
python3.6爬蟲案例:爬取朝秀幫圖片
一、寫在前面
之前寫的兩篇部落格:
第一個案例寫了如何在百度音樂歌單中欄中爬取其歌曲以及對應的歌手和歌曲所在的連結,並儲存在相應的資料夾下。這個爬蟲程式碼實現難度小,短時間內就可以爬完所有內容。第二個案例則是爬取頂點小說網中的完結小說,難度也不大,但有一點網站存在反爬機制,爬取的速度很慢。
今天給大家分享的是爬取朝秀幫(https://www.chaoxiubang.com)的圖片,目前該網站沒有反爬機制,爬取的效率主要取決於網速與程式碼效率。該網站的程式碼實現難度適中,難點就是如何針對爬蟲遇到的問題,完善程式,最後將網站所有的圖片全部爬下來。下面我們慢慢開始今天的內容。
二、首先根據首頁內容建立目錄資料夾,用於存放不同型別的美女。(不對,是存放美女圖片)
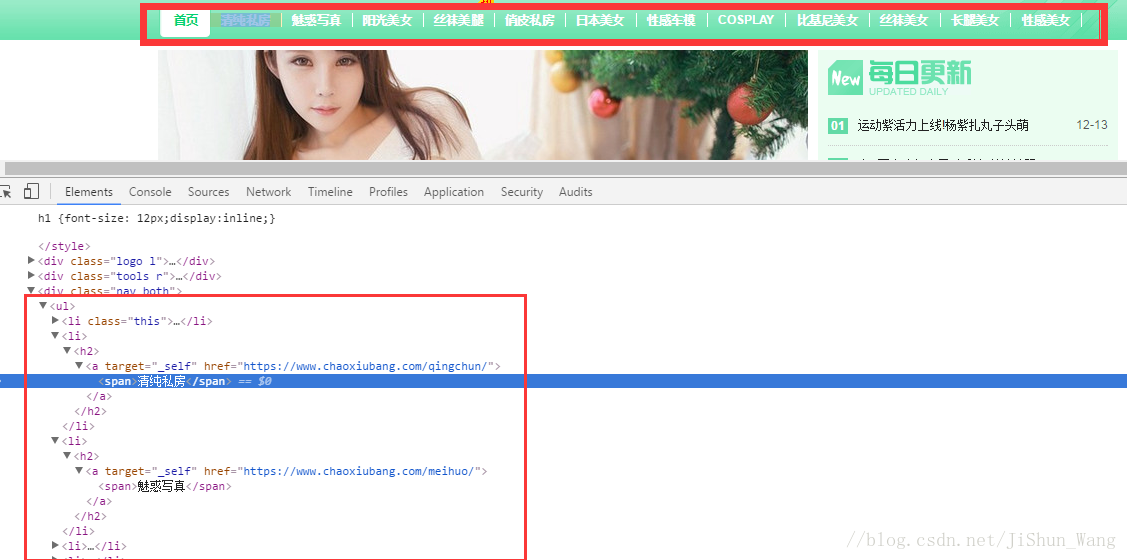
我們就根據網頁選單來建立資料夾。從上圖(具體怎麼開啟網頁原始碼,請看前兩篇部落格)我們容易發現所需的內容存在於<ul>標籤下,下面的子標籤<li>代表一個選單。每一個標籤<li>下有不同型別圖片的連結和名稱,我們只需將其爬取下來儲存到本地同時建立相應資料夾即可。我們建立Craw_category_href.py檔案,程式碼如下:
""" 獲取網站類目的所有類目名和相應的連結 """ import time import requests import os # import CrawPageContent import numpy as np from bs4 import BeautifulSoup FILE = 'F:\\python program\\潮秀網圖片' URL = 'https://www.chaoxiubang.com/' #獲取網頁資訊 def get_html(url): html = requests.get(url) html.encoding = 'gb2312' soup = BeautifulSoup(html.text, 'lxml') return soup #建立類目的資料夾 def CreatFile(File, file): path = File title = file new_path = os.path.join(path, title) print(new_path) if not os.path.isdir(new_path): os.makedirs(new_path) return new_path def main(): f = open('F:\\python program\\潮秀網圖片\\category.txt', 'w', encoding='utf-8') soup = get_html(URL) # print(soup) nav = soup.find('div', attrs={'class':['nav', 'both']}) li = nav.find_all('a', attrs={'target':'_self'}) link = [] for cate in li: name = cate.find('span').get_text() href = cate['href'] link.append(name+';'+href) count = 1 for info in link: store = info.split(';') cattitile = store[0].strip() new_path = CreatFile(FILE, cattitile) url = store[1].strip() f.write(cattitile+';'+url+';\n') f.close() if __name__ == '__main__': main()
執行一下(當然大家可以根據習慣在其他環境執行)看看結果:

我們已經將每個型別的圖片資料夾建立成功,也採集了每個目錄的連結。
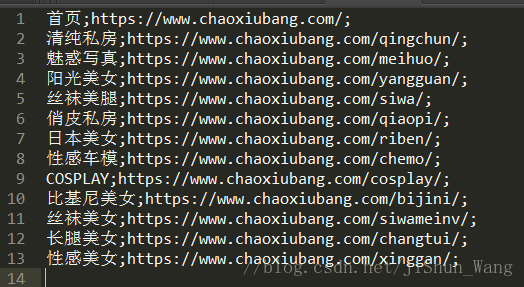
接下來我們據此爬取更詳細的資訊。
三、爬取每位美女的連結和描述
有了每個型別的圖片地址,我們就可以將該型別下的所有美女的圖片地址給爬下來,並將檔案放到相應資料夾內。
我們以陽光美女為例:
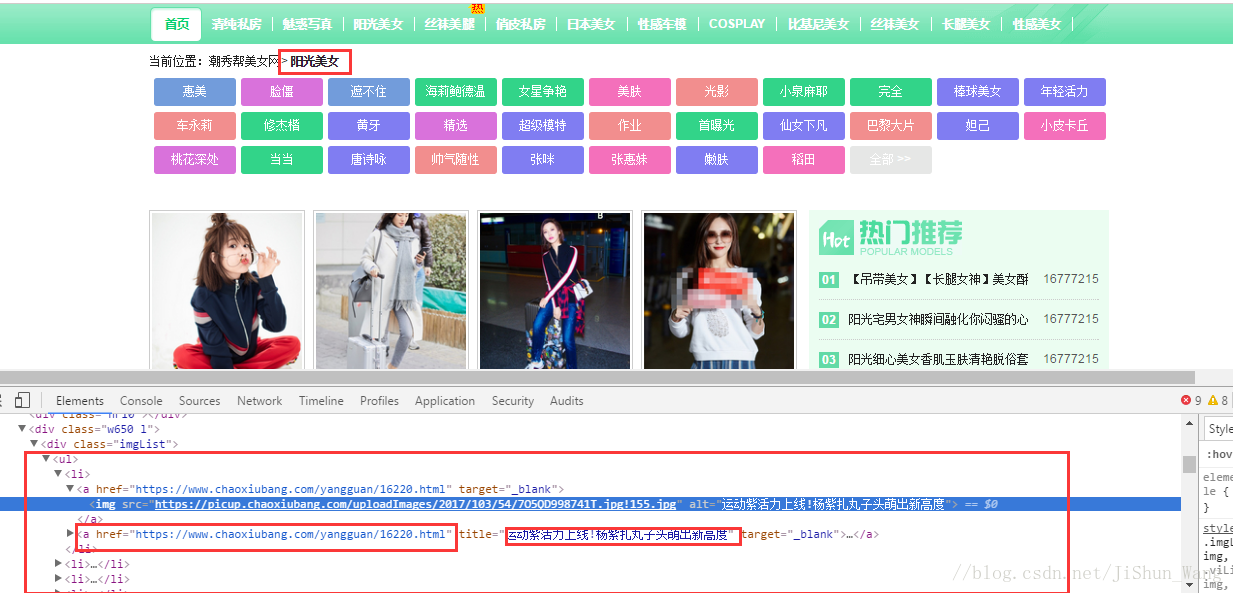
可以清楚看到,網頁也是很規整,並且有很多頁,這裡呈現的圖片是縮圖,其實我們點開縮圖會跳轉到該美女的詳細頁面,裡面有高清圖。我們採集的就是高清圖,不過不要著急,我們先爬下來每個分類下的美女頁面的連結。分析網頁寫出CrawAllPictureUrl.py,程式碼如下:
""" 爬取網站所有類目下的組圖連結,分別寫入相應資料夾下的url.txt檔案。 """ import requests import time import numpy as np import urllib.request from bs4 import BeautifulSoup #獲取網頁資訊 def get_html(url): html = requests.get(url) html.encoding = 'gb2312' soup = BeautifulSoup(html.text, 'lxml') return soup def main(): imglist = [] fInput = open('F:\\python program\\潮秀網圖片\\category.txt', 'r', encoding='utf-8') line = fInput.readline() while line: lin = line.split(';') if int(lin[2]) != 0: url = lin[1] fraw = lin[0] file = open('F:\\python program\\潮秀網圖片\\'+fraw.strip()+'\\url.txt', 'w', encoding='utf-8') countPage = 1#控制網頁跳轉 flag = 1#控制照片命名 while url: print('----------------'+str(countPage)) time.sleep(np.random.rand()) try: urlR = url + 'list_' + str(lin[2].strip()) + '_' + str(countPage) + '.html' print(urlR) html = get_html(urlR) imglist = html.find('div', attrs={'class': 'imgList'}) for li in imglist.find_all('li'): img = li.find('a')['href'] print('it is flag getinfo') file.write(str(flag) + ';' + img + '\n') flag += 1 countPage += 1 except: print('結束') break file.close() line = fInput.readline() else: line = fInput.readline() fInput.close() if __name__ == '__main__': main()
執行這個程式之前,告訴大家,由於每個類目下跳轉頁面的連結都有一個數字,比如魅惑第二頁連結:

我們構造魅惑頁面的跳轉連結時每次都shi list_2+“頁數”,其他的是其他數字,大家自行檢視,最後在第一個程式爬取的category.txt內容中新增一列,用於構造連結,如下圖:
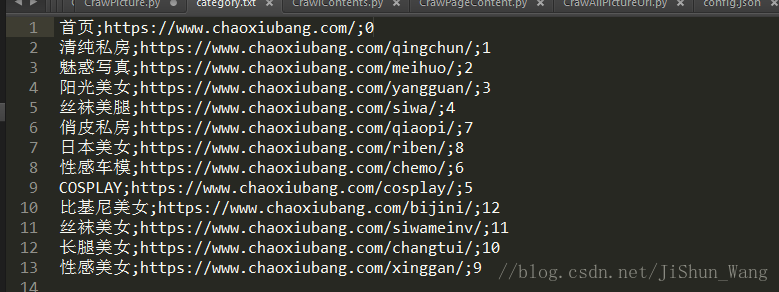
接下來可以執行CrawAllPictureUrl.py程式了。執行需要耐心等待了,圖片連結太多。我暫時演示爬取魅惑類目下的圖片連結:
大家可以看到接近2000個,每個連結下面包括n(10張左右)張高清圖。這麼多類目的圖片加起來共有幾十G(第一次爬取完畢,考慮到最近半年多的更新可能更多。)
四、爬取高清大圖
我們得到了這麼多妹子的連結,還沒有結束,我們還沒有拿到高清圖呢,下面我們就是根據每個類目下的url.txt檔案中的連結,爬取每個連結下的圖片,我們找個陽光美女下的楊紫圖看看。下圖圈出來的要作為圖片名稱
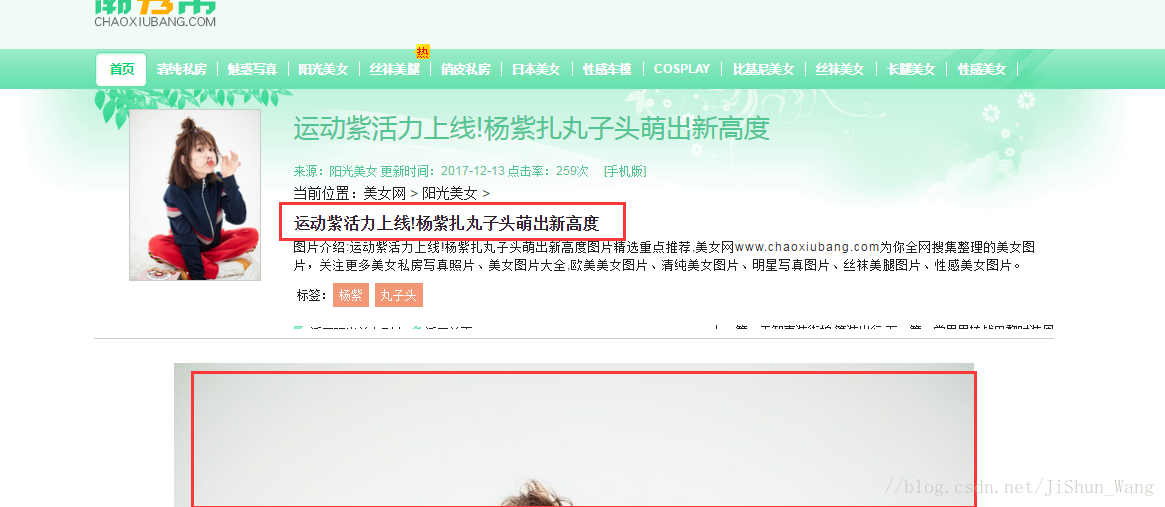
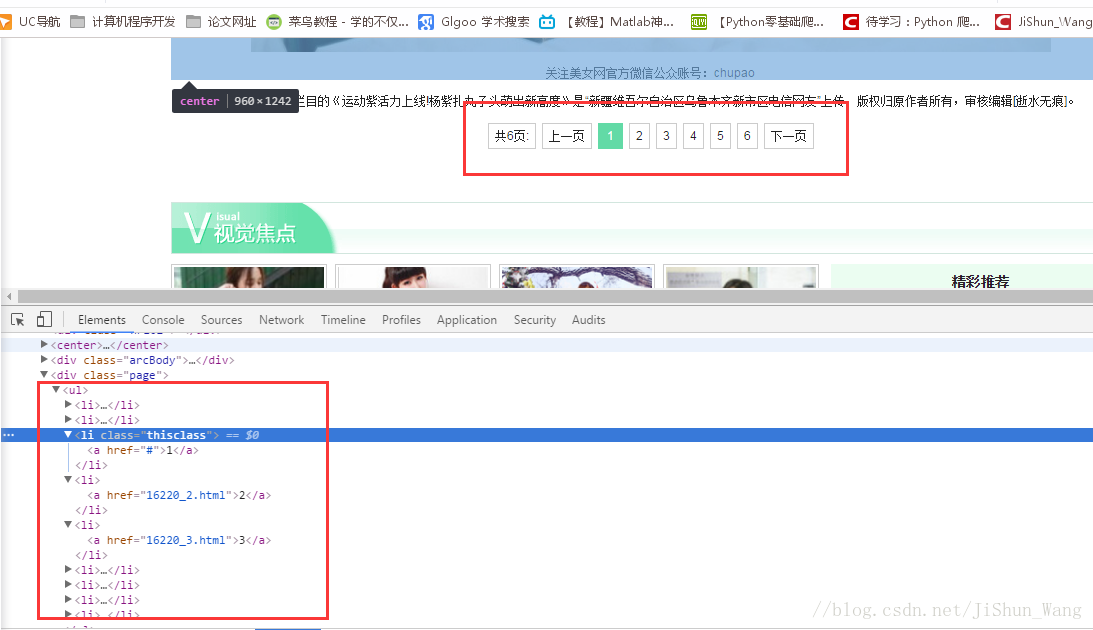
看上圖,這時楊紫第一章圖片所在頁面,我們可以看到一共有6張高清大圖,通過“檢查”發現,其餘圖的連結在標籤<ul>下,我們依次取出,將圖片儲存下來即可,廢話不多說直接上程式碼(檔案為CrawPicture.py):
"""
此程式考慮的情況很多,下面有註釋
"""
import requests, time
import os
import numpy as np
import urllib.request
from bs4 import BeautifulSoup
#tag =['清純私房','俏皮私房','COSPLAY', '比基尼美女', '魅惑寫真', '日本美女', '絲襪美女', '絲襪美腿', '性感車模', '性感美女', '陽光美女', '長腿美女']
tag = [ '魅惑寫真']
URL = 'https://www.chaoxiubang.com'
FILE = 'F:\\python program\\潮秀網圖片'
#建立資料夾
def CreatFile(file, title):
path = file
title = title
new_path = os.path.join(path, title)
