
深度學習Attention機制在短文字分類上的應用——qjzcy的部落格
阿新 • • 發佈:2019-02-15
平常我們對分類的判斷也是基於標題中的某些字,或者某些詞性。比如《姚明籃球打的怎樣》應該判別為體育,這時候“姚明”,“籃球”應該算對我們比較重要的詞彙。詞性我們關注點在“人名”和“名詞”上面,深度學習的attention機制剛好符合這個特點。我們能不能利用attention機制來做分類呢,並且讓注意力集中在我們期望的詞上呢?
先貼個結果,
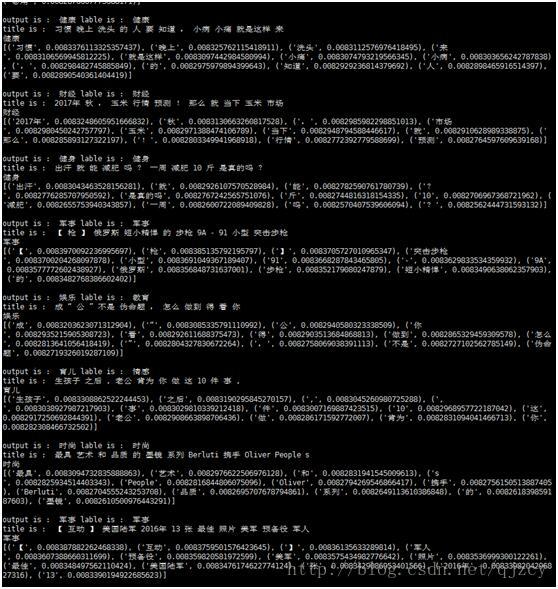
output是機器跑的分類結果,lable是人工打的分類結果。最後一段是機器對每個詞的權重打分
準確率大概在95%左右。使用詞性後準確率和attention的可解釋性都得到了提升。
格式:
第一行‘輸出’ ‘標籤’
第二行 ‘輸入’ ’總體準確率‘
第三行 不同詞的attention值,從大到小排序
使用詞性+attention後結果
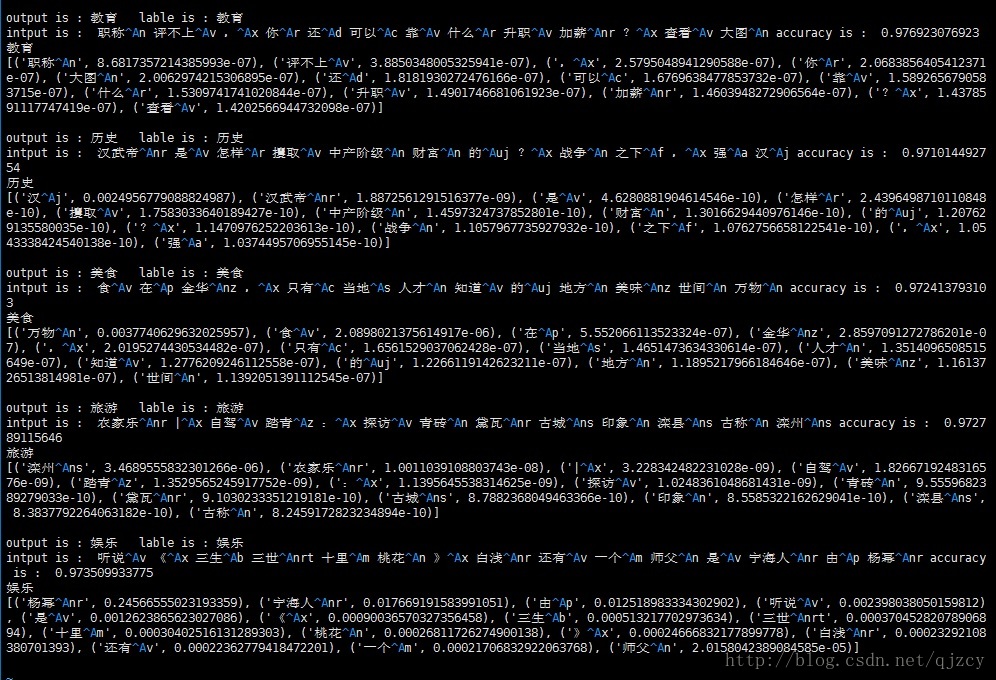
僅使用attention結果
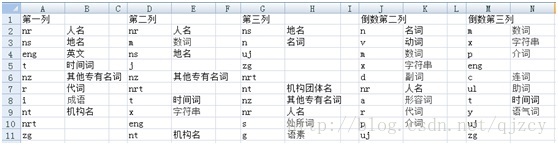
每列詞性的分佈減去詞性平均分佈得到排序前十,我們可以看到,前幾列更側重在專有名詞,實體詞方面。後幾列更側重在介詞,組詞,語氣詞方面。這和我們平時經驗相吻合
