
ANR型別及解決方法 && 基本演算法 && HashMap原理
一、ANR型別
ANR(Application Not Responding,即應用無響應)一般有三種類型:
1:KeyDispatchTimeout(5 seconds) --主要型別
按鍵或觸控事件在特定時間內無響應,dispatchTimeout 輸入事件分發超時,一般是由於主執行緒在5秒之內沒有響應輸入事件。具體的超時時間的定義在framework下的ActivityManagerService.java。
2:BroadcastTimeout(10 seconds)
BroadcastReceiver在特定時間內無法處理完成
3:ServiceTimeout(20 seconds) --小概率型別
Service在特定的時間內無法處理完成
二、超時原因
超時時間的計數一般是從按鍵分發給app開始。超時的原因一般有兩種:
(1)當前的事件沒有機會得到處理(即UI執行緒正在處理前一個事件,沒有及時的完成或者looper被某種原因阻塞住了)
(2)當前的事件正在處理,但沒有及時完成
三:如何避免KeyDispatchTimeout
1:UI執行緒儘量只做跟UI相關的工作,應該避免在BroadcastReceiver裡做耗時的操作或計算,替代的是,如果響應Intent廣播需要執行一個耗時的動作的話,應用程式應該啟動一個 Service。
2:耗時的工作(比如資料庫操作,I/O,連線網路或者別的有可能阻礙UI執行緒的操作)把它放入單獨的執行緒處理
3:儘量用Handler來處理UIthread和別的thread之間的互動
--------------------------------------------------------------------基本演算法----------------------------------------------------------------------------------------------------
1.圖的遍歷之深度優先搜尋(Depth First Search):
假設初始狀態是圖中所有的點未曾訪問,則深度優先搜尋可從圖中的某個頂點v出發,然後依次從v的未被訪問的臨界點出發深度有限遍歷圖,直至圖中所有和v有路徑相通的點都被訪問到。若圖中尚有點未被訪問,則另選圖中一個未曾被訪問的點作為起始點,重複上述過程,直至圖中所有的點都被訪問到為止。
2.圖的遍歷之廣度優先搜尋(Breadth First Search):
假設從圖中某個頂點v出發,在訪問了v之後依次訪問v的各個未曾訪問過的鄰接點,然後分別從這些鄰接點出發依次訪問它們的鄰接點,並使“先被訪問的頂點的鄰接點”先於“後被訪問的頂點的鄰接點”被訪問,直至圖中所有已被訪問的定點的鄰接點都被訪問為止。
換句話說,廣度優先遍歷的過程是以v為起始點,由近及遠,依次訪問和v有路徑相通且路徑長度依次為1,2,...的頂點。
3.氣泡排序(Bubble Sort):
首先將第一個記錄和第二個記錄比較,若為逆序,則將兩個記錄交換,然後比較第二個記錄和第三個記錄,依次類推,直到第n-1和n進行比較為止。上述過程稱為第一趟氣泡排序,其結果使得最大的記錄被安置到最後的位置上。然後進行第二趟氣泡排序,對前n-1個記錄進行同樣的操作,其結果是次大的記錄被安置到n-1的位置。整個過程需要n(n-1)/2次比較,時間複雜度為O(n*n)。
4.快速排序(Quick Sort):
是對氣泡排序的一種改進。它的基本思想是:先選取一箇中間數,通過一趟排序將記錄分成兩個部分,一邊的記錄均比另一邊小,然後分別對這兩部分記錄進行排序,以達到整個序列有序。
5.希爾排序
希爾排序的基本思想是:
把記錄按步長 gap 分組,對每組記錄採用直接插入排序方法進行排序。
隨著步長逐漸減小,所分成的組包含的記錄越來越多,當步長的值減小到 1 時,整個資料合成為一組,構成一組有序記錄,則完成排序。
6.二分查詢或折半查詢(Binary Search):
在一組已經從小到大有序的記錄中,假設指標low和high分別指示上界和下屆,mid指示中間位置。然後比較給定值key和mid的大小,如果key < mid,那麼high = mid,再重新求得mid值,然後再跟key比較,直到查詢成功為止。
7.雜湊查詢:
雜湊查詢是為了快速查詢記錄的一種演算法,它利用的資料結構是雜湊表,即以空間換取時間的演算法,例如:在圖書館中,根據每個人的名字來查找個人資訊(借書時間,名字等),這些資訊存放於資料庫中,即物理儲存系統中,比如xiaozhang,雜湊演算法可以是:把他的資訊存放於把名字的每個字母之和的實體地址上,當然這是理想化的,肯定會比這個複雜的
-----------------------------------------------------------------------------HashMap原理-------------------------------------------------------------------------------------------------------
1.HashMap的資料結構
陣列的特點是:定址容易,插入和刪除困難;而連結串列的特點是:定址困難,插入和刪除容易。那麼我們能不能綜合兩者的特性,做出一種定址容易,插入刪除也容易的資料結構?答案是肯定的,這就是我們要提起的雜湊表,雜湊表有多種不同的實現方法,我接下來解釋的是最常用的一種方法—— 拉鍊法,我們可以理解為“連結串列的陣列” ,如圖:
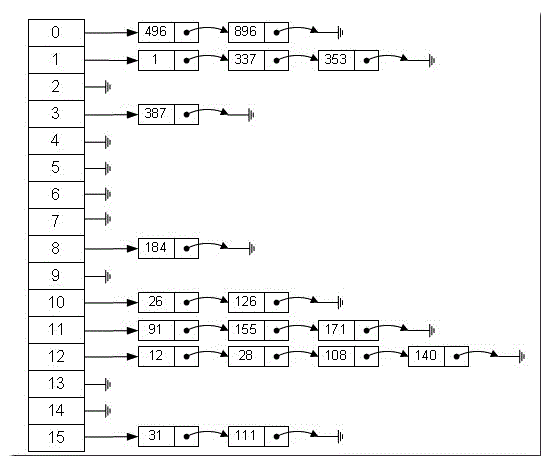
從上圖我們可以發現雜湊表是由陣列+連結串列組成的,一個長度為16的陣列中,每個元素儲存的是一個連結串列的頭結點。那麼這些元素是按照什麼樣的規則儲存到陣列中呢。一般情況是通過hash(key)%len獲得,也就是元素的key的雜湊值對陣列長度取模得到。比如上述雜湊表中,12%16=12,28%16=12,108%16=12,140%16=12。所以12、28、108以及140都儲存在陣列下標為12的位置。
最後對於放在一列的12、28、108以及140,可以通過再次雜湊或者其他函式計算儲存位置,過程就像找圖書館裡的書一樣,所以時間複雜度是O(1).