖掘演算法:bootstrapping,click-through mining,word2vec,k-means,CRF
–應用:語義歸一、語義擴充套件、Query理解、意圖理解、情感分析
9.語料庫
–分詞、詞性標註資料,依存句法標註資料
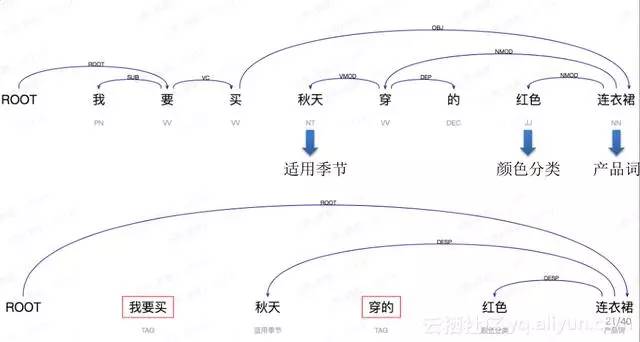
有這樣一句話叫“我要買秋天穿的紅色連衣裙”,這句是電商領域中比較常見的,詞法分析結果會把中間“我要”拆開。分詞要分的很準,它不是每個單字都是一個詞,比如秋天是一個詞,連衣裙是一個詞。下面這一層標籤是對應的詞性。上面這一層就是句子樹型結構,它會比較深入的把句子比較深度的結構化。只有把它結構化之後才能導到資料庫裡面去,才能做後續的各種機器學習研究和應用,這種叫結構句法分析。

對於電商而言,光有句法分析是不夠的,比如我要知道秋天的含義是說這是個適用季節,紅色是一個顏色分類,連衣裙是一個產品,要做到這一步才會使得真正在電商裡面用起來。
比如我們用的是通用領域依存分析器,我們針對商品標題決定某一個依存句法分析器,假設某一個商品標題寫的是“我要買秋天穿的紅色連衣裙”,只需要把“秋天”、“紅色”、“連衣裙”這幾個關鍵的成分標出來,“我要買”和“穿的”對電商而言是沒有意義的,但會去做進一步的組合。
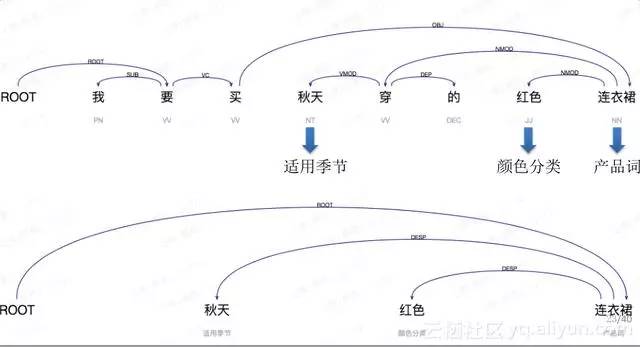
如果這個句子是一個query,對於某些核心成分一點都不需要,完全不用看,直接會把它輸出“秋天”、“紅色”、“連衣裙”三個串,中間依存關係標出就可以了。這樣可以做很好的資訊凝練。這是我們針對三種不同型別的文字做的很深入的底層自然語言處理分析。
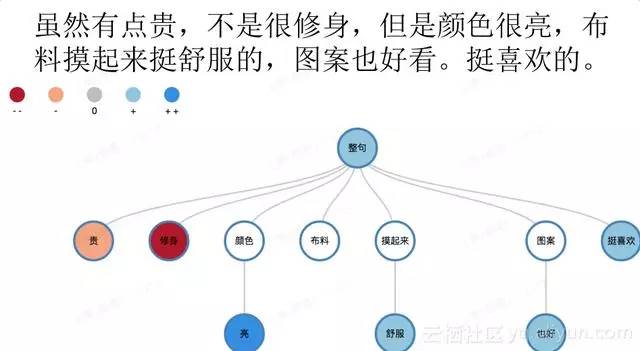
這個例子是一個買家對於某一個商品寫的一個評論,“雖然有點貴,不是很修身,但是顏色很亮,布料摸起來挺舒服的,圖案也好看。挺喜歡的。”,上圖是我們的情感分析結果,我們情感分析不但要知道整句的資訊,比如說整句有藍色、淡藍色,淡藍色表示情感是正向的,整個句子表達的是一個比較褒義的結果,但不是非常滿意。
再下面我們做的更深入一點,比如說貴、修身、顏色等等,做了很細粒度的一個拆解,這種叫屬性級的情感分析。情感詞比如說“貴”它是一個形容詞,貴表達的是相對的關係,有時候說黃金很貴,這時就是一個褒義。所以這個詞語非常複雜,不同環境下褒貶不一。如修身,這個平臺裡面表達修身是一個很嚴重的反向關係,所以我們就把它識別出來是個很紅色的關係,只要經過很深度的細緻分析之後,後面可以做各種各樣的玩法。