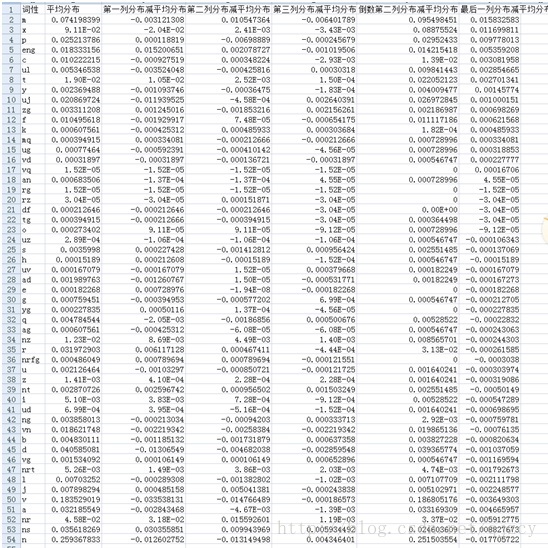
不同位置詞性的分佈:
計算方法:不同位置詞性的分佈減去詞性平均分佈得到得分
演算法原理:
Attention機制,論文中的公式如下。

我們對在公式2進行修改,eij=vaT*tanh(Wa*Si-1+Ua*hj+w3*pi),其中pi是為每個詞擴充套件開的詞性向量,w3為權重引數,這樣我們就很好的把詞性和詞的attention機制結合起來。
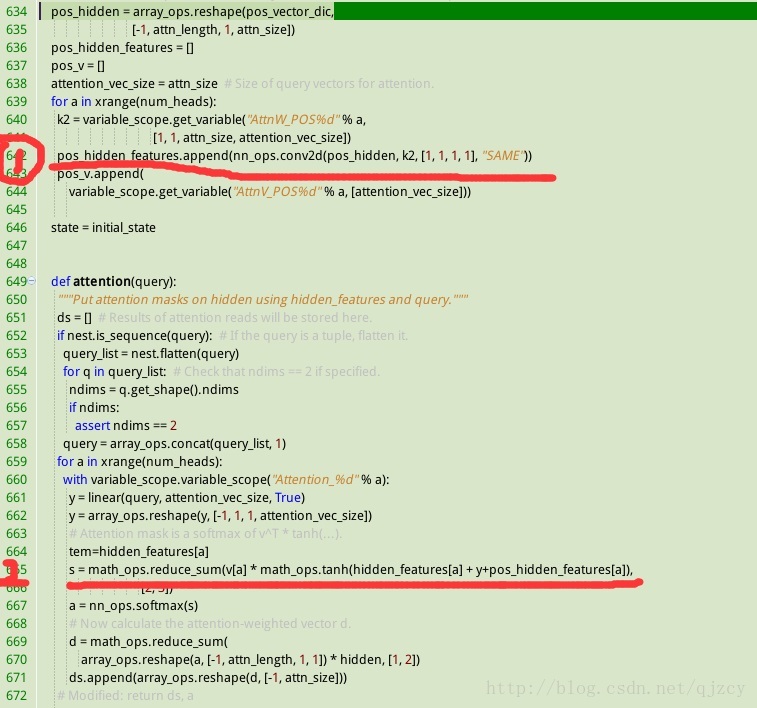
程式碼實現:
如下圖所示, 紅線1位置實現w3*pi, 紅線2位置實現eij=vaT*tanh(Wa*Si-1+Ua*hj+w3*pi)
詞性attention擴充套件的不同方式延展思考:
如上所示我們可以把詞性並列的擴充套件,然後把各權重值進行疊加。其實我們也可以把詞性和詞的擴充套件拼接在一起,完成對attention的詞性擴充套件。從美學上來說這種方式應該更加合理。但是這種方式會增加更多的w權重引數。比如同樣是batch*20個詞*擴充套件256維進行詞性擴充套件。並行的擴充套件新增的w3維度也是batch*120*256。如果採用拼接的方式除了需要詞性w3維度batch*20*256 還需要額外把dt的w2維度擴充套件batch*1*256