
python實戰—CITY/KITTI資料集處理
下載資料集
博主打算將SSD演算法用於檢測車載視訊,用到的是CITY資料集。
讀者可以採用KITTI資料集,內容相似,本文主要針對資料進行前期處理,關於該資料集的說明本文就不進行介紹了。
進入官網,找到object一欄,準備下載資料集:
根據下載情況(博主把前四個都下載了,點開看過),進行SSD訓練只需要下載第1個圖片集 Download left color images of object data set (12 GB)和標註檔案 Download training labels of object data set (5 MB) 就夠了。然後將其解壓,發現其中7481張訓練圖片有標註資訊,而測試圖片沒有,這就是本次訓練所使用的圖片數量。由於SSD中訓練指令碼是基於VOC資料集格式的,所以我們需要把KITTI資料集做成PASCAL VOC的格式,其基本架構可以參看這篇部落格:
PS.參看截圖,資料要放在home目錄下的data資料夾,不是caffe中的data資料夾,這個要注意,否則後續指令碼出錯。
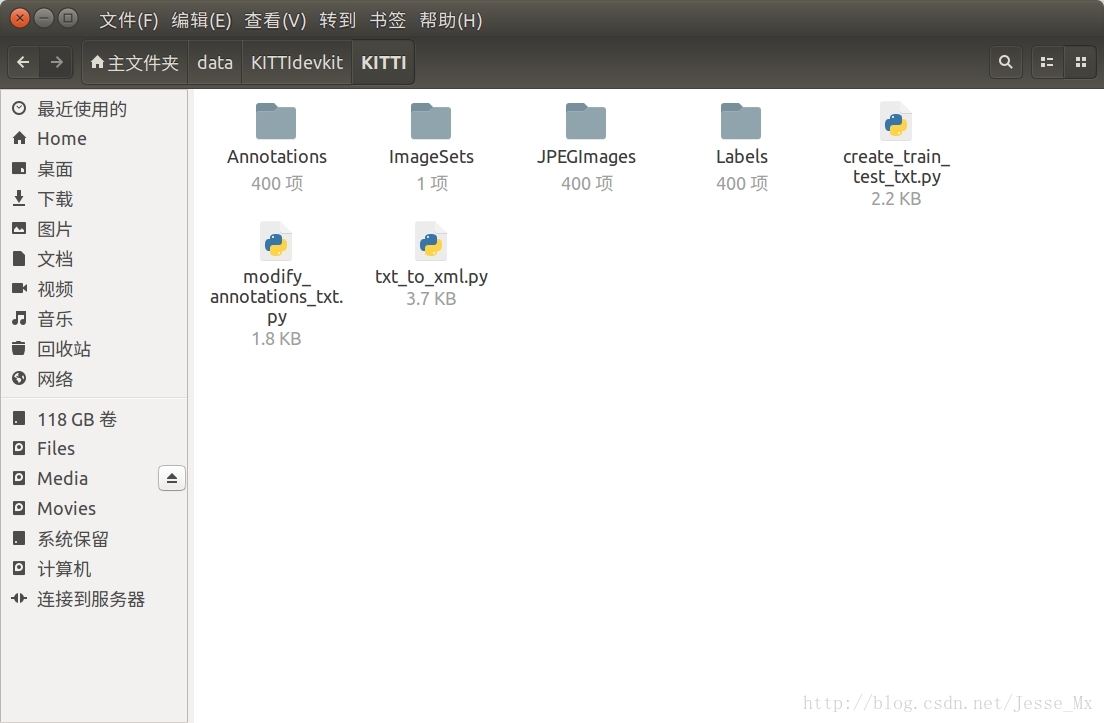
(截圖來源於小規模試驗,圖片只有400張,本人實際測試了2萬張)
轉換資料集
為了方便SSD進行訓練,我們需要將KITTI資料集轉換成PASCAL VOC的格式,細心的朋友可能已經發現,KITTI官網提供了一個工具: code to convert from KITTI to PASCAL VOC file format
轉換KITTI類別
KITTI資料集總共20個類別,如果用於特定場景,20個類別確實多了。此次博主為資料集設定1個類別 ‘Car’,只不過標註資訊中還有其他型別的車和人,直接略過有點浪費,博主希望將 ‘Van’, ‘Truck’, ‘Tram’ 合併到 ‘Car’ 類別中去,將 ‘Person_sitting’,’Cyclist’,’Pedestrian’ 合併到 ‘Pedestrian’ 類別中去,並刪除Pedestrian類。這裡使用的是modify_annotations_txt.py工具,原始碼如下:
# modify_annotations_txt.py
import glob
import string
txt_list = glob.glob('./Labels/*.txt') # 儲存Labels資料夾所有txt檔案路徑
def show_category(txt_list):
category_list= []
for item in txt_list:
try:
with open(item) as tdf:
for each_line in tdf:
labeldata = each_line.strip().split(' ') # 去掉前後多餘的字元並把其分開
category_list.append(labeldata[0]) # 只要第一個欄位,即類別
except IOError as ioerr:
print('File error:'+str(ioerr))
print(set(category_list)) # 輸出集合
def merge(line):
each_line=''
for i in range(len(line)):
if i!= (len(line)-1):
each_line=each_line+line[i]+' '
else:
each_line=each_line+line[i] # 最後一條欄位後面不加空格
each_line=each_line+'\n'
return (each_line)
print('before modify categories are:\n')
show_category(txt_list)
for item in txt_list:
new_txt=[]
try:
with open(item, 'r') as r_tdf:
for each_line in r_tdf:
labeldata = each_line.strip().split(' ')
if labeldata[0] in ['Truck','Van','Tram']: # 合併汽車類
labeldata[0] = labeldata[0].replace(labeldata[0],'Car')
if labeldata[0] in ['Cyclist','Person_sitting']: # 合併行人類
labeldata[0] = labeldata[0].replace(labeldata[0],'Pedestrian')
if labeldata[0] == 'DontCare': # 忽略Dontcare類
continue
if labeldata[0] == 'Misc': # 忽略Misc類
continue
new_txt.append(merge(labeldata)) # 重新寫入新的txt檔案
with open(item,'w+') as w_tdf: # w+是開啟原檔案將內容刪除,另寫新內容進去
for temp in new_txt:
w_tdf.write(temp)
except IOError as ioerr:
print('File error:'+str(ioerr))
# 刪除 Pedestrian行
for item in txt_list:
try:
with open(item, 'r') as r_tdf:
lines = r_tdf.readlines()
with open(item,'w+') as w_tdf: # w+是開啟原檔案將內容刪除,另寫新內容進去
for line in lines:
if "trian" in line:
continue
w_tdf.write(line)
except IOError as ioerr:
print('File error:'+str(ioerr))
print('\nafter modify categories are:\n')
show_category(txt_list)博主申明:刪除Pedestrian行執行時間較慢,應該有更好的思路,歡迎各位提出意見。
不過執行上述檔案後,有些檔案只有Pedestrian類,刪除後就成為了空txt檔案,此時需要刪除txt檔案以及對應的image圖片,採用check_label_0.py,原始碼如下:
# check_label_0.py
# -*- coding: utf-8 -*-
import os
import re
txt_path = "/home/th/data/CITYdevkit/CITY/Labels"
jpg_path = "/home/th/data/CITYdevkit/CITY/JPEGImages"
files = os.listdir(txt_path)
jpg_files = os.listdir(jpg_path)
f = open("/home/th/data/CITYdevkit/CITY/out.txt", 'w+')
i=1
os.chdir(txt_path)
for filename in files:
# # print(portion[0])
# 將檔名和綴名分成倆部分
if os.path.isfile(filename):
if filename.endswith('txt'):
size = os.path.getsize(filename)
if size == 0:
portion = os.path.splitext(filename)
os.remove(txt_path + '/' + filename)
os.remove(jpg_path + '/' + str(portion[0]) + '.jpg')
print(str(i) + ' ' + str(filename),file = f)
i = i+1執行命令:python check_label_0.py 來執行py程式
博主採用的CITY資料集,圖片與txt的命名不是規範,例如1478019973687625979.txt或者11478019973687625979.jpg。因此,需要重新命名txt和jpg名字,改成000001.txt…對應的圖片改成000001.jpg。這裡採用的Label-jpg_rename.py,原始碼如下:
# -*- coding: utf-8 -*-
import os
import re
txt_path = "/home/th/data/CITYdevkit/CITY/Labels"
jpg_path = "/home/th/data/CITYdevkit/CITY/JPEGImages"
files = os.listdir(txt_path)
jpg_files = os.listdir(jpg_path)
f = open("/home/th/data/CITYdevkit/CITY/all_out.txt", 'w+')
i=1
os.chdir(txt_path)
for filename in files:
# print(portion[0])
# 將檔名和綴名分成倆部分
if os.path.isfile(filename):
if filename.endswith('txt'):
portion = os.path.splitext(filename)
jpg_newname = jpg_path + '/' + str(i).zfill(6) + '.jpg'
jpg_filename = jpg_path + '/' + str(portion[0]) + '.jpg'
if os.path.exists(jpg_filename):
os.rename(jpg_filename, jpg_newname)
newname = str(i).zfill(6) + '.txt'
# os.chdir(txt_path)
os.rename(filename, newname)
i = i + 1
else:
os.remove(filename)博主申明:
因為txt檔案多一個,所以應該沒有找到對應的圖片時,相應地應該刪除txt檔案。這裡博主有個思考,若存在000002.txt,此時會原檔案進行覆蓋,因此,為了增強程式碼的魯棒性,讀者可以思考該問題,博主能力有限,讀者不信,可以再次執行該.py會發現檔案少了一半。同時,當重新命名的檔案達到10萬以上,如果高效的完成資料集的處理也是一個難點。
執行命令:python3 Label-jpg_rename.py 來執行py程式
轉換txt標註資訊為xml格式
對原始txt檔案進行上述處理後,接下來需要將標註檔案從txt轉化為xml,並去掉標註資訊中用不上的部分,只留下3類,還有把座標值從float型轉化為int型,最後所有生成的xml檔案要存放在Annotations資料夾中。這裡使用的是txt_to_xml.py工具,此處是由 KITTI_SSD 的程式碼修改而來,感謝作者的貢獻。
# txt_to_xml.py
# encoding:utf-8
# 根據一個給定的XML Schema,使用DOM樹的形式從空白檔案生成一個XML
from xml.dom.minidom import Document
import cv2
import os
defgenerate_xml(name,split_lines,img_size,class_ind):
doc = Document() # 建立DOM文件物件
annotation = doc.createElement('annotation')
doc.appendChild(annotation)
title = doc.createElement('folder')
title_text = doc.createTextNode('KITTI')
title.appendChild(title_text)
annotation.appendChild(title)
img_name=name+'.png'# 可修改為jpg
title = doc.createElement('filename')
title_text = doc.createTextNode(img_name)
title.appendChild(title_text)
annotation.appendChild(title)
source = doc.createElement('source')
annotation.appendChild(source)
title = doc.createElement('database')
title_text = doc.createTextNode('The KITTI Database')
title.appendChild(title_text)
source.appendChild(title)
title = doc.createElement('annotation')
title_text = doc.createTextNode('KITTI')
title.appendChild(title_text)
source.appendChild(title)
size = doc.createElement('size')
annotation.appendChild(size)
title = doc.createElement('width')
title_text = doc.createTextNode(str(img_size[1]))
title.appendChild(title_text)
size.appendChild(title)
title = doc.createElement('height')
title_text = doc.createTextNode(str(img_size[0]))
title.appendChild(title_text)
size.appendChild(title)
title = doc.createElement('depth')
title_text = doc.createTextNode(str(img_size[2]))
title.appendChild(title_text)
size.appendChild(title)
for split_line in split_lines:
line=split_line.strip().split()
if line[0] in class_ind:
object = doc.createElement('object')
annotation.appendChild(object)
title = doc.createElement('name')
title_text = doc.createTextNode(line[0])
title.appendChild(title_text)
object.appendChild(title)
bndbox = doc.createElement('bndbox')
object.appendChild(bndbox)
title = doc.createElement('xmin')
title_text = doc.createTextNode(str(int(float(line[4]))))
title.appendChild(title_text)
bndbox.appendChild(title)
title = doc.createElement('ymin')
title_text = doc.createTextNode(str(int(float(line[5]))))
title.appendChild(title_text)
bndbox.appendChild(title)
title = doc.createElement('xmax')
title_text = doc.createTextNode(str(int(float(line[6]))))
title.appendChild(title_text)
bndbox.appendChild(title)
title = doc.createElement('ymax')
title_text = doc.createTextNode(str(int(float(line[7]))))
title.appendChild(title_text)
bndbox.appendChild(title)
# 將DOM物件doc寫入檔案
f = open('Annotations/'+name+'.xml','w')
f.write(doc.toprettyxml(indent = ''))
f.close()
if __name__ == '__main__':
class_ind=('Pedestrian', 'Car', 'Cyclist')
cur_dir=os.getcwd()
labels_dir=os.path.join(cur_dir,'Labels')
for parent, dirnames, filenames in os.walk(labels_dir): # 分別得到根目錄,子目錄和根目錄下檔案
for file_name in filenames:
full_path=os.path.join(parent, file_name) # 獲取檔案全路徑
f=open(full_path)
split_lines = f.readlines()
name= file_name[:-4] # 後四位是副檔名.txt,只取前面的檔名
img_name=name+'.png'
img_path=os.path.join('/home/mx/KITTI/train_image',img_name) # 路徑需要自行修改
img_size=cv2.imread(img_path).shape
generate_xml(name,split_lines,img_size,class_ind)
print('all txts has converted into xmls')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
執行命令:python3 txt_to_xml.py 來執行py程式,轉換效果如下:
# 原始的000400.txt
Car 0.00 0 -1.67 642.24 178.50 680.14 208.68 1.38 1.49 3.32 2.41 1.66 34.98 -1.60
Car 0.00 0 -1.75 685.77 178.12 767.02 235.21 1.50 1.62 3.89 3.27 1.67 21.18 -1.60
Car 0.67 0 -2.15 885.80 160.44 1241.00 374.00 1.69 1.58 3.95 3.64 1.65 5.47 -1.59
Car 0.00 0 -1.89 755.82 101.65 918.16 230.75 3.55 2.56 7.97 7.06 1.63 23.91 -1.61
Car 0.00 1 -2.73 928.61 177.14 1016.83 209.77 1.48 1.36 3.51 17.33 1.71 34.63 -2.27生成訓練驗證集和測試集列表
用於SSD訓練的Pascal VOC格式的資料集總共就是三大塊:首先是JPEGImages資料夾,放入了所有png圖片;然後是Annotations資料夾,上述步驟已經生成了相應的xml檔案;最後就是imagesSets資料夾,裡面有一個Main子資料夾,這個資料夾存放的是訓練驗證集,測試集的相關列表檔案,如下圖所示:
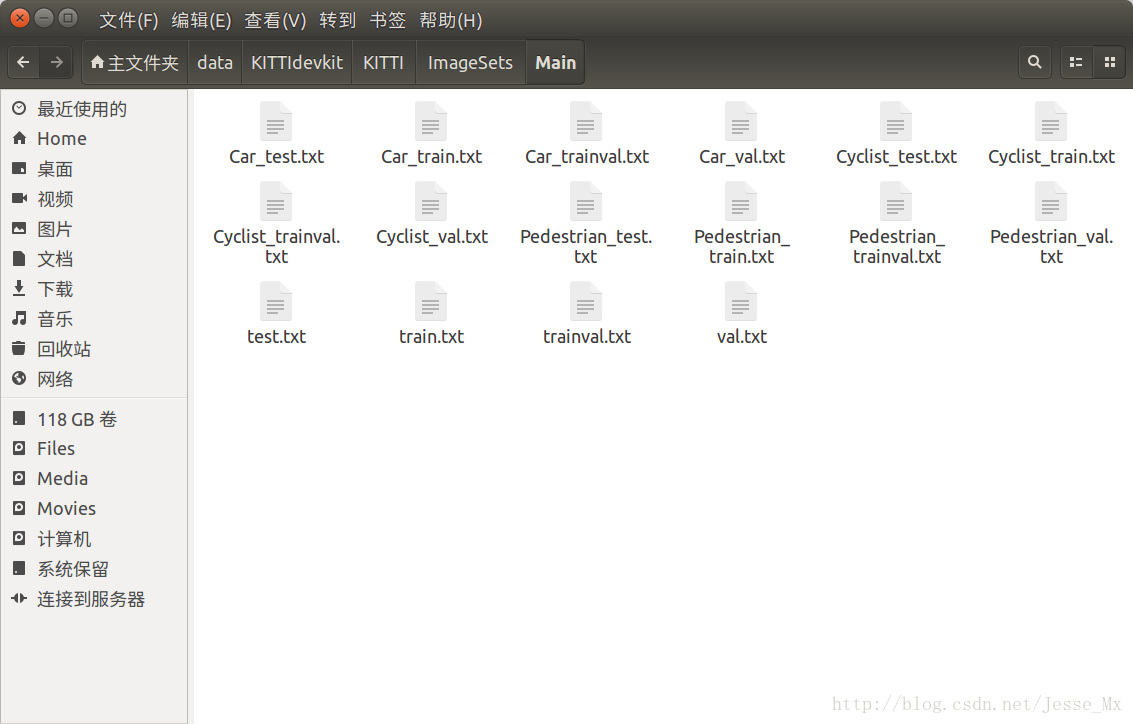
這裡使用create_train_test_txt.py工具,自動生成上述16個txt檔案,其中訓練測試部分的比例可以自行修改,由於這個工具是用Python3寫的,所以執行的時候應該是:
python3 create_train_test_txt.py
# create_train_test_txt.py
# encoding:utf-8
import pdb
import glob
import os
import random
import math
defget_sample_value(txt_name, category_name):
label_path = './Labels/'
txt_path = label_path + txt_name+'.txt'
try:
with open(txt_path) as r_tdf:
if category_name in r_tdf.read():
return ' 1'
else:
return '-1'
except IOError as ioerr:
print('File error:'+str(ioerr))
txt_list_path = glob.glob('./Labels/*.txt')
txt_list = []
for item in txt_list_path:
temp1,temp2 = os.path.splitext(os.path.basename(item))
txt_list.append(temp1)
txt_list.sort()
print(txt_list, end = '\n\n')
# 有部落格建議train:val:test=8:1:1,先嚐試用一下
num_trainval = random.sample(txt_list, math.floor(len(txt_list)*9/10.0)) # 可修改百分比
num_trainval.sort()
print(num_trainval, end = '\n\n')
num_train = random.sample(num_trainval,math.floor(len(num_trainval)*8/9.0)) # 可修改百分比
num_train.sort()
print(num_train, end = '\n\n')
num_val = list(set(num_trainval).difference(set(num_train)))
num_val.sort()
print(num_val, end = '\n\n')
num_test = list(set(txt_list).difference(set(num_trainval)))
num_test.sort()
print(num_test, end = '\n\n')
pdb.set_trace()
Main_path = './ImageSets/Main/'
train_test_name = ['trainval','train','val','test']
category_name = ['Car','Pedestrian','Cyclist']
# 迴圈寫trainvl train val test
for item_train_test_name in train_test_name:
list_name = 'num_'
list_name += item_train_test_name
train_test_txt_name = Main_path + item_train_test_name + '.txt'
try:
# 寫單個檔案
with open(train_test_txt_name, 'w') as w_tdf:
# 一行一行寫
for item in eval(list_name):
w_tdf.write(item+'\n')
# 迴圈寫Car Pedestrian Cyclist
for item_category_name in category_name:
category_txt_name = Main_path + item_category_name + '_' + item_train_test_name + '.txt'
with open(category_txt_name, 'w') as w_tdf:
# 一行一行寫
for item in eval(list_name):
w_tdf.write(item+' '+ get_sample_value(item, item_category_name)+'\n')
except IOError as ioerr:
print('File error:'+str(ioerr))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
執行程式過程中,如遇到pdb提示,可按c鍵,再按enter鍵。
如果想把標註資料全部作為trainval,而把未標註的資料(大約有7000多圖片)作為test,需要重新修改指令碼,待續。
資料集的後續處理
下面進行資料集的後續處理,在/home.mx/caffe/data之下新建KITTI資料夾,用於存放本次訓練所需的指令碼工具,如下圖所示。
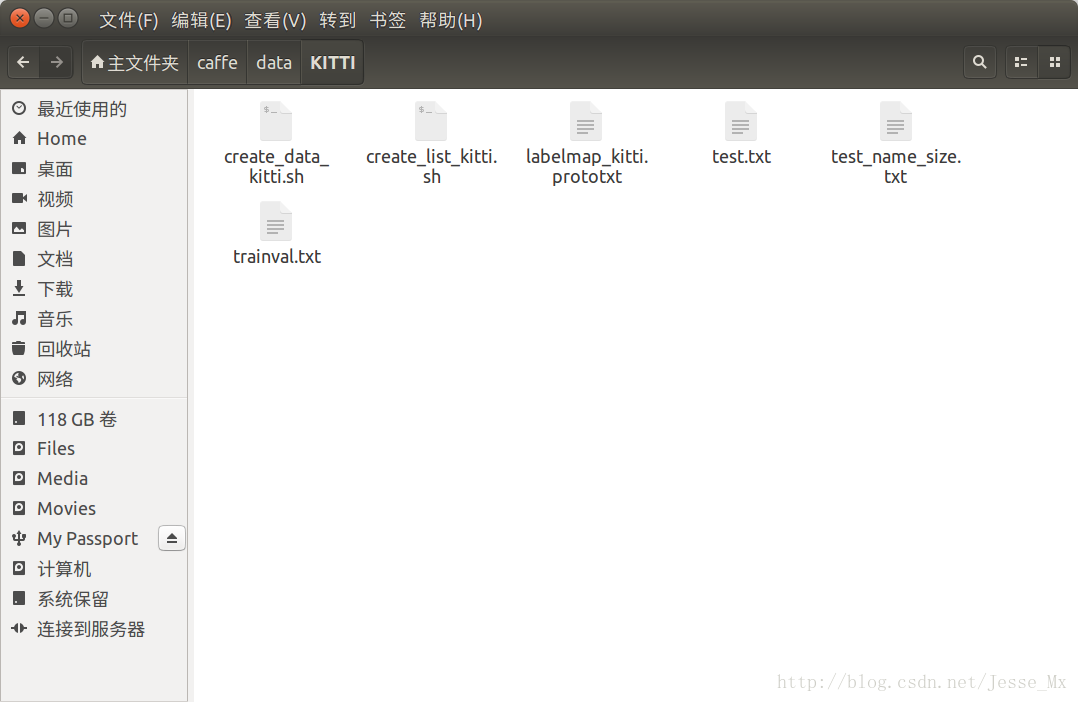
生成訓練所需列表檔案
SSD訓練的時候除了需要LMDB格式的資料以外,還需要讀取三個列表檔案,分別是:trainval.txt,test.txt和test_name_size.txt。前兩個txt檔案存放訓練、測試圖片的png路徑和xml路徑,第三個txt檔案存放測試圖片的名稱和尺寸。所需工具可以由/home/mx/caffe/data/VOC0712/create_list.sh指令碼修改而來。
複製一份上述指令碼,並重命名為create_list_kitti.sh,存放在KITTI資料夾中。經過修改後的指令碼檔案如下(雙#號註釋處為博主修改過的地方):
# create_list_kitti.sh
#!/bin/bash
root_dir=$HOME/data/KITTIdevkit/ ## 自行修改
sub_dir=ImageSets/Main
bash_dir="$(cd "</span><span class="hljs-variable">$(dirname "${BASH_SOURCE[0]}")" && pwd)"for dataset in trainval test
do
dst_file=$bash_dir</span>/<span class="hljs-variable">$dataset.txt
if [ -f $dst_file ]
then
rm -f $dst_file
fi
for name inKITTI## 自行修改do#if [[ $dataset == "test" && $name == "VOC2012" ]] ## 這段可以註釋掉#then#continue#fi
echo "Create list for $name $dataset..."
