
人臉識別系列(六):FaceNet
首先可以看一下最終的效果,數字表示兩張圖片經過Facenet提取的特徵之間的歐式距離,可以直接表示兩張圖片的差異:

從圖中可以看出,若取閾值為1.1,可以很輕易的區分出兩張照片是不是同一個人。
網路結構:

上圖是文章中所採用的網路結構,其中,前半部分就是一個普通的卷積神經網路,但是與一般的深度學習架構不一樣,Facenet沒有使用Softmax作為損失函式,而是先接了一個l2**嵌入**(Embedding)層。
所謂嵌入,可以理解為一種對映關係,即將特徵從原來的特徵空間中對映到一個新的特徵空間,新的特徵就可以稱為原來特徵的一種嵌入。
這裡的對映關係是將卷積神經網路末端全連線層輸出的特徵對映到一個超球面上,也就是使其特徵的二範數歸一化,然後再以Triplet Loss為監督訊號,獲得網路的損失與梯度。
Triplet Loss也正是這篇文章的特點所在,接下來我們重點介紹一下。
Triplet Loss
什麼是Triplet Loss呢?顧名思義,也就是根據三張圖片組成的三元組(Triplet)計算而來的損失(Loss)。
其中,三元組由Anchor(A),Negative(N),Positive(P)組成,任意一張圖片都可以作為一個基點(A),然後與它屬於同一人的圖片就是它的P,與它不屬於同一人的圖片就是它的N。
Triplet Loss的學習目標可以形象的表示如下圖:
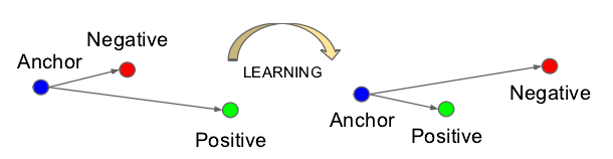
網路沒經過學習之前,A和P的歐式距離可能很大,A和N的歐式距離可能很小,如上圖左邊,在網路的學習過程中,A和P的歐式距離會逐漸減小,而A和N的距離會逐漸拉大。
也就是說,網路會直接學習特徵間的可分性:同一類的特徵之間的距離要儘可能的小,而不同類之間的特徵距離要儘可能的大。
意思就是說通過學習,使得類間的距離要大於類內的距離。
損失函式為:
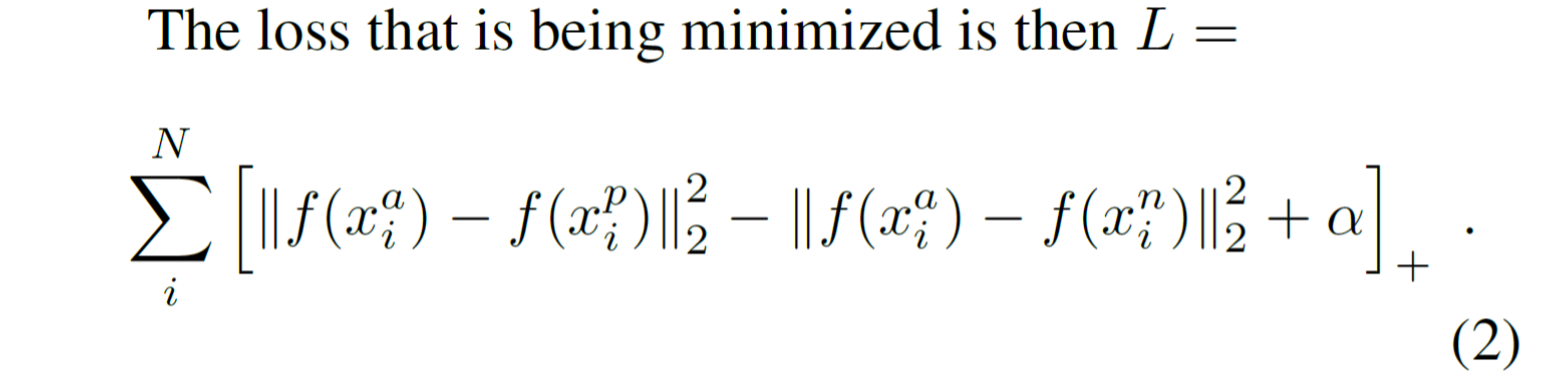
其中,左邊的二範數表示類內距離,右邊的二範數表示類間距離,α是一個常量。優化過程就是使用梯度下降法使得損失函式不斷下降,即類內距離不斷下降,類間距離不斷提升。