應用例項
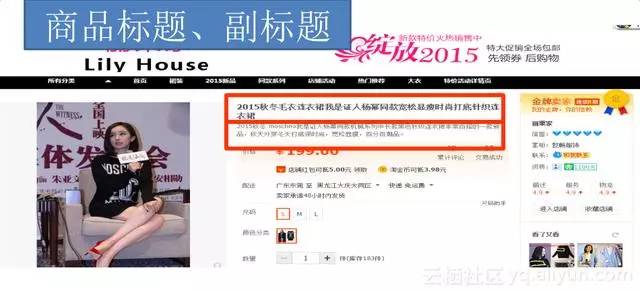
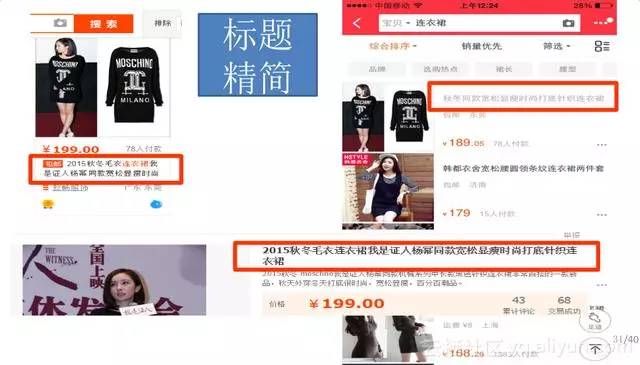
圖中顯示商品標題和副標題。 “2015年秋冬毛衣連衣裙我是證人楊冪同款寬鬆顯瘦時尚打底針織連衣裙”,它不是一個自然語言的原句子,是一堆詞語拼湊在一起的,副標題就自然一點。因為搜尋引擎以關鍵詞為核心演算法,關鍵詞堆砌的話搜尋結果不會往前面排,銷量就不好,所以標題就變成這個樣子了。而副標題沒有應用這種演算法,副標題不進索引庫,不能搜尋,只是一個營銷的額外宣傳語。所以電商的自然語言處理是很有意思的。

對標題做深度理解和分析的時候,我們知道商品的產品詞、款式、材質、風格、服務營銷、適用季節等,做到這種結構化後,就可以把一個文字串變成一個數據庫。

這個擺件的標題也可以做很深入的分析,也可以變成一長串結果,如果你要建一個電子商務搜尋引擎的話,或者電子商務推薦引擎的話,只有做到這一步,才會使你的引擎更加智慧。

標題分析主要分四步:
第一步先做分詞。把第一行變成第二行,打空格用了很多演算法、詞表、人工、優化的思路;
第二步是實體打標。需要知道每個詞語是什麼含義,粉紅大布娃娃是個品牌,泡泡袖是個袖型等等,這樣你的搜尋引擎就更加智慧一點;
第三步是熱度計算。把熱度分數識別出來,因為串裡面每個詞不是等價的,有些重要性非常高,有些重要性非常低;
第四步是中心識別。我們用依存句法分析方法來做,表達這個句子的最核心關係就是春裝連衣裙,這裡面可以做進一步的簡化,選取合適的某一個維度的資訊。這樣,你的資料庫就非常好了,可以做很多深入的工作。
如果買家寫的原始標題非常長,在PC上顯示一個標題,但是在手機上顯示一長串的時候,就會把標題按照字數限制截斷。你會發現很多截斷本來不應該,截斷之後末尾那一串資訊其實也是蠻關鍵的,我們把它變成如圖一種關係,當買家來看商品資訊的時候,在窄屏的區域裡面能夠很好的顯示出來,所以就會使得我們的銷量包括購買體驗都會提升。
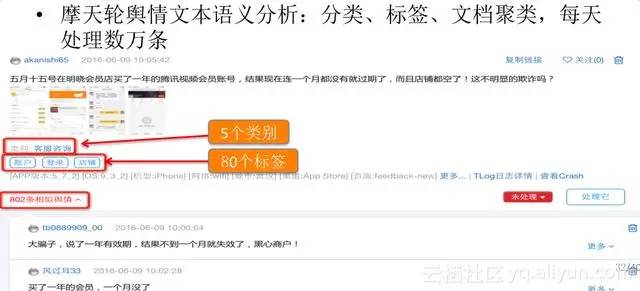
關於輿情文字分析,我們有文字的分類、標籤和文件聚類技術。假如你在手機淘寶app評價寫了一堆東西,就進入了我們的流程。我們的系統叫摩天輪,會自動的把你寫的每一條評論做各種各樣的分析和處理,包括聚類的和標籤的很細粒度的解析。
商品評價
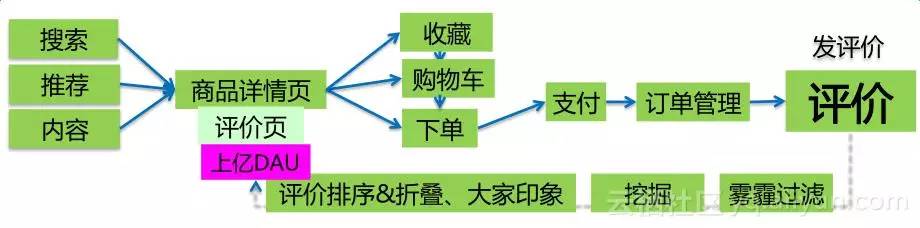
