
C#正則表示式程式設計(三):Match類和Group類用法
前面兩篇講述了正則表示式的基礎和一些簡單的例子,這篇將稍微深入一點探討一下正則表示式分組,在.NET中正則表示式分組是用Match類來代表的。
首先先看一段程式碼:
這段程式碼的執行效果如下:
Match=[1A ]
Capture=[1A ]
Groups[0]=[1A ]
Captures[0]=[1A ]
Groups[1]=[1A]
Captures[0]=[1A]
Groups[2]=[1]
Captures[0]=[1]
Groups[3]=[A]
Captures[0]=[A]
Match=[2B ]
Capture=[2B ]
Groups[0]=[2B ]
Captures[0]=[2B ]
Groups[1]=[2B]
Captures[0]=[2B]
Groups[2]=[2]
Captures[0]=[2]
Groups[3]=[B]
Captures[0]=[B]
..................此去省略一些結果
Match=[16N ]
Capture=[16N ]
Groups[0]=[16N ]
Captures[0]=[16N ]
Groups[1]=[16N]
Captures[0]=[16N]
Groups[2]=[16]
Captures[0]=[16]
Groups[3]=[N]
Captures[0]=[N]
通過對上面的程式碼結合程式碼的分析,我們得出下面的結論,在((/d+)([a-z]))/s+這個正則表示式裡總共包含了四個Group,即分組,按照預設的從左到右的匹配方式,其中Groups[0]代表了整個分組,其它的則是子分組,用示意圖表示如下: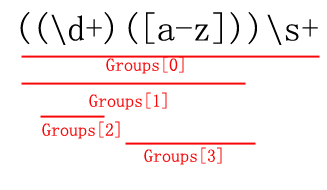
在上面的程式碼中是採用了Regex類的Match()方法,呼叫這種方法返回的是一個Match,要處理分析全部的字串,還需要在while迴圈的中通過Match類的NextMatch()方法返回下一個可能成功的匹配(可通過Match類的Success屬性來判斷是否成功匹配)。上面的程式碼還可以寫成如下形式:
上面的這段程式碼和採用While迴圈遍歷所有匹配的結果是一樣的,在實際情況中有可能出現不需要全部匹配而是從某一個位置開始匹配的情況,比如從第32個字元處開始匹配,這種要求可以通過Match()或者Matches()方法的過載方法來實現,僅需要將剛才的例項程式碼中的MatchCollection matchCollection = r.Matches(text);改為MatchCollection matchCollection = r.Matches(text,48);就可以了。
輸出結果如下:
Match=[5M ]
Capture=[5M ]
Groups[0]=[5M ]
Captures[0]=[5M ]
Groups[1]=[5M]
Captures[0]=[5M]
Groups[2]=[5]
Captures[0]=[5]
Groups[3]=[M]
Captures[0]=[M]
Match=[16N ]
Capture=[16N ]
Groups[0]=[16N ]
Captures[0]=[16N ]
Groups[1]=[16N]
Captures[0]=[16N]
Groups[2]=[16]
Captures[0]=[16]
Groups[3]=[N]
Captures[0]=[N]
注意上面的MatchCollection matchCollection = r.Matches(text,48)表示從text字串的位置48處開始匹配,要注意位置0位於整個字串的之前,位置1位於字串中第一個字元之後第二個字元之前,示意圖如下(注意是字串“1A”與“2B”之間有空格):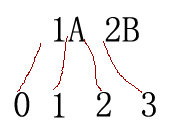
在text的位置48處正好是15M中的5處,因此返回的第一個Match是5M而不是15M。這裡還繼續拿出第一篇中的圖來,如下: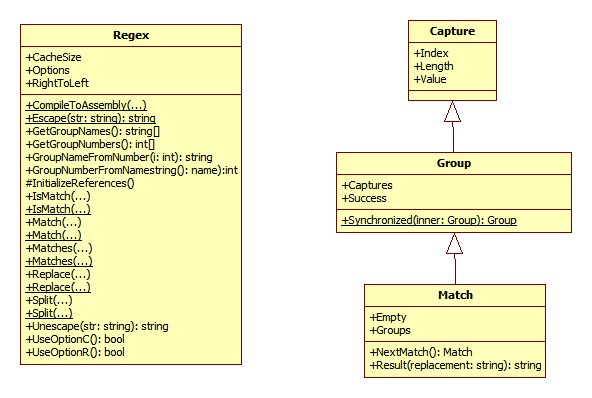
從上圖可以看出Capture、Group及Match類之間存在繼承關係,處在繼承關係頂端的Capture類中就定義了Index、Length和Value屬性,其中Index表示原始字串中發現捕獲子字串的第一個字元的出現位置,Length屬性表示子字串的長度,而Value屬性表示從原始字串中捕獲的子字串,利用這些屬性可以實現一些比較複雜的應用。例如在現在還有很多論壇仍沒有使用所見即所得的線上編輯器,而是使用了一種UBB編碼的編輯器,使用所見即所得的編輯器存在著一定的安全風險,比如可以在原始碼中嵌入js程式碼或者其它惡意程式碼,這樣瀏覽者訪問時就會帶來安全問題,而使用UBB程式碼就不會程式碼這個問題,因為UBB程式碼包含了有限的、但不影響常規使用的標記並且支援UBB程式碼的編輯器不允許直接在字串中出現HTML程式碼,也而就避免惡意指令碼攻擊的問題。在支援UBB程式碼的編輯器中輸入的文字在存入資料庫中儲存的形式是UBB編碼,顯示的時候需要將UBB編碼轉換成HTML程式碼,例如下面的一段程式碼就是UBB編碼:
[url]http://zhoufoxcn.blog.51cto.com[/url][url=http://blog.csdn.net/zhoufoxcn]周公的專欄[/url]
下面通過例子演示如何將上面的UBB編碼轉換成HTML程式碼:
程式執行結果如下:
原始UBB程式碼:[url=http://zhoufoxcn.blog.51cto.com][/url][url=http://blog.csdn.net/zhoufoxcn]周公的專欄[/url]
替換後的程式碼:<a href="http://zhoufoxcn.blog.51cto.com" target="_blank">http://zhoufoxcn.blog.51cto.com</a><a href="http://blog.csdn.net/zhoufoxcn"target="_blank">周公的專欄</a>
上面的這個例子就稍微複雜點,對於初學正則表示式的朋友來說,可能有點難於理解,不過沒有關係,後面我會講講正則表示式。在實際情況下,可能通過match.Groups[0].Value這種方式不太方便,就想在訪問DataTable時寫string name=dataTable.Rows[i][j]這種方式一樣,一旦再次調整,這種通過索引的方式極容易出錯,實際上我們也可以採用名稱而不是索引的放來來訪問Group分組,這個也會在以後的篇幅中去講。
周公
2010-02-25
更多資訊,請關注本人微信訂閱號:
