
python爬取圖片零基礎
一、爬蟲環境
1.python版本:python 3
2.anaconda
3.requests模組
4. PyCharm編輯器
二、安裝環境
1.安裝anaconda
在anaconda官網https://www.anaconda.com/進行下載(如果看不懂英文可以用谷歌瀏覽器或者QQ瀏覽器開啟)

選擇下載python3.6版本(根據自己電腦系統下載32位或64位)進行安裝。
2.用anaconda安裝requests模組
以管理員身份執行anaconda(我也不知道為什麼要用管理員身份執行,好像是以為之前安裝別的東西沒用管理員執行總
是安裝出錯)
不管了,就用管理員安裝。在anaconda中輸入:conda install requests 進行安裝
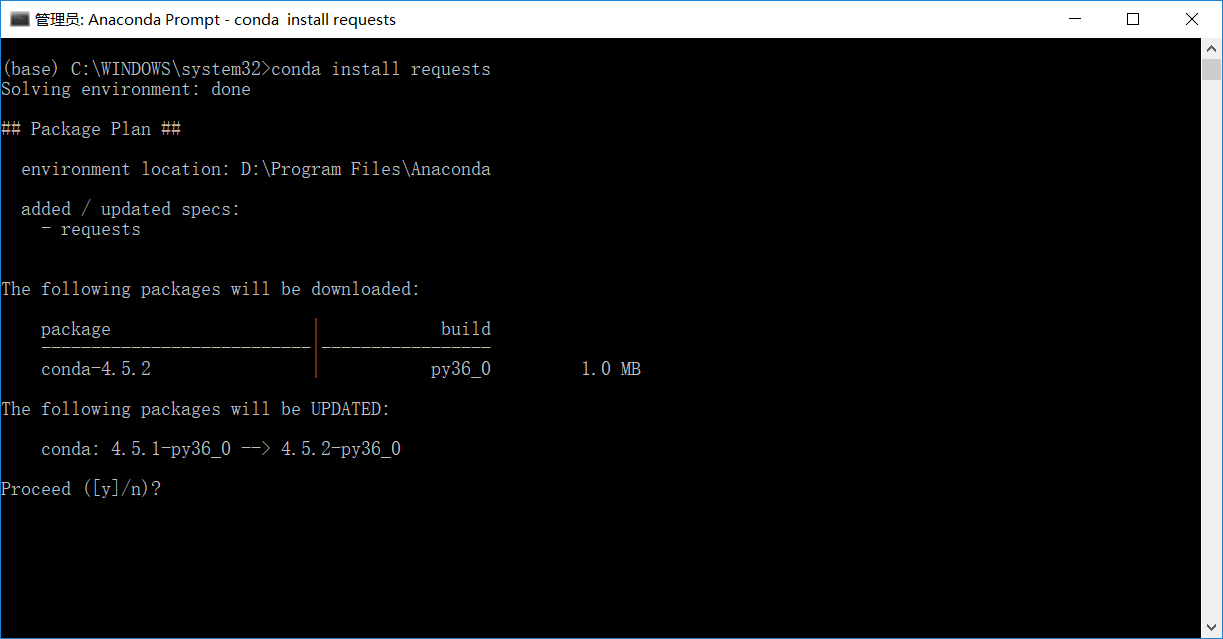
由於我安裝過了就不安裝了,輸入:y 就會繼續安裝了。安裝完成可以輸入:conda list 檢視
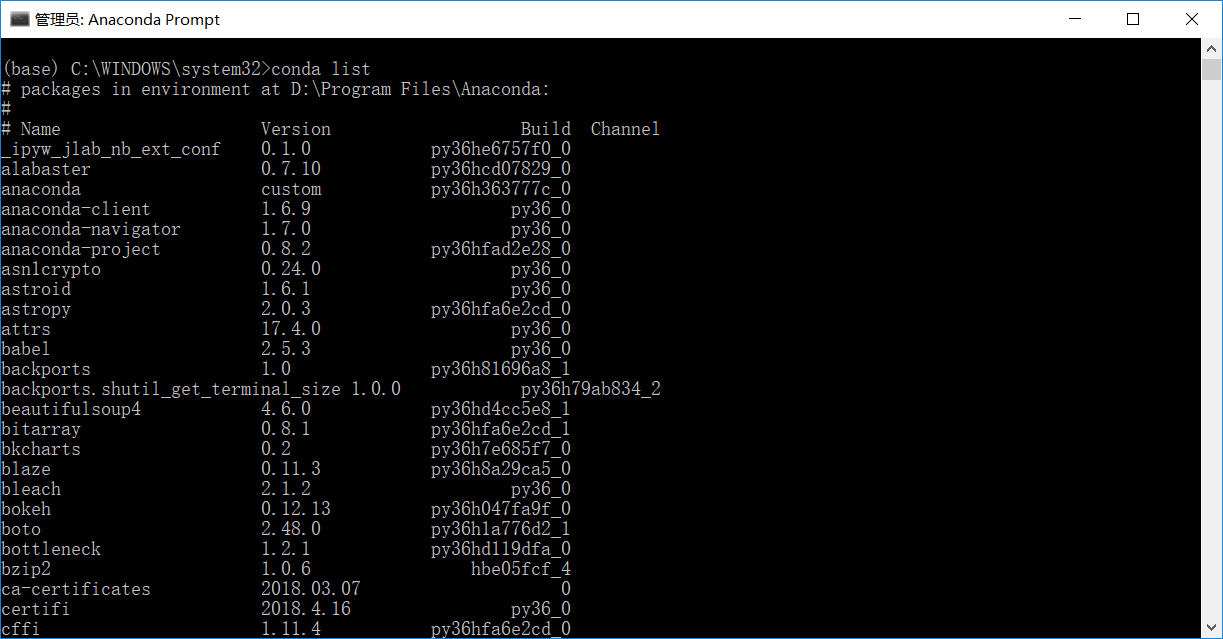
在其中就可以找到requests,requests安裝完成。
3.安裝PyCharm編輯器