提出了這樣一種損失函式之後,實踐過程中,還有一個難題需要解決,也就是從訓練集裡選擇適合訓練的三元組。
選擇最佳的三元組
理論上說,為了保證網路訓練的效果最好,我們要選擇hard positive
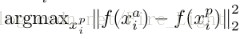
以及hard negative
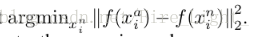
來作為我們的三元組
但是實際上是這樣做會有問題:如果選擇最Hard的三元組會造成區域性極值,網路可能無法收斂至最優值。
因此google大佬們的做法是在mini-batch中挑選所有的 positive 影象對,因為這樣可以使得訓練的過程更加穩固。對於Negetive的挑選,大佬們使用了semi-hard的Negetive,也就是滿足a到n的距離大於a到p的距離的Negative,而不去選擇那些過難的Negetive。
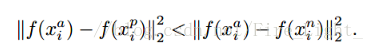
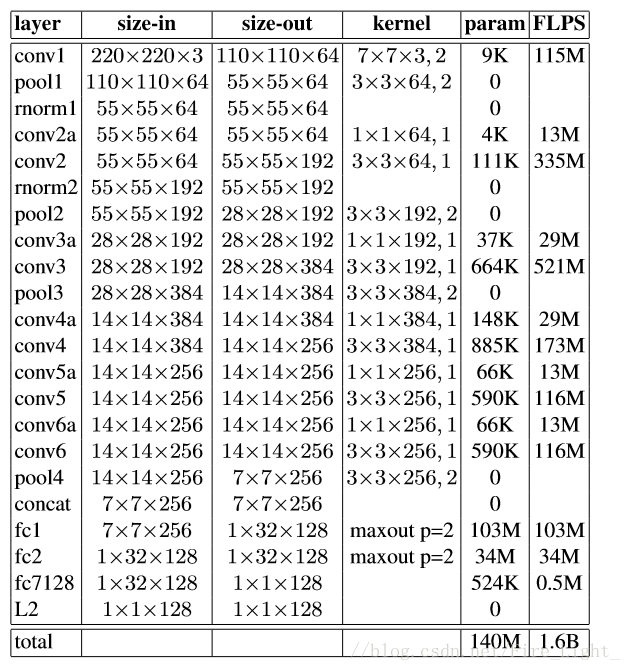
CNN結構
文中嘗試了兩個CNN結構,其引數如下:
網路1:Zeiler&Fergus architecture
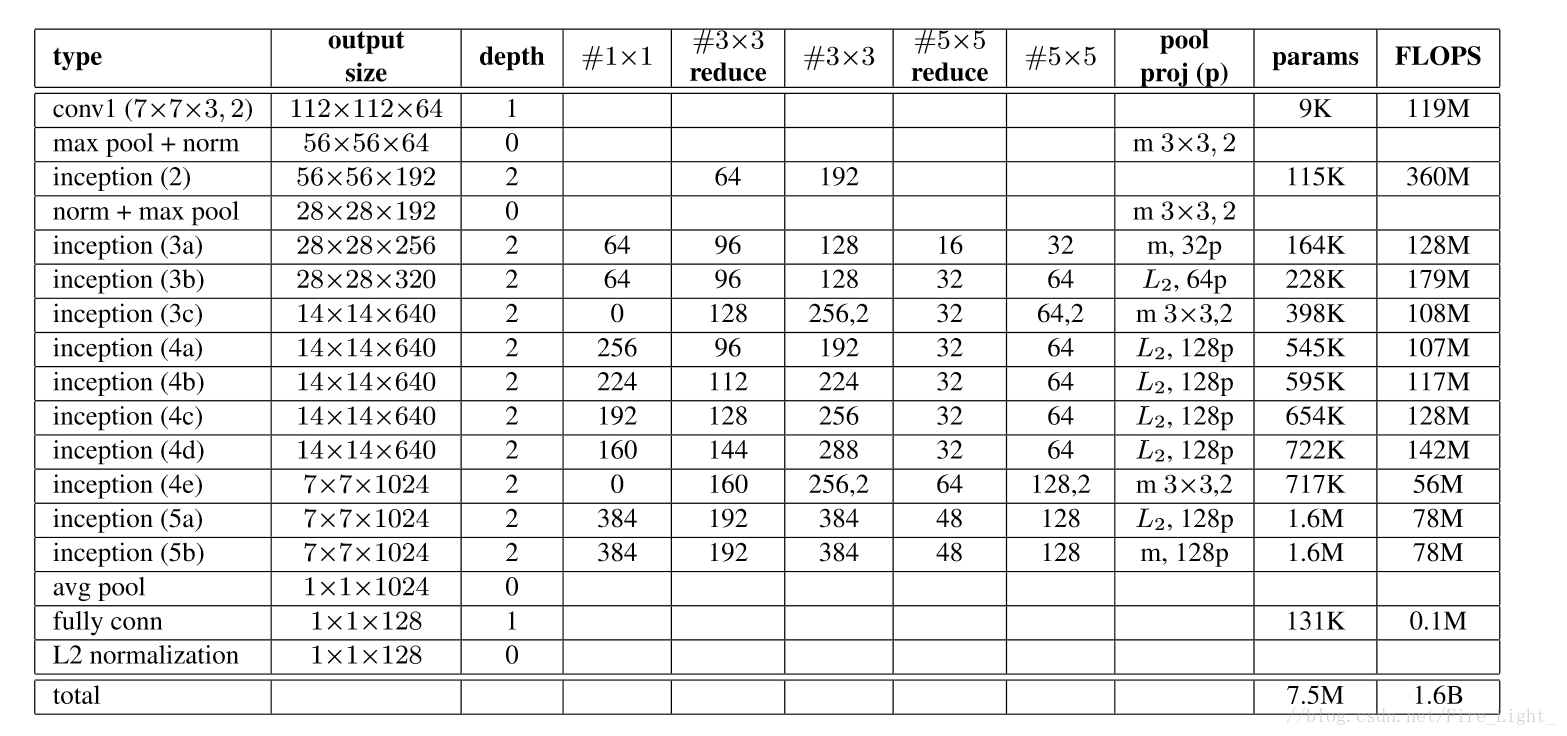
網路2: GoogLeNet
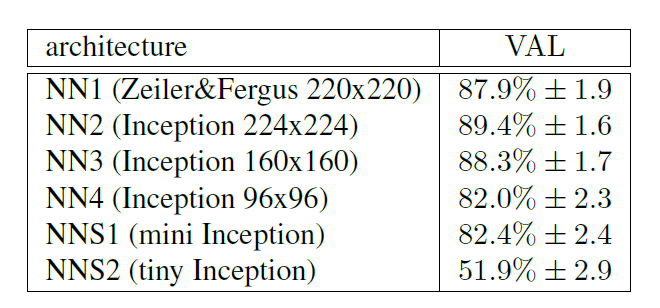
實驗
1. 不同的網路配置下的VAL(validation rate)。
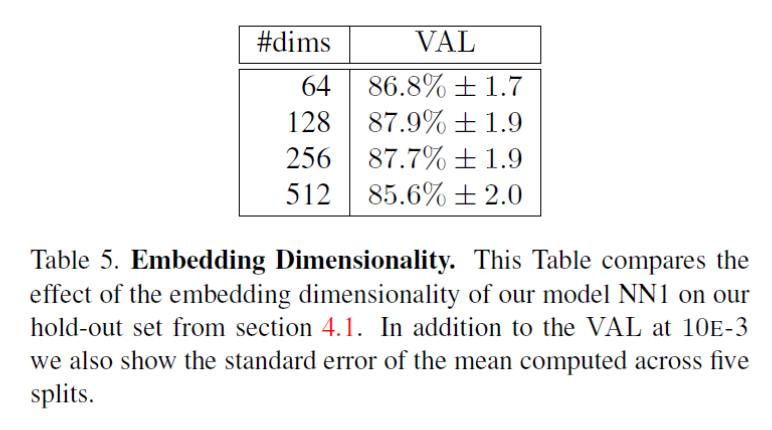
2. 不同的訓練影象資料集的大小。
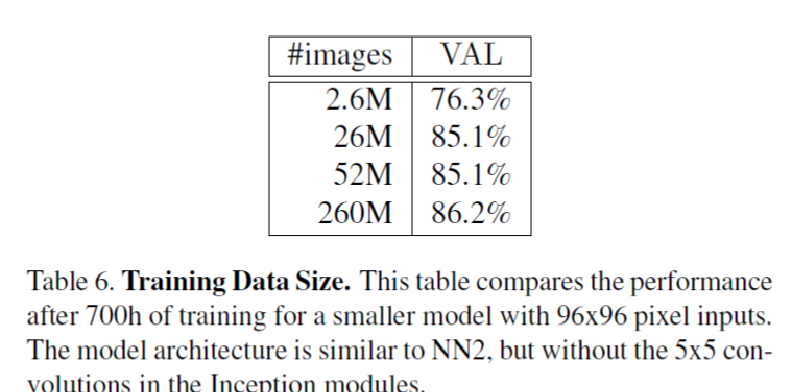
3. 嵌入層特徵的維度對VAL的影響:
4. 不同的影象質量下的VAL:
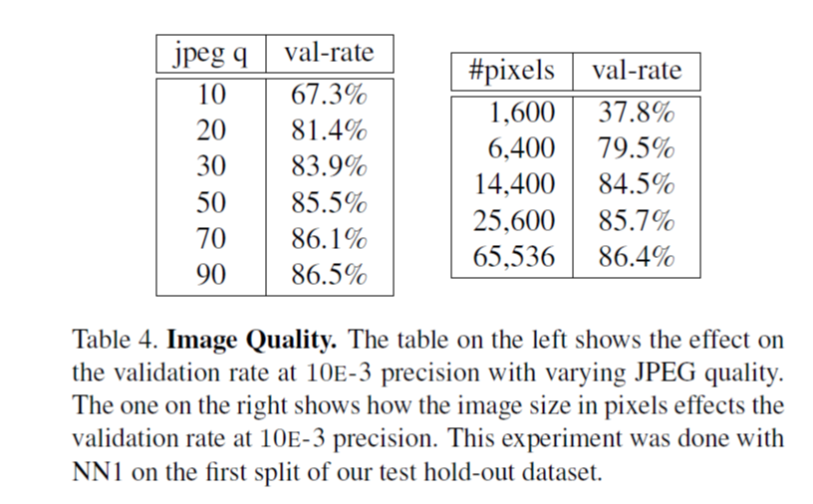
左邊圖表示jpeg影象的質量q對VAL的影響,顯然質量越高,VAL越高,右邊圖表示影象的大小對VAL的影響。
LFW得分
在LFW上達到了98.87% +-0.15的驗證準確率
如果預先使用更好的人臉檢測演算法來對齊人臉,最高可以達到99.63% +-0.09 的驗證準確率。