if not os.path.isdir(new_path):
os.makedirs(new_path)
return new_path
#獲取html
def get_html(url):
html = requests.get(url)
html.encoding = 'gbk'
soup = BeautifulSoup(html.text, 'lxml')
return soup
#判斷檔名是否合法,有些圖片名中含有非法字元不止一處,所以使用迴圈判斷,直到合法
def judgeName(name):
flag = True
while flag:
if '?' in name:
name = name.replace('?', '_')
elif '\\' in name:
name = name.replace('\\', '_')
elif '/' in name:
name = name.replace('/', '_')
elif ':' in name:
name = name.replace(':', '_')
elif ':' in name:
name = name.replace(':', '_')
elif '*' in name:
name = name.replace('*', '_')
elif '"' in name:
name = name.replace('"', '_')
elif '<' in name:
name = name.replace('<', '_')
elif '>' in name:
name = name.replace('>', '_')
elif '|' in name:
name = name.replace('', '_')
else:
flag = False
return name
#獲得圖片,暫時第一張,因為網站的特點,每一組圖片的第二及之後的圖片連結和第一張的不一致
#只能分別處理
def get_pic_name(soup):
h3 = soup.find('h3')
name = h3.find('a').get_text()
pic_href = soup.find('div', attrs={'class':'article_left_top_body'})
src = pic_href.find('img')['src']
return name, src
def main():
for category in tag:
fInput = open('F:\\python program\\潮秀網圖片\\url.txt', 'r', encoding = 'utf-8')
line = fInput.readline()
while line:
linesplit = line.split(';')
countNum = linesplit[0].strip()
print(time.ctime() + '正在列印' + category + ':第' + str(countNum) + '組')
url = linesplit[1].strip()
if URL not in url:
url = URL + url
print(url)