在https://www.jetbrains.com/pycharm/中進行下載並安裝。在安裝完PyCharm後一定要記得配置,如果電腦中有多 個python版本一定要配置為你安裝的anaconda路徑中的python.exe,否則安裝的requests模組會匯入不了。4.PyCharm的配置
開啟PyCharm 點File -> settings
按截圖點選進入
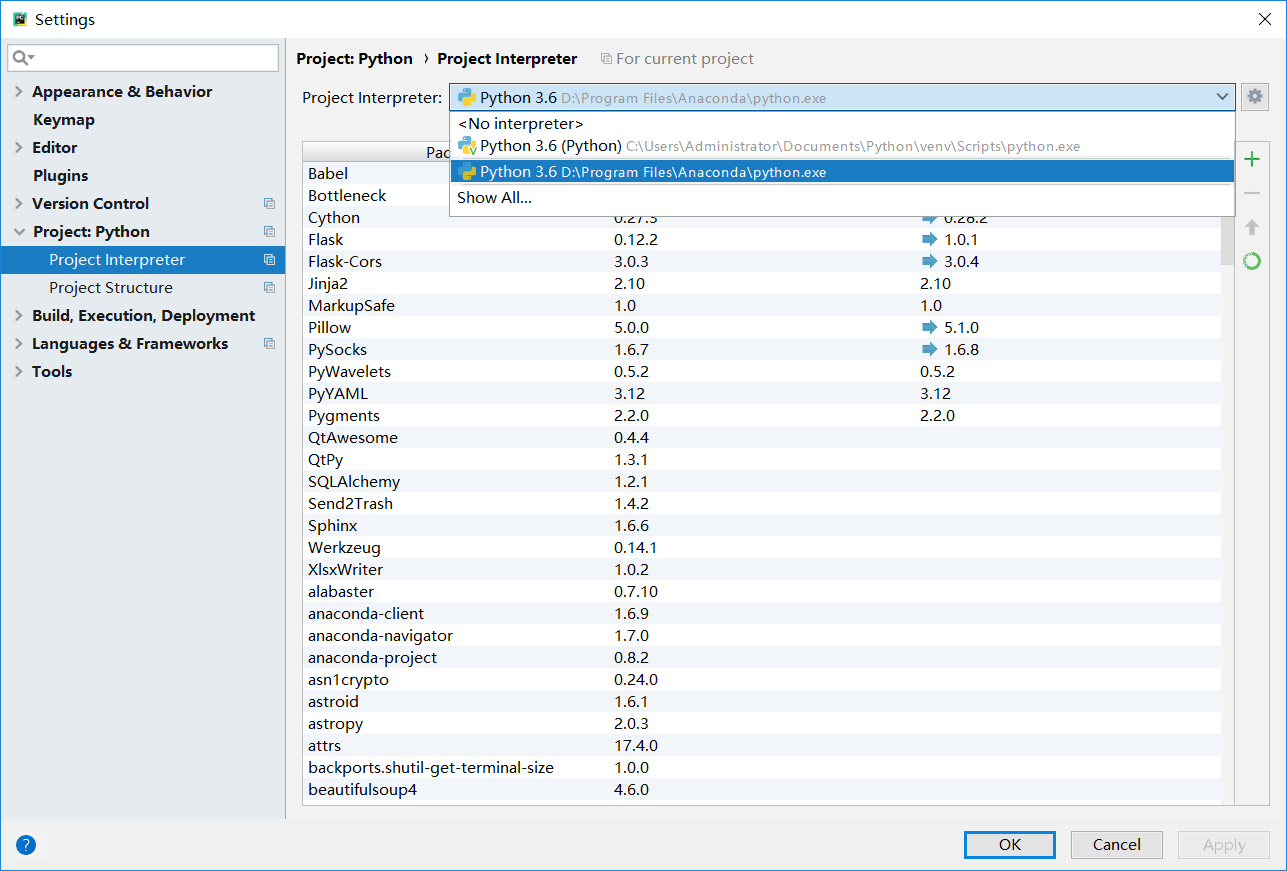
進入此頁面後點擊Proje:Python ->Project Interpreter在右邊選擇anaconda安裝路徑中的Python.exe, 再點選右下角OKPyCharm配置完成。
三、程式碼部分
1.requests模組的使用
用requests模組向網頁傳送get請求,在此之前先介紹一下今天要爬取的網站“http://unsplash.com
import requests #匯入requests庫 headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36'} #給請求指定一個請求頭來模擬chrome瀏覽器 res = requests.get('https://unsplash.com') #像目標url地址傳送get請求,返回一個response物件 print(res.text) #r.text是http response的網頁HTML