有關商品的評價,我們積累了幾百億條評論,這是非常海量的一個數據庫。它通過商品的搜尋推薦還有文章的引導,到商品詳情頁之後,有上億的人每一天在看評價,通過看詳情頁之後,你可以去做要麼收藏,要麼放購物車,要麼直接購買的決策,後面才有支付訂單管理,最後還有評價。寫下來評價之後,評價會經過我們的過濾挖掘和展現,再回到詳情頁裡面來,這就是一個閉環。真實評價對購物決策有重要作用,評價作為淘寶最大的UGC,富含對商品的體驗和知識,瀏覽評價與否對收藏、加購、下單、客單價均有顯著影響。

上圖為商品詳情頁,下面是正常寫的評論,我們會在上面做大家印象,會把所有的評論做一個綜合的摘取和總結,點選某一個,下面就會變成一堆相關文字篩選出來,並且把那一段描述的文字高亮。
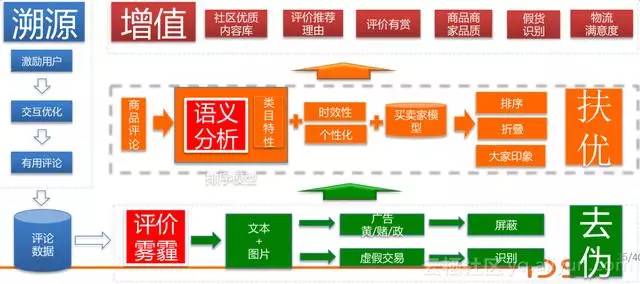
圖為我們的演算法總架構圖。如果要做某一個電商類或者某種服務體系的評價系統,可以採用這種模式。左邊是一種溯源的機制,我們希望鼓勵使用者去寫更多更好的評價,包括互動的優化,去提升有用評論的積累。有了資料之後,我們要去做去偽。去偽就是我們有一個評價霧霾工作,會把文字和圖片的垃圾都去掉,做好之後才能保證資訊是比較真實的。我們會對核心資料庫做語義分析,會結合某一些類目來做,做完之後我們會考慮它的時效性和個性化,還有買賣家模型,再做排序摺疊和大家印象的扶優。然後再做增值,我們會有一些比如優質內容庫、推薦理由、評價有賞。通過評價去發現商品的品質好不好,是不是假貨,物流滿意度如何,這裡面可以做很多很深入的分析。
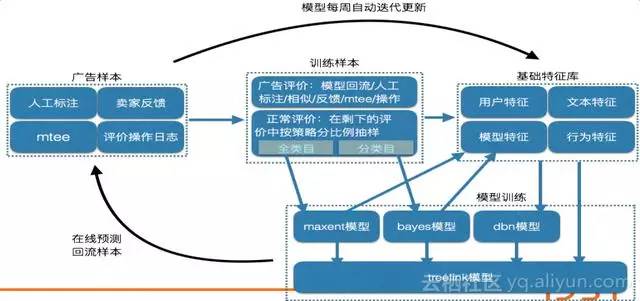
評價霧霾中間是非常複雜的一套體系,有很多工程很多演算法迭代了很久,比如說廣告的樣本怎麼採集,有全類目的和分類目的,還有正常廣告的,怎麼去做拆分,有一些基礎特徵庫比如使用者特徵、文字特徵、模型特徵、行為特徵等做融合,最後再用一個treelink模型,把maxent模型、貝葉斯模型和dbn模型總體做融合,然後再回流,一天一天迭代。
問大家

商品中有另外一個很有趣的產品叫問大家。以買奶粉為例,假如你有五個鄰居,有三個鄰居買過同一款奶粉,你要買奶粉可能希望多問兩家,如果三個人都買過A奶粉,三個人的回答結果綜合看一看,做最終的決策。我們把它做成產品化,那我們做一個問題的拆解分為四類:無效問題、相似問題、問答排序、智慧分發。
問大家3個問題解析如下:
-
無效問題過濾