html = get_html(url)
try:#有些連結定位不到就繼續下一個連結的爬取
name, src = get_pic_name(html)
print('-------------'+name)
name = judgeName(name)
except:
line = fInput.readline() #
continue
try:
print(name+'-------------')
fOutput = open('F:\\python program\\潮秀網圖片\\'+category + '\\'+countNum+'_'+ name + '\\'+ name +'.jpg', 'wb')
print(fOutput)
print(category)
except:
newpath = CreatFile(FILE+'\\'+category, countNum+'_'+name)
fOutput = open(newpath + '\\'+ name +'(1).jpg', 'wb')
print(newpath)
try:#有些圖片不存在,若不存在就繼續下一組套圖的爬取
req = urllib.request.urlopen(src)
buf = req.read()
fOutput.write(buf)
fOutput.close()
except:
line = fInput.readline()#連結圖片不存在跳轉到下一頁
continue
page = 2#控制圖片連結的頁數,也可以用程式碼去定位到頁數控制,個人感覺這樣方便
while url:#對套圖非首頁的採集
try:
surl = url[:-5] + '_'+str(page)+'.html'
print(surl)
html = get_html(surl)
sname, src = get_pic_name(html)
sname = judgeName(sname)
fOutput = open('F:\\python program\\潮秀網圖片\\'+category + '\\'+countNum+'_'+ name + '\\'+ sname +'.jpg', 'wb')
req = urllib.request.urlopen(src)
buf = req.read()
fOutput.write(buf)
fOutput.close()
page += 1
except:
break
line = fInput.readline()
fInput.close()
# break
if __name__ == '__main__':
main()
執行下程式,效果是這樣的:
開啟一個資料夾:
有沒有很興奮。名字看起來尺度很大,其實圖片很有度的。
五、寫在最後。
這個案例是較有難度的,裡面程式碼也有很多可以優化的地方,我自己就看出來了很多,不過這樣爬取網站圖片速度有點慢。也許大家在看這一個一個檔案的時候是否也看到了,我們是分佈來的,其實早就有大牛寫好了爬蟲框架,隨著學習的深入,我們可以運用爬蟲現有的框架,結合自己爬蟲的特點來進行爬取。這 寫內容等以後再和大家分享。
(大家要是覺得學到了東西,請關注下,有什麼問題歡迎留言交流。)