
關於程序記憶體使用的一點學習和實踐
如果籠統的來看,大概就是兩個指標,系統的記憶體使用率和程序使用的記憶體。但是現實世界的事情往往沒有那麼簡單,稍微細一點來看其實有很多的科目。本文不是一個全面的關於記憶體使用的探討,甚至也不是一個詳細的Linux下面程序記憶體使用情況的分析,儘管這裡的實踐是基於此的。
這裡想做的是稍微細節一點的來看Linux下一個程序的記憶體使用情況,包括棧和堆。
首先我們從一個簡單的C程式開始。且慢,先說一下我試驗的環境。
platform: CentOS release 5.6 (Final) Linux localhost.localdomain 2.6.18-238.19.1.el5xen #1 SMP Fri Jul 15 08:57:45 EDT 2011 i686 i686 i386 GNU/Linux
gcc version 4.1.2 20080704 (Red Hat 4.1.2-50)
[[email protected] test]# cat simple_hello.c
#include <stdio.h>
int main()
{
int i,m = 1024, n = 0, x;
int a[m];
printf("assign %d values to a[%d]...\n", n, m);
for (i = 0; i < n; i++)
{
a[i] = 100;
}
printf("value assigned.\n");
scanf("%d", &x); /* to hold program.. */
return 0;
}
真是一個很簡單的程式,只比hello world複雜一點點。建立一個靜態的陣列,長度通過m來控制,然後選擇性的給部分或者全部的元素賦值,通過n來控制。好吧,這個一個簡單的程式能看出什麼呢?那我們一起來看看。
在Linux下面,檢視一個程序的記憶體使用我們可以下面的命令來實現,只需把其中的[pid]換成程序實際的pid。
# cat /proc/[pid]/status
為了方便,我們把查詢pid和看記憶體整合成一條命令,後面這將是我們唯一的測試工具。
cat /proc/`ps -ef|grep hello | grep -v grep | awk '{print $2}'`/status | grep -E 'VmSize|VmRSS|VmData|VmStk|VmExe|VmLib'
在這裡我們關注VmSize|VmRSS|VmData|VmStk|VmExe|VmLib 這個6個指標,下面有一些簡單的解釋。
VmSize(KB) :虛擬記憶體大小。整個程序使用虛擬記憶體大小,是VmLib, VmExe, VmData, 和 VmStk的總和。
VmRSS(KB):虛擬記憶體駐留集合大小。這是駐留在實體記憶體的一部分。它沒有交換到硬碟。它包括程式碼,資料和棧。
VmData(KB): 程式資料段的大小(所佔虛擬記憶體的大小),堆使用的虛擬記憶體。
VmStk(KB): 任務在使用者態的棧的大小,棧使用的虛擬記憶體
VmExe(KB): 程式所擁有的可執行虛擬記憶體的大小,程式碼段,不包括任務使用的庫
VmLib(KB) :被映像到任務的虛擬記憶體空間的庫的大小
Ok, 測試開始了。
首先,我們固定m的值為409600,相當於400K,因為陣列的元素是int型,在我的環境裡面是4Byte,所以真個陣列的大小為1600KB。
m固定化,我們不斷調整n的大小,重寫編譯,執行,然後用上面的命令檢視記憶體的使用情況,這樣我們得到了下面這個表格。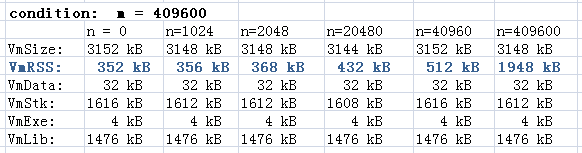
從這裡我們可以得到幾個資訊:
1. 靜態的陣列使用的空間被分配到VmStk,也就是棧區。
2. 在陣列沒有初始化的時候並沒有實際佔用虛擬記憶體,看VmRss,但是整個虛擬記憶體的大小還是分配了,VmSize。
接下來我們做另一個測試,讓n=m,調整m的大小,也就是說調整陣列的大小,然後初始化所有的元素。
這樣我們得到了下面的表。
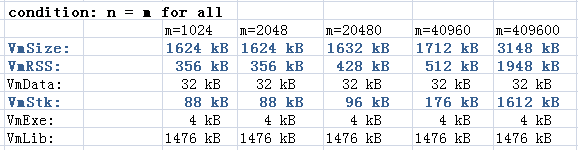
從這個表中,我們可以看出:
1. 棧的使用確實和陣列的size相關,但是有個起始預分配的大小,應該是編譯器的優化。
2. VmRSS和VmSize跟著一起在漲。