–專業的外包同學標註無效問題,Active Learning篩選待標註樣本
–分類採用LR+GBDT,定製特徵
–無效問題會不斷變種,演算法和標註迭代推進
-
相似問題識別
–Doc2Vec然後計算相似度,人工評測
-
頁面問答排序
–內容豐富度、點贊數、過濾詞表匹配數等加權求和
–Detail頁透出的一條問大家CTR 提升
內容資訊分析
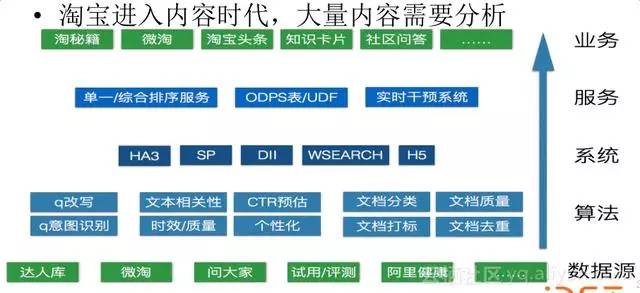
針對內容我們需要做大量的分析,比如說底層我們有各種各樣的資料庫要彙總,中間有一些文字演算法,比如說相關性、時效和質量、CTR預估、個性化、分類、打標、質量和去重等等,中間也有一些系統工程,還有服務體系。上面是業務場景,比如淘祕籍、微淘、淘寶頭條、知識卡片、社群問答等等,會讓你迅速進入一個很好的購物背景知識狀態,使你做更好的購物決策。你可以在手機淘寶搜尋結果頁的第四個Tab裡看到我們的淘祕籍產品。
思考
自然語言處理難在哪呢?它涉及到人的認知,知識<=>語言<=>思考<=>行動,左邊專注到知識,右邊專注到思考和行動。它是非常複雜的,最難的問題有兩個:第一就是歧義,自然語言與計算機語言是完全不可調和的,計算機語言是精確的、可列舉的、無歧義的。第二是變化,變化是非常劇烈的。它的語法是群體一致,個體有差異,語言每天都在發生變化,新詞總在不斷的產生,無法窮舉, 不同上下文不同含義,甚至隨時間推移,詞義也在發生變化,例如Apple->公司,甚至詞性也在發生變化,如Google ->to google 。
那麼,NLP怎麼走?
-
在完全搞清人腦機制前,NLP研發永遠是在模擬人類群體智慧在某些文字方面的表現;
-
這種模仿的效果會越來越好,持續提升;
-
更深入的模擬是,NLP會和語音、影象、視訊、觸覺等多維度資訊融合學習。
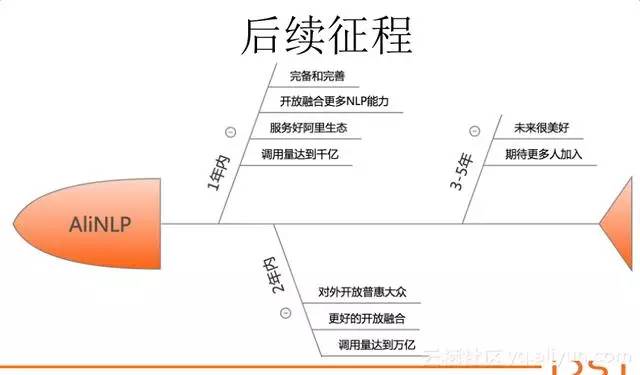
我們未來會做什麼,我們在一年之內會繼續把AliNLP平臺做的完備和完善,開放更多的能力,服務好阿里的各種生態系統。我們希望呼叫量能超過千億,兩年之內我們爭取能夠對外開放,普惠大眾,更好的開放融合,呼叫量希望達到萬億,我們希望做的更美好!
上乘:阿里巴巴iDST 自然語言處理部總監,博士畢業於哈爾濱工業大學自然語言處理方向,曾在新加坡資訊技術研究院工作四年擔任研究科學家負責統計機器翻譯系統的研發和應用,2014年至今在阿里巴巴iDST擔任資深專家,從零組建了自然語言處理部門,負責自然語言處理技術平臺的研發和多項核心業務應用。