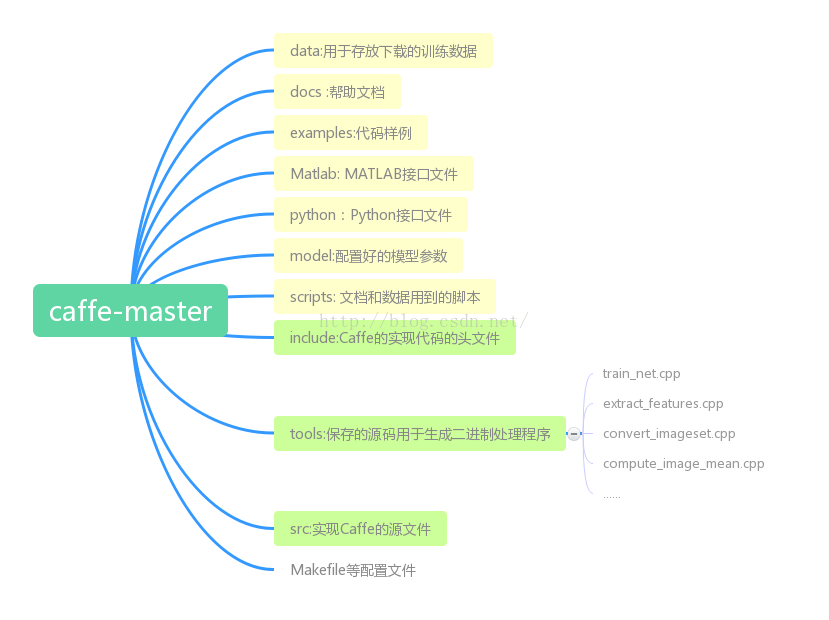
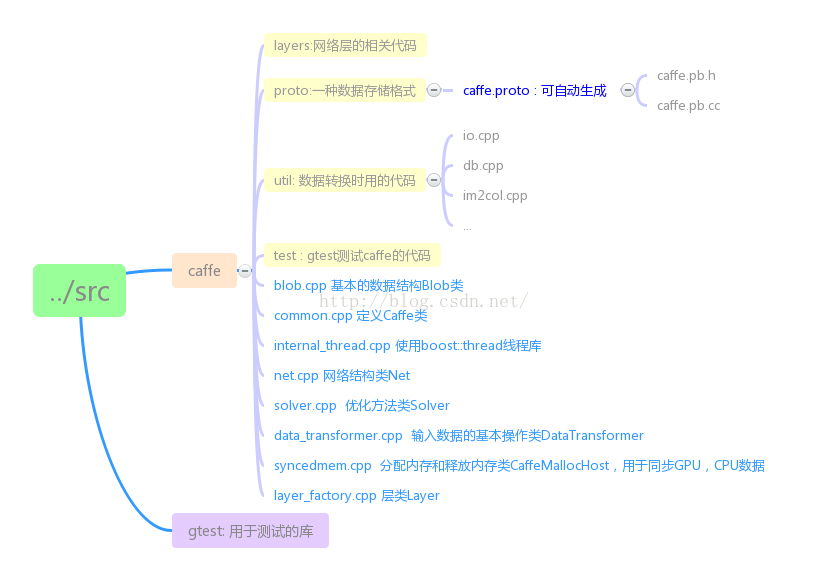
Caffe的依賴庫及原始碼目錄結構
1. Boost庫:它是一個可移植、跨平臺,提供原始碼的C++庫,作為標準庫的後備。
在Caffe中用到的Boost標頭檔案包括:
(1)、shared_ptr.hpp:智慧指標,使用它可以不需要考慮記憶體釋放的問題;
(2)、date_time/posix_time/posix_time.hpp:時間操作函式;
(3)、python.hpp:C++/Python互操作;
(4)、make_shared.hpp:make_shared工廠函式代替new操作符;
(5)、python/raw_function.hpp:C++/Python互操作;
(6)、python/suite/indexing/vector_indexing_suite.hpp:C++/Python互操作;
(7)、thread.hpp:執行緒操作;
(8)、math/special_functions/next.hpp:數學函式;
2.GFlags庫:它是google的一個開源的處理命令列引數的庫,使用C++開發,可以替代getopt函式。GFlags與getopt函式不同,在GFlags中,標記的定義分散在原始碼中,不需要列舉在一個地方。
3. GLog庫:它是一個應用程式的日誌庫,提供基於C++風格的流的日誌API,以及各種輔助的巨集。它的使用方式與C++的stream操作類似。
4. LevelDB庫:它是google實現的一個非常高效的Key-Value資料庫。它是單程序的服務,效能非常高。它只是一個C/C++程式語言的庫,不包含網路服務封裝。
LevelDB特點:(1)、LevelDB是一個持久化儲存的KV系統,它將大部分資料儲存到磁碟上;(2)、LevelDB在儲存資料時,是根據記錄的Key值有序儲存的;(3)、像大多數KV系統一樣,LevelDB的操作介面很簡單,基本操作包括寫記錄,讀記錄以及刪除記錄,也支援針對多條操作的原子批量操作;(4)、LevelDB支援資料快照(snapshot)功能,使得讀取操作不受寫操作影響,可以在讀操作過程中始終看到一致的資料;(5)、LevelDB支援資料壓縮(Snappy)等操作。
5. LMDB庫:它是一個超級快、超級小的Key-Value資料儲存服務,是由OpenLDAP專案的Symas開發的。使用記憶體對映檔案,因此讀取的效能跟記憶體資料庫一樣,其大小受限於虛擬地址空間的大小。
6.ProtoBuf庫:GoogleProtocol Buffer(簡稱ProtoBuf),它是一種輕便高效的結構化資料儲存格式,可以用於結構化資料序列化,或者說序列化。它很適合做資料儲存或RPC資料交換格式。可用於通訊協議、資料儲存等領域的語言無關、平臺無關、可擴充套件的序列化結構資料格式。
要使用ProtoBuf庫,首先需要自己編寫一個.proto檔案,定義我們程式中需要處理的結構化資料,在protobuf中,結構化資料被稱為Message。在一個.proto檔案中可以定義多個訊息型別。用Protobuf編譯器(protoc.exe)將.proto檔案編譯成目標語言,會生成對應的.h檔案和.cc檔案,.proto檔案中的每一個訊息有一個對應的類。
7.HDF5庫:HDF(HierarchicalData File)是美國國家高階計算應用中心(NCSA)為了滿足各種領域研究需求而研製的一種能高效儲存和分發科學資料的新型資料格式。它可以儲存不同型別的影象和數碼資料的檔案格式,並且可以在不同型別的機器上傳輸,同時還有統一處理這種檔案格式的函式庫。HDF5推出於1998年,相較於以前的HDF檔案,可以說是一種全新的檔案格式。HDF5是用於儲存科學資料的一種檔案格式和庫檔案。
HDF5是分層式資料管理結構。HDF5不但能處理更多的物件,儲存更大的檔案,支援並行I/O,執行緒和具備現代作業系統與應用程式所要求的其它特性,而且資料模型變得更簡單,概括性更強。
HDF5只有兩種基本結構,組(group)和資料集(dataset)。組,包含0個或多個HDF5物件以及支援元資料(metadata)的一個群組結構。資料集,資料元素的一個多維陣列以及支援元資料。
8. snappy庫:它是一個C++庫,用來壓縮和解壓縮的開發包。它旨在提供高速壓縮速度和合理的壓縮率。Snappy比zlib更快,但檔案相對要大20%到100%。
原始碼目錄結構如下: