
解決CentOS7中文語言亂碼(包括Tomcat日誌中文亂碼)問題
Linux系統中文語言亂碼,是很多小夥伴在開始接觸Linux時經常遇到的問題,而且當我們將已在Wndows部署好的專案搬到Linux上執行時,Tomcat的輸出日誌中文全為亂碼(在Windows上正常),看著非常心塞,那麼我們應該怎麼解決呢?
系統中文亂碼

Tomcat輸出日誌中文亂碼
系統環境
- CentOS 7.0 64位
- jdk-8u11-linux-x64.
- apache-tomcat-8.5.16
解決步驟:
1.安裝中文語言包
先檢視系統是否有安裝中文語言包
# locale -a (列出所有可用的公共語言環境的名稱)
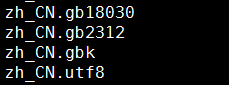
若發現以上幾項,說明系統已安裝中文語言包,無需再安裝,那這幾項代表什麼意思呢?
{語言代號}_{國家代號}.{字符集}
zh是中文的代號、CN是中國的代號、gb18030,gb2312,utf8是語言字符集
那麼每一項可以通俗理解為 “你是說中文的,你在中國,語言字符集是gb18030/gb2312/utf8”
如果沒有發現以上幾項,則手動安裝中文語言包
# yum install kde-l10n-Chinese (大概11M)
2.修改i18n國際化和locale.conf本土化配置檔案
在修改配置檔案之前,我們先看看當前系統語言環境
# locale
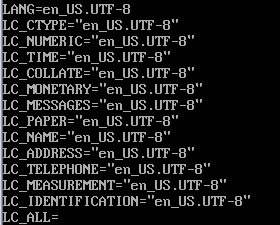
("en_US.UTF-8"按照上面的內容可以理解為“你說英語,你在美國,語言字符集為UTF-8”)
每項的意思分別為 :
LANG:當前系統的語言
LC_CTYPE:語言符號及其分類
LC_NUMERIC:數字
LC_COLLATE:比較和排序習慣
LC_TIME:時間顯示格式
LC_MONETARY:貨幣單位
LC_MESSAGES:資訊主要是提示資訊,錯誤資訊, 狀態資訊, 標題, 標籤, 按鈕和選單等
LC_NAME:姓名書寫方式
LC_ADDRESS:地址書寫方式
LC_TELEPHONE:電話號碼書寫方式
LC_MEASUREMENT:度量衡表達方式
LC_PAPER:預設紙張尺寸大小
LC_IDENTIFICATION:對locale自身包含資訊的概述
LC_ALL:優先順序最高變數,若設定了此變數,所有LC_* 和LANG變數會強制跟隨它的值
我們看到雖然安裝了中文語言包但本機的語言環境並不是中文,先修改i18n配置檔案
# vim /etc/sysconfig/i18n
新增如下兩行程式碼
LANG="zh_CN.UTF-8"
LC_ALL="zh_CN.UTF-8"

# source /etc/sysconfig/i18n
再修改 locale.cnf配置檔案
# vim /etc/locale.conf
LANG="zh_CN.UTF-8"
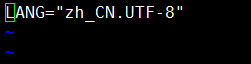
# source /etc/locale.conf
重啟系統
# reboot
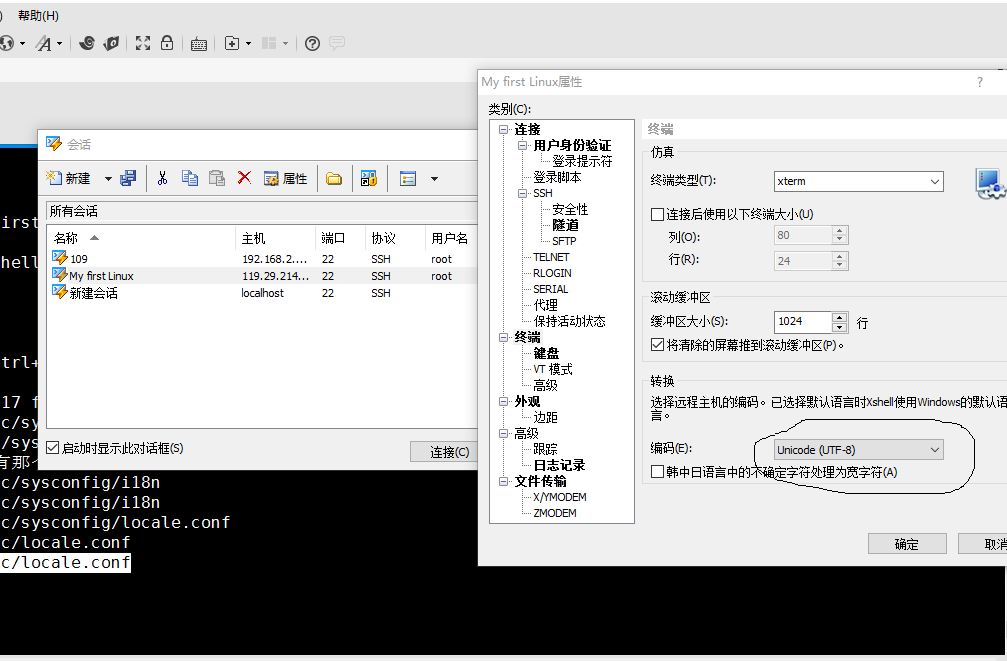
3.設定終端連線編碼
檔案->開啟->選中會話->右鍵->屬性->終端 (我用的終端連線工具是Xshell,其它連線工具更改編碼方式請自行百度)
將編碼改為 UTF-8
重新連線,再檢視當前系統語言環境
# locale

發現系統語言環境已經成功改為 “zh_CN.UTF-8”
再次嘗試編輯中文
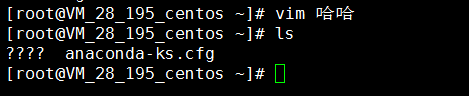
# vim 你是豬嗎

# ls
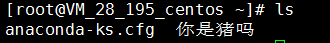
SUCCESS!至此,系統中文亂碼問題已解決。
4.解決Tomcat輸出日誌亂碼
既然系統中文亂碼已經解決了,那麼Tomcat輸出日誌中文亂碼會不會也解決了呢?
我們現在看看Tomcat輸出日誌
進入Tomcat目錄
# cd $CATALINA_HOME
# tail -f ./logs/catalina.out
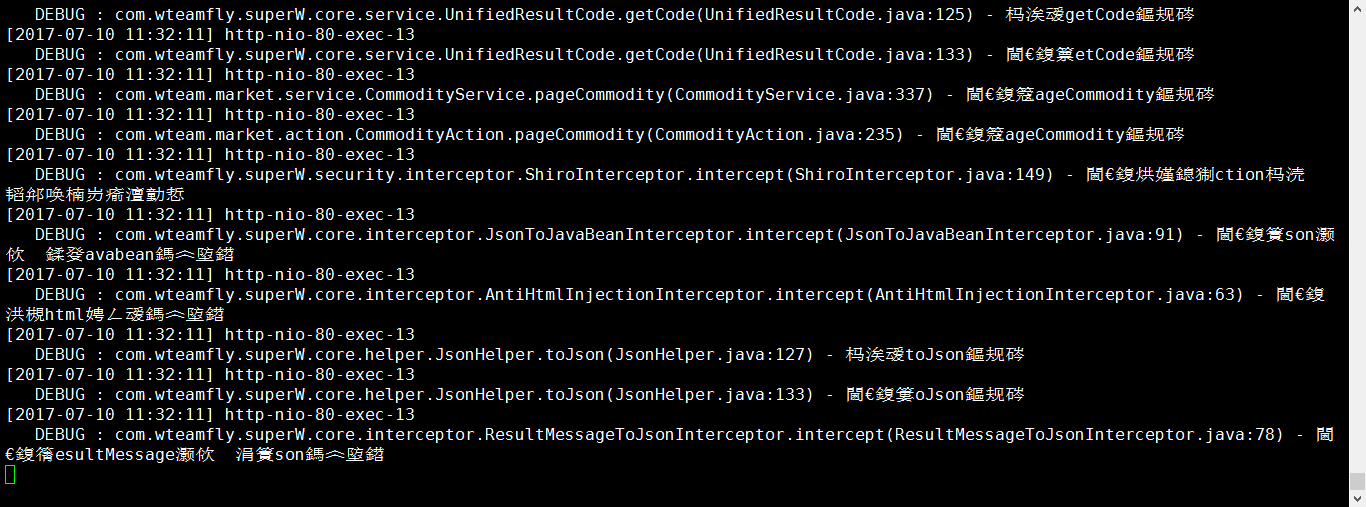
很遺憾,Tomcat日誌中文還是亂碼。
分析:既然系統已經不會出現中文亂碼,證明系統語言環境是正常的,但是Tomcat日誌還會出現中文亂碼,說明是Tomcat內部的問題,網上查了一些資料,知道是JVM(Java Virtual Machine)
java虛擬機器所用的字符集與系統所用的字符集不一致造成的,知道原因,問題就好解決了,可以通過配置JVM的啟動引數來達到修改JVM所使用字符集的目的。
# ls -l ./bin/

找到 daemon.sh 和 catalina.sh 分別加入以下程式碼:
JAVA_OPTS="$JAVA_OPTS -Djavax.servlet.request.encoding=UTF-8 -Dfile.encoding=UTF-8 -Duser.language=zh_CN -Dsun.jnu.encoding=UTF-8"
# vim ./bin/daemon.sh

# vim ./bin/catalina.sh

儲存退出,重啟Tomcat
# ./bin/shutdown.sh
# ./bin/startup.sh
現在再檢視輸出日誌
# tail -f ./logs/catalina.out
向伺服器發一次請求
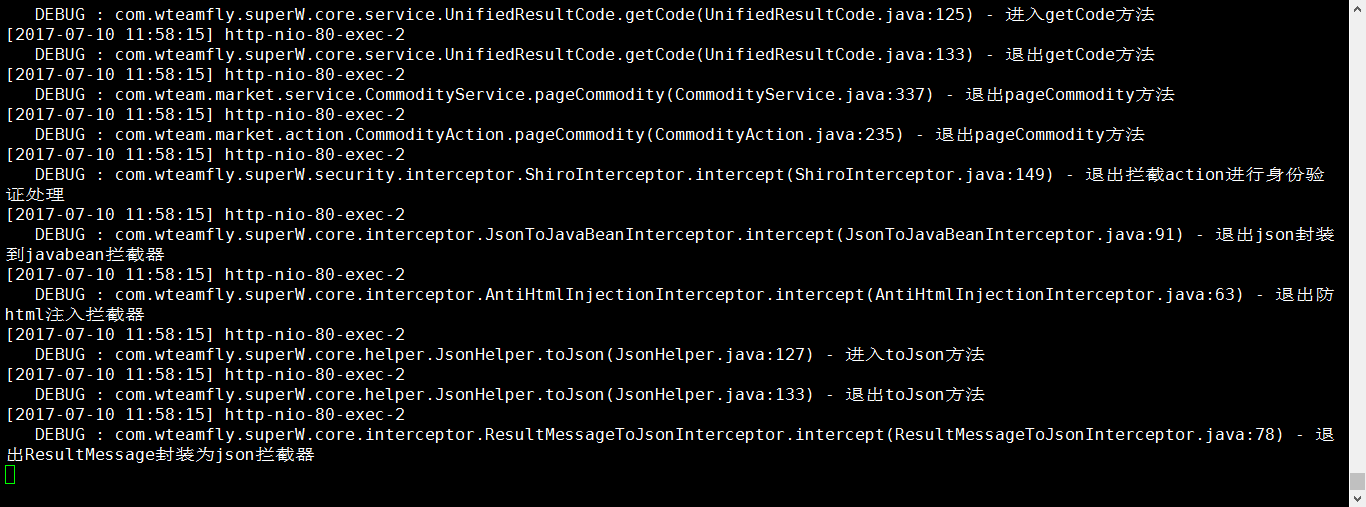
Tomcat輸出日誌中文正常顯示。
end! (*^-^*)
-----------------------------------------------------本人能力有限,有錯誤或者不足之處歡迎指正,也歡迎聯絡我交流學習--------------------------------------------------------------------------------------------------------------------
聯絡方式
- 電子郵箱:[email protected]
- 微訊號:R1284103044
相關推薦
解決CentOS7中文語言亂碼(包括Tomcat日誌中文亂碼)問題
Linux系統中文語言亂碼,是很多小夥伴在開始接觸Linux時經常遇到的問題,而且當我們將已在Wndows部署好的專案搬到Linux上執行時,Tomcat的輸出日誌中文全為亂碼(在Windows上正常),看著非常心塞,那麼我們應該怎麼解決呢?
centos7安裝配置oracle(包括yum下載依賴包)(不含監聽配置)
一、環境準備 安裝包: 1.VMware-workstation-full-11.1.0-2496824.exe 2.CentOS-7-x86_64-DVD-1511.iso 3.linux.x64_11gR2_database_1of2.zip linux.x64_1
解決全站字符亂碼(POST和GET中文編碼問題)
{} tomcat ont throws turn nco cat doget pro 1 說明 亂碼問題: 獲取請求參數中的亂碼問題; POST請求:request.setCharacterEncoding(“utf-8”); GET請求:new String(r
Tomcat日誌中文亂碼問題解決
Tomcat linux Tomcat 日誌中文亂碼 在配置文件/usr/local/tomcat/bin/catalina.sh大概在230多行左右添加綠框內容,註釋紅框內容,重啟Tomcat即可解決亂碼問題 Tomcat服務器記錄日誌(Logger)出現中文亂碼問題,解決辦法:修改Tomcat的
vs 中文亂碼 (包括控制檯)
轉載:http://www.cnblogs.com/Harley-Quinn/p/7487745.html 最近剛換上VS2017,由於手頭又要做個MFC的程式,所以寫控制檯程式做功能測試,然後發現居然亂碼了。 於是用VS2017新建windows控制檯應用程式,在main
解決win10內建自帶應用顯示語言為英文(包括商店,郵件等)
剛剛買了美版電腦,win10系統。按照網上漢化教程,成功漢化,也就是區域,語言,輸入法等能設定成中文的全部設定完成。突然發現自帶的應用全部為英文。然後一直上網搜資料嘗試。最後總結了以下方法,供大家參考,應該都能成功:) 1.點選 控制面板->時鐘、語言和
解決cookie中文亂碼(登入的記住使用者功能)
第一步:在處理登入的servlet中把中文名字編碼為utf-8,然後存入cookie中 第二步:是在jsp頁面中解碼,有兩種方法 方法一:自定義EL函式 *先編寫一個處理解碼的類 *然後建立一個TLD檔案進
MySQL查詢中使用Concat關鍵字來拼接中文字元亂碼(不同的資料型別拼接)解決方式
在MySQL中使用Concat來拼接兩種資料型別的欄位時就會出現亂碼。按照一下的辦法就可以解決這樣的問題。 舉例: concat('數量:',CONVERT(欄位名,char),) SELECT CO
過濾器-解決全站字元亂碼(POST和GET中文編碼問題)
servlet: POST:request.setCharacterEncoding(“utf-8”); GET: String username = request.getParameter(“username”); username = new String(use
在python3.6環境下使用os.walk遍歷所有的中文資料夾,並且列印對應的地址(包括os.walk的語法)
首先來看看資料夾的分佈和文字內容可以看到保險資料夾下有三個資料夾,每個資料夾中又包含許多TXT文字,所有程式碼如下# -*-coding:utf-8-*- import os for root,dirs,files in os.walk(r"C:\Users\ME\Deskt
CentOS7常用軟體的安裝(JDK+Tomcat+Nginx+Redis+MySQL)
JDK安裝一:準備工作1.1、版本號:dk-8u121-641.2、檢查是否存在JDKjava -versionrpm -qa | grep java1.3、若存在則解除安裝rpm -e --nodeps java.. .. .. ..二:安裝步驟解壓縮JDKtar -zxv
Linux下檢視tomcat日誌及亂碼解決方案
檢視日誌:tail -f catalina.out [Linux日誌亂碼][linux中使用tail -f檢視日誌出現中文亂碼的解決方案][linux中檢視tomcat日誌亂碼的解決方案][linux客戶端中文亂碼問題Xshell] 1、vim修改伺服器編碼,把編碼項改為 "zh_CN.UTF-8
B樹之C語言實現(包括查詢、刪除、插入)
我在大二上學期的資料結構實驗設計中選擇了B樹這個題目,該B樹的資料結構實現採用了C語言。趁現在寒假整理完寫一篇博文記錄我的學習。文末提供了專案原始碼的地址。 B樹的定義 一棵m階B樹(Balanced Tree of order m),或為空樹,
iOS10訪問許可權的配置(解決訪問奔潰問題,包括相簿/相機等)
這裡僅以相簿的為例: plist檔案裡面新增,Privacy - Photo Library Usage Description,Value值為描述,彈出的提示框會顯示出來。 修改plist 升到iOS10之後,需要設定許可權的有: 麥克風許可權:Privac
centos7 配置虛擬交換機(物理交換機truckport設置)(使用brctl)
ddb -type onf clas 兩個 tro modprobe min 例如 感謝朋友支持本博客。歡迎共同探討交流,因為能力和時間有限。錯誤之處在所難免,歡迎指正! 假設轉載,請保留作者信息。 博客地址:http://blog.csdn.net/qq_21398
Linux C 讀取文件夾下所有文件(包括子文件夾)的文件名(轉)
文件中 其中 文件類型 sizeof basepath 文件 lose sed int Linux C 下面讀取文件夾要用到結構體struct dirent,在頭#include <dirent.h>中,如下: 1 #include <dirent.h
常用SQL語言概述(DDL、DML、DQL)
oracle sql ddl dml dcl 眾所周知,SQL(Structure Query Language)是數據庫的核心語言,近段時間學習數據庫,部分基礎概念有點模棱兩可,今天索性把這幾個常用的SQL概念簡單記錄下以作區分。分類:DDL:數據定義語言(CREATE、DROP、ALT
centos7下安裝docker(18.3docker日誌---logging driver---fluentd)
發送 dcoker 一個 tag 連接 選擇 路徑 logging logs 前面我們學的ELK中用filebeat收集docker容器日誌,利用的是dcoker默認的logging driver json-file,下面我們用fluentd來收集容器日誌 Flue
青蛙三國誌用戶隱私條款(包括無內購版)
需求 pos 三國 用戶隱私 gpo 內容 功能 所有 展示 青蛙三國誌尊重並保護所有使用服務用戶的個人隱私權。為了給您提供更準確、更有個性化的服務,青蛙三國誌會按照本隱私權政策的規定使用和披露您的個人信息。但青蛙三國誌將以高度的勤勉、審慎義務對待這些信息。除本隱私權政策另
LibreOffice完美解決中文字體問題(在黑暗中摸索了好久~)
方便 成功 ffi 完美解決 str sha 機器 字體 自動 1. 在Windows上面找到需要的字體 首先,在Windows的字體文件夾(C:\Windows\Fonts)裏面找到需要的字體,一般中文為:楷體,宋體,黑體,仿宋,微軟雅黑,英文為:Times New Ro