嗯,是跟著在漲,但是有個問題,棧的空間是有限的,通過這個程式或者你檢視系統的設定你可以找到上限。在我的這臺機器上上限是8MB,每個程序,所以這裡如果m的值大於2048000,就會出segmentation fault的錯誤。當然你也可以調整系統的設定,比如通過
# ulimit -s 10240將上限調為10MB。但是這個終究不能調得很大,因為對系統會有影響。所以程式設計中太大的靜態陣列不是有個好主意。
棧的大小限制還是蠻嚴格的,好吧,那我們來看看程式可以使用的另一類儲存空間,堆(heap)。關於堆和棧的區別可能是一個常被問道的問題,你在很多地方可以找到答案。
OK,我們繼續我們的實驗,考慮到現在很多系統的後臺用C++來寫,我們也把測試程式換成C++的。好吧,我承認其實沒有太大的區別,只是申請記憶體的方式不太一樣了。
[[email protected] test]# cat hello.cpp
#include <iostream>
using namespace std;
int main()
{
cout<<"New some space for array, assign value"<<endl;
intm = 409600, n = 409600;
int *p = new int[m];
for (int i = 0; i < n; i++)
{
p[i] = 100;
}
cout<<"value assigned."<<endl;
int x;
cin>>x; //hold program
}
這個我們使用的是動態的陣列,也就是說陣列的內容空間是我們顯式的通過new通過向系統申請的。測試工具還是上面的命令列。
延遲我們的風格,首先固定m的值,這裡是409600,400K,然後調整n的值,看情況是怎樣的。
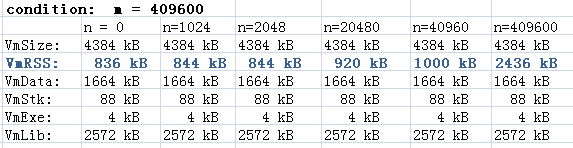
一些觀察的結果:
1. VmData的大小約為1600KB,因為每個元素4Byte,系統還有一些別的使用。
2. n控制有多少陣列的元素被初始化,這也影響了VmRSS的大小。
整個VmSize的大小並不受初始化範圍的影響,這個結果和之前棧的實驗中看到的現象很類似,只不過這裡換成了VmData。
接下來我們讓n=m,然後兩個一起調整。
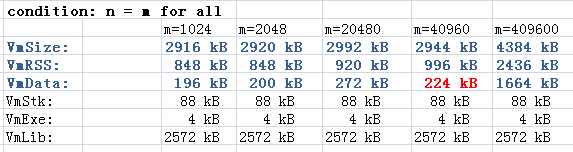
相關推薦
關於程序記憶體使用的一點學習和實踐
如果籠統的來看,大概就是兩個指標,系統的記憶體使用率和程序使用的記憶體。但是現實世界的事情往往沒有那麼簡單,稍微細一點來看其實有很多的科目。本文不是一個全面的關於記憶體使用的探討,甚至也不是一個詳細的Linux下面程序記憶體使用情況的分析,儘管這裡的實踐是基於此的。這裡想做的是稍微細節一點的來看Linux
C# Ioc、DI、Unity、TDD的一點想法和實踐
stc 映射 rac 下載 性能 ole HA manager 單元 面向對象設計(OOD)有助於我們開發出高性能、易擴展以及易復用的程序。其中,OOD有一個重要的思想那就是依賴倒置原則(DIP)。 依賴倒置原則(DIP):一種軟件架構設計的原則(抽象概念) 控制反轉(
Restful介面設計的學習和實踐之路
REST介面在前幾年是很火的,關於REST與SOAP有著無數的口水戰,現在隨著restful介面逐漸作為行業的事實上的標準普及開來應該已經沒有什麼異議了,這篇文章介面為什麼要使用restful風格的以及在近幾年的開發中restful介面設計的更新。 什麼是Re
技術人“結構化思維”訓練的一點想法和實踐
"結構化思維”對於技術人員coding能力的升級至關重要,是一線網際網路大廠升級為高工及技術專家的關鍵之一。“結構化思維”對於應對網上甚囂塵上的“35歲中年危機”也是關鍵。 好了,那麼問題來了_ @by 輝哥 (87年生
用深度學習(CNN RNN Attention)解決大規模文本分類問題 - 綜述和實踐
分享 最大的 卷積神經網絡 繼續 基本思想 直觀 paper int 最大 https://zhuanlan.zhihu.com/p/25928551 近來在同時做一個應用深度學習解決淘寶商品的類目預測問題的項目,恰好碩士畢業時論文題目便是文本分類問題,趁此機會總結下文本分
幹貨|程序員應該怎樣去學習和掌握計算機英語呢?
http 掌握 font tps 英語 com 12px size body https://mp.weixin.qq.com/s/W5oeQfxFG6geyIUaZTCi_Q幹貨|程序員應該怎樣去學習和掌握計算機英語呢?
微信小程序的學習和應用
width 分享 left 開發 未成年 框架 開始學習 講師 ima 天網恢恢,疏而不漏!一代混吃等死大魔王突然幡然醒悟,決心拿起教程開始學習微信小程序的開發,這!究竟是道德的淪喪,還是老板的變態,她的學習又將為我們帶來什麽意料之外的收獲? 本期【只要框架換的快,精髓就追
基於深度學習和遷移學習的遙感影象場景分類實踐(AlexNet、ResNet)
卷積神經網路(CNN)在影象處理方面有很多出色的表現,在ImageNet上有很多成功的模型都是基於CNN的。AlexNet是具有歷史意義的一個網路,2012年提出來當年獲得了當年的ImageNet LSVRC比賽的冠軍,此後ImageNet LSVRC的冠軍都是都是用CNN做的,並且層
【轉載】演講實錄:百度大規模深度學習應用實踐和開源AI框架PaddlePaddle
導語:本文根據PaddlePaddle技術負責人、百度NLP技術委員會主席於佃海在今年英特爾人工智慧大會上的演講——《百度大規模深度學習應用實踐和開源AI框架PaddlePaddle》整理而成。 PaddlePaddle技術負責人、百度NLP技術委員會主席於佃海 正文: 很高興能
Nginx學習之路(六)NginX中的記憶體管理之---Nginx中的記憶體對齊和記憶體分頁
Nginx由於極高的效能受到大家的追捧,而Nginx的高效能與它優秀的記憶體管理方式是分不開的,今天就來聊一聊Nginx中的記憶體對齊和記憶體分頁。先說下Nginx中的記憶體對齊,Nginx中的記憶體對齊機制是它高效能的關鍵因素之一,先說點基礎的東西,什麼是記憶體對齊呢? 記
java的執行緒安全、單例模式、JVM記憶體結構等知識學習和整理
知其然,不知其所以然 !在技術的海洋裡,前路漫漫,我一直在迷失著自我。 歡迎訪問我的csdn部落格,我們一同成長! “不管做什麼,只要堅持下去就會看到不一樣!在路上,不卑不亢!” 在下面的題目來自於我要加的一個QQ群,然後要加這個QQ群
shmget 共享記憶體 同步讀寫檔案一個程序寫,多個程序讀,讀和寫同步,邊寫邊讀
首先,看看老大給我的任務:實現一個模組間的記憶體管理庫, 實現以下功能 1、該記憶體庫通訊的資料量不確定, 最大5Mbit/s 2、該記憶體庫用於模組間的資料互動 3、該記憶體庫只允許一個模組寫入, 但可多個模組讀取, 但需要各個讀取模組沒有任何相互干擾, 比如一個模組
C++記憶體管理學習堆和棧
一 C++記憶體管理 1.記憶體分配方式 在講解記憶體分配之前,首先,要了解程式在記憶體中都有什麼區域,然後再詳細分析各種分配方式。 1.1 C語言和C++記憶體分配區 下面的三張圖,圖1圖2是一種比較詳細的C語言的記憶體區域分法。圖3是典型的C++記憶體分佈圖,簡單易懂;以
推薦系統遇上深度學習(二)--FFM模型理論和實踐
全文共1979字,6張圖,預計閱讀時間12分鐘。FFM理論在CTR預估中,經常會遇到one-ho
推薦系統遇上深度學習(三)--DeepFM模型理論和實踐
1、背景特徵組合的挑戰對於一個基於CTR預估的推薦系統,最重要的是學習到使用者點選行為背後隱含的特徵組合。在不同的推薦場景中,低階組合特徵或者高階組合特徵可能都會對最終的CTR產生影響。之前介紹的因子分解機(Factorization Machines, FM)通過對於每一維特徵的隱變數內積來提取特徵組合。最
推薦系統遇上深度學習(一)--FM模型理論和實踐
全文共2503字,15張圖,預計閱讀時間15分鐘。FM背景在計算廣告和推薦系統中,CTR預估(c
深入學習JVM記憶體設定原理和調優
一、設定JVM記憶體設定 1. 設定JVM記憶體的引數有四個: -Xmx Java Heap最大值,預設值為實體記憶體的1/4,最佳設值應該視實體記憶體大小及計算機內其他記憶體開銷而定; -Xms Java Heap初始值,Server端JVM最好將-Xms和-Xmx設為相同值,開發測試機J
tensorflow實踐(二) 基本原理學習和框架使用
Tensorflow 是google大腦小組的工程師們開發的用於機器學習和深度神經網路方面的研究,它通過一個數據流圖來進行計算。[本文是對Tensorflow社群資料進行學習和實踐,其中文社群還是很
linux記憶體操作--ioremap和mmap學習筆記
最近在做視訊輸出相關的東西,對於預留給framebuffer的記憶體使用不是很清楚,現在找到一些資料整理一下,以備使用。if (想看使用方法) goto 使用方法; 對於一個系統來講,會有很多的外設,那麼這些外設的管理都是通過CPU完成。那麼CPU在這個過程中是如何找
Python web入門:Django學習與實踐二(簡單頁面實現和建立一個模板)
一、第一個頁面實現(“hello world”) 實現步驟: 1.在views.py檔案中建立一個處理函式(引數名可以隨意,但是最好使用request,看起來清楚明瞭) def index(request):