這樣就可以輸出網頁原始碼,輸出結果為
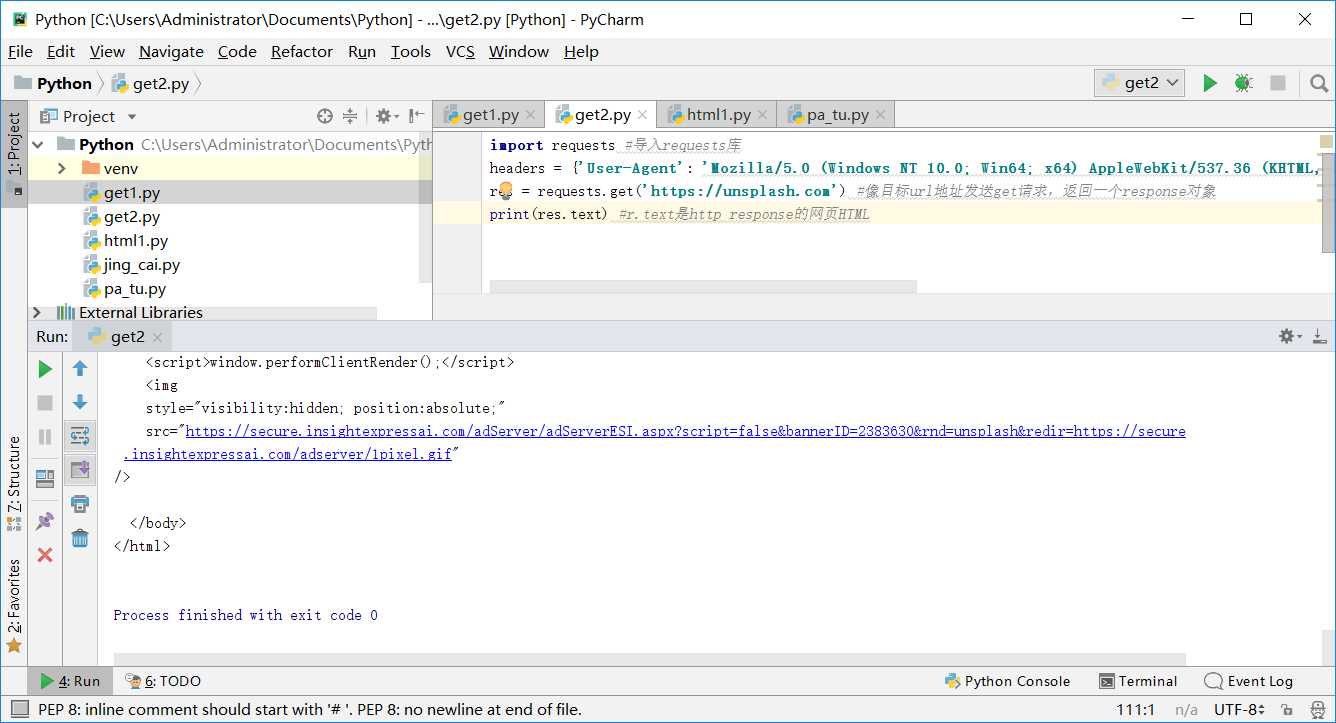
第一步完成,有沒有一絲絲成就感?
2.分析網頁原始碼
在瀏覽器中開啟http://unsplash.com網站按F12再點圖中的選擇元素(建議用谷歌瀏覽器,我發現IE瀏覽
器查詢到的元素對應原始碼和PyCharm獲取到的有一些差別)
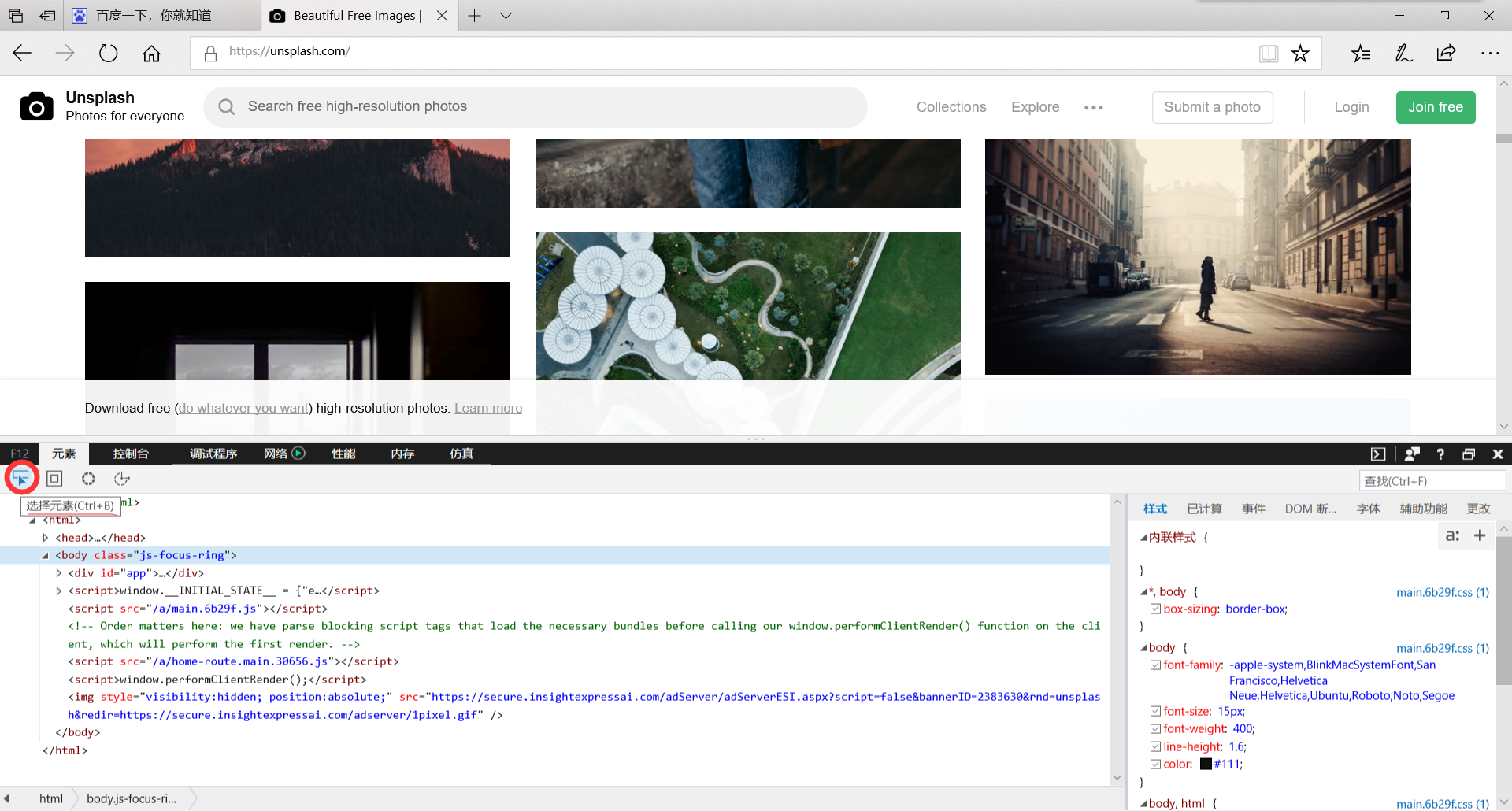
再在網頁中點選一張圖片
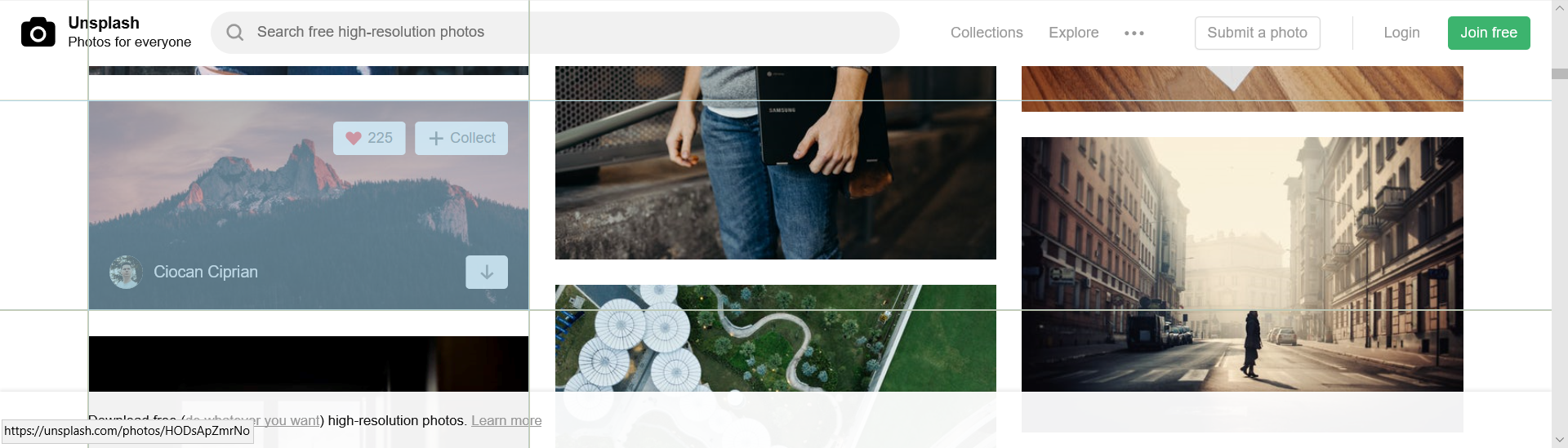
點選後此元素的原始碼部分就找到了,這個圖片的網路地址就是下圖中藍色的部分

你可以對比多個圖片元素的網路地址,接下來考慮考慮怎麼用python程式碼把這些網路地址一一摘出來。
3.用正則表示式摘出圖片網路地址
寫到此處我突然發現很難受,這個網頁的原始碼和我前幾天寫的時候有一點變動我之前寫的正則表示式不
能用了,下來就說說正則表示式的用法吧,你在學習的時候再臨時分析正好加深學習。
先找幾個元素程式碼對比一下
<img itemprop="thumbnailUrl" data-test="standard-photo-grid-multi-col-img" sizes="(min-width: 1335px) 416px,(min-width: 992px) calc(calc(100vw - 72px) / 3), (min-width: 768px) calc(calc(100vw - 48px) / 2), 100vw" srcset="https://images.unsplash.com/photo-1521780372272-bb5e0f455dcf?ixlib=rb-0.3.5&ixid=eyJhcHBfaWQiOjEyMDd9&s=ca8871f351fa47ea3f969912a157b235&auto=format&fit=crop&w=100&q=60 100w,
<img itemprop="thumbnailUrl" data-test="standard-photo-grid-multi-col-img" sizes="(min-width: 1335px) 416px, (min-width: 992px) calc(calc(100vw - 72px) / 3), (min-width: 768px) calc(calc(100vw - 48px) / 2), 100vw" srcset="https://images.unsplash.com/photo-1523768817242-39ab4249a6d5?ixlib=rb-0.3.5&ixid=eyJhcHBfaWQiOjEyMDd9&s=14e85dfb408586029279636308bca290&auto=format&fit=crop&w=100&q=60 100w,
<img itemprop="thumbnailUrl" alt="Walt Disney Concert Hall at dusk" data-test="standard-photo-grid-multi-col-img" sizes="(min-width: 1335px) 416px, (min-width: 992px) calc(calc(100vw - 72px) / 3), (min-width: 768px) calc(calc(100vw - 48px) / 2), 100vw" srcset="https://images.unsplash.com/photo-1496277397776-ca8089ecc5b7?ixlib=rb-0.3.5&ixid=eyJhcHBfaWQiOjEyMDd9&s=8788c40854a2dece7b70927c31806802&auto=format&fit=crop&w=100&q=60 100w,這些就是我們需要的部分html程式碼,怎麼用正則表示式從所有html原始碼中獲取這些片段呢
chapter_photo_list=re.findall(r'<img itemprop="thumbnailUrl".*?100w,',html)

從圖中可以看出就這一句正則表示式就可以摘出這些片段下來解釋解釋正則表示式。
上面那句正則表示式中單引號裡帶下劃線的就是我們要補充的,後面的html就對應的是上面的網頁原始碼。
這句中的 .*? 你可以理解為此處略去n個字,這句正則表示式的意思就是在html中匹配出所有以'<img itemprop=“thumbnilUrl”'開頭以 '100w' 結尾的片段。
事實上現在獲取到的片段有一部分是多餘的,我們真正需要的只有 srcset="後面的Url 也就是上圖中藍色
的連結。
下來更改正則表示式
chapter_photo_list=re.findall(r'<img itemprop="thumbnailUrl".*?srcset="(.*?)100w,',html)看看執行結果

成功了現在只剩下圖片地址了。和之前的正則表示式比較比較有什麼不同?
中間多了 srcset="(.*?) 大家需要了解的就是(.*?)它就代表獲取 srcset=”與 100w之間的部分
有人會想為什麼不直接寫
chapter_photo_list=re.findall(r'srcset="(.*?)100w,',html)而要寫成那樣?
因為這個網頁原始碼中不是隻有圖片Url的時候才有,如果你那樣寫會獲取到好多沒有的,所以前面那部
分必須有它起到了定位的作用。
在這裡再展示一下以上程式碼
import requests #匯入requests庫
import re #寫正則表示式要匯入的
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36'} #給請求指定一個請求頭來模擬chrome瀏覽器
res = requests.get('https://unsplash.com') #像目標url地址傳送get請求,返回一個response物件
print(res.text) #r.text是http response的網頁HTML
res.encoding='utf-8' #把獲取到的原始碼格式改為utf-8,避免漢子亂碼
html=res.text
chapter_photo_list=re.findall(r'<img itemprop="thumbnailUrl".*?srcset="(.*?)100w,',html)
print(chapter_photo_list)4.建立資料夾並切換路徑
os.mkdir('D:\BeautifulPicture') #建立資料夾
os.chdir('D:\BeautifulPicture') #切換路徑至上面建立的資料夾在寫這兩句程式碼之前要先匯入os,就是在開頭寫import os 你也可以在下面的程式碼中看到。
5.下載圖片
for chapter_photo in chapter_photo_list: #從圖片列表中迴圈取出每一個圖片網路地址
print(chapter_photo)
url=chapter_photo
name=re.findall(r'photo-(.*?)-',chapter_photo)[0] #用正則表示式在網路地址中匹配出一段作為jpg檔案的命名
print(name)
img = requests.get(url)
file_name = name + '.jpg'
print('開始儲存圖片')
f = open(file_name, 'ab')
f.write(img.content)
print(file_name, '圖片儲存成功!')
f.close()有沒有發現這裡的正則表示式又有不同?
這裡的正則表示式後面多了一個 [0] ,這樣就是為了避免它匹配符合條件的所有,[0]就是匹配到符合要求
的第一部分,[1]就是符合要求的第二部分,以此類推就像陣列一樣。
6.完整程式碼
import requests #匯入requests庫
import re #寫正則表示式要匯入的
import os
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36'} #給請求指定一個請求頭來模擬chrome瀏覽器
res = requests.get('https://unsplash.com') #像目標url地址傳送get請求,返回一個response物件
print(res.text) #r.text是http response的網頁HTML
res.encoding='utf-8' #把獲取到的原始碼格式改為utf-8,避免漢子亂碼
html=res.text
chapter_photo_list=re.findall(r'<img itemprop="thumbnailUrl".*?srcset="(.*?)100w,',html)
print(chapter_photo_list)
#os.mkdir('D:\BeautifulPicture') #建立資料夾
os.chdir('D:\BeautifulPicture') #切換路徑至上面建立的資料夾
for chapter_photo in chapter_photo_list:
print(chapter_photo)
url=chapter_photo
name=re.findall(r'photo-(.*?)-',chapter_photo)[0]
print(name)
img = requests.get(url)
file_name = name + '.jpg'
print('開始儲存圖片')
f = open(file_name, 'ab')
f.write(img.content)
print(file_name, '圖片儲存成功!')
f.close()應注意建立資料夾時應注意是否存在此資料夾,如果此資料夾存在應註釋掉對應語句或刪除資料夾或改創
建路徑。
看看執行結果


執行完你會發現只有十張圖片,這是因為這個網站是下拉式的它沒有頁數。如果感興趣可以繼續學習怎麼
用程式碼實現下拉動作,或找有頁數的圖片網下載全網圖片。謝謝觀看!