dataset_file=$root_dir</span>/<span class="hljs-variable">$name/$sub_dir</span>/<span class="hljs-variable">$dataset.txt
img_file=$bash_dir</span>/<span class="hljs-variable">$dataset"_img.txt"
cp $dataset_file</span> <span class="hljs-variable">$img_file
sed -i "s/^/$name\/JPEGImages\//g"</span> <span class="hljs-variable">$img_file
sed -i "s/$/.png/g"</span> <span class="hljs-variable">$img_file## 從jpg改為png
label_file=$bash_dir</span>/<span class="hljs-variable">$dataset"_label.txt"
cp $dataset_file</span> <span class="hljs-variable">$label_file
sed -i "s/^/$name\/Annotations\//g"</span> <span class="hljs-variable">$label_file
sed -i "s/$/.xml/g"</span> <span class="hljs-variable">$label_file
paste -d' '$img_file</span> <span class="hljs-variable">$label_file >> $dst_file
rm -f $label_file
rm -f $img_file
done
# Generate image name and size infomation.if [ $dataset == "test" ]
then$bash_dir</span>/../../build/tools/get_image_size <span class="hljs-variable">$root_dir$dst_file</span> <span class="hljs-variable">$bash_dir/$dataset"_name_size.txt"
fi
# Shuffle trainval file.if [ $dataset == "trainval" ]
then
rand_file=$dst_file.random
cat $dst_file</span> | perl -<span class="hljs-constant">MList::Util</span>=shuffle -e <span class="hljs-string">'print shuffle(<STDIN>);'</span> > <span class="hljs-variable">$rand_file
mv $rand_file</span> <span class="hljs-variable">$dst_file
fi
done- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
執行下面命令,可在/home/mx/caffe/data/KITTI資料夾下生成3個訓練所需txt檔案。
$ cd ~/caffe
$ ./data/KITTI/create_list_kitti.sh- 1
- 2
而生成的txt列表格式如下:
# trainval.txt和test.txt檔案格式
KITTI/JPEGImages/000003.png KITTI/Annotations/000003.xml
KITTI/JPEGImages/000136.png KITTI/Annotations/000136.xml
KITTI/JPEGImages/000022.png KITTI/Annotations/000022.xml
KITTI/JPEGImages/000151.png KITTI/Annotations/000151.xml
......- 1
- 2
- 3
- 4
- 5
- 6
# test_name_size.txt檔案格式
000011 375 1242
000012 375 1242
000035 375 1242
000044 375 1242
......- 1
- 2
- 3
- 4
- 5
- 6
準備標籤對映檔案
由於只有3類,所以可以仿照例子,寫一個labelmap_kitti.prototxt檔案,用於記錄label和name的對應關係,存放在/home/mx/caffe/data/KITTI資料夾中,具體內容如下:
item {
name:"none_of_the_above"
label: 0
display_name: "background"}
item {
name:"Car"
label: 1
display_name: "Car"}
item {
name:"Pedestrian"
label: 2
display_name: "Pedestrian"}
item {
name:"Cyclist"
label: 3
display_name: "Cyclist"}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
生成LMDB資料庫
如果前面一切順利,現在就可以生成LMDB檔案了,所需工具可以由/home/mx/caffe/data/VOC0712/create_data.sh指令碼修改而來。仍然複製一份上述指令碼,並重命名為create_data_kitti.sh,存放在KITTI資料夾中。經過修改後的指令碼檔案如下:
# create_data_kitti.sh
cur_dir=$(<span class="hljs-built_in">cd</span> $( dirname ${BASH_SOURCE[0]} ) && pwd )
root_dir=$cur_dir/../..
cd $root_dir
redo=1
data_root_dir="$HOME/data/KITTIdevkit" ## 自行修改
dataset_name="KITTI" ## 自行修改
mapfile="$root_dir</span>/data/<span class="hljs-variable">$dataset_name/labelmap_kitti.prototxt" ## 自行修改
anno_type="detection"
db="lmdb"
min_dim=0
max_dim=0
width=0
height=0
extra_cmd="--encode-type=jpg --encoded"
if [ $redo ]
then
extra_cmd="$extra_cmd --redo"
fi
for subset in test trainval
do
python $root_dir</span>/scripts/create_annoset.py --anno-type=<span class="hljs-variable">$anno_type --label-map-file=$mapfile</span> --min-dim=<span class="hljs-variable">$min_dim --max-dim=$max_dim</span> --resize-width=<span class="hljs-variable">$width --resize-height=$height</span> --check-label <span class="hljs-variable">$extra_cmd $data_root_dir</span> <span class="hljs-variable">$root_dir/data/$dataset_name</span>/<span class="hljs-variable">$subset.txt $data_root_dir</span>/<span class="hljs-variable">$dataset_name/$db</span>/<span class="hljs-variable">$dataset_name"_"$subset</span><span class="hljs-string">"_"</span><span class="hljs-variable">$db examples/$dataset_name
done- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
執行命令 ./data/KITTI/create_data_kitti.sh 來執行指令碼,將會生成兩份LMDB檔案,路徑分別如下:
$ /home/mx/caffe/examples/KITTI/KITTI_test_lmdb
$ /home/mx/caffe/examples/KITTI/KITTI_trainval_lmdb- 1
- 2
至此,訓練資料可以說已經準備好了。