
Spark SQL dataframe 構造任意形式的json 的一種策略
最近做專案遇到一個問題, 後端使用Spark SQL 計算出的結果儲存在dataframe裡,就像下圖這種:
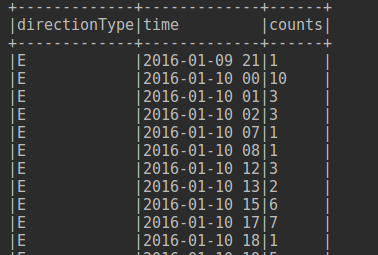
我們想把它轉成json ,傳給前端用來畫圖.這裡用的是play 的json 庫. 也就是我需要構造一個函式將dataframe轉換成json,返回值為JsObject.
首先宣告一點,這裡需要的JSON 是多層的,數組裡有物件,物件裡還有陣列,拿我們的問題來說,結構是這樣的:
{"data": [
{"directionType": "E", "values": [
{"time": "2016-01-09 21", "count ": 1},
{"time": "2016-01-09 21", "count ": 1}
]
{"directionType": "N", "values": [
{"time": "2016-01-09 21", "count ": 1},
{"time": "2016-01-09 21", "count ": 1}
] ,
"range": ["E","N","W","S"]}
一般來說,我在各大網站上搜到的都是dataframe直接轉json.就像下面這個:
df.withColumn("values",to_json(struct($"time",$"counts")))
結果就是 {"time": "2016-01-09 21", "count ": 1} 這樣的json 構造成功了.
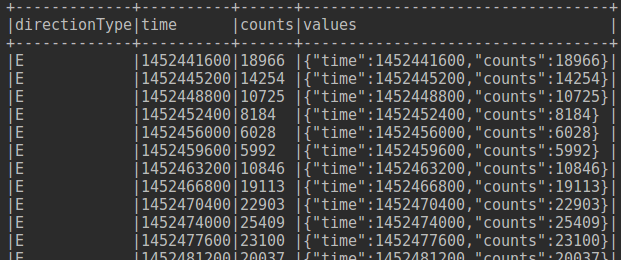
然後這個時候 對這一列執行collect() 操作,就成了這樣:
[ {"time": "2016-01-09 21", "count ": 1} , {"time": "2016-01-09 22", "count ": 2} ,{"time": "2016-01-09 23", "count ": 10} ]
看起來很棒是不是, 再執行如下指令
df.withColumn("data",to_json(struct($"directionType",$"values")))
眼看著就要成功了.但是由於轉義字元的原因,你save 的 json檔案裡會出現很多很多反斜槓\\\\\\\\\\,就像下面這樣.

就算你把他去掉了,也會發現json的格式出了大問題. 所以呢,顯然在我這裡這個方法行不通,更何況我還要生成一個JsObject 給前端.
怎麼搞呢??????
求人不如求自己, 答案就是自己構造,一層一層的來
以上面案例為例,
我們先構造第一層,基層,用tojson這裡不會有問題.
val df1 =df.withColumn("values",to_json(struct($"time",$"counts")))
然後collect起來,結果如下:
val df2 =df1.groupBy(col("directionType")).agg(collect_list("values") as "values")
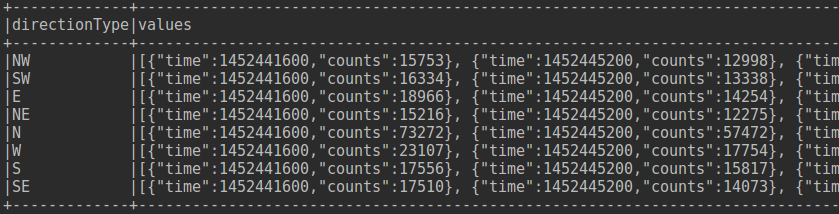
如上所述,接下來不能在用tojson了,只能用一次! 巢狀著用就會GG.
所以呢,我們就把這些Json物件遍歷,然後存起來:
val array1 = df2.collect() // 把df2,也就是上邊那張圖轉成一個數組,陣列的每一個元素就對應dataframe的一行我們遍歷這個新獲得的陣列,並使用 play的json 庫構造物件play.api.libs.json
for (i <- 0 until array1.length)
val result1 = Json.obj( "directionType" -> array1(i).get(0).asInstanceOf[String] , // 這裡存的就是directionType "values" -> temp_array1 //這裡存的就是values每一行的那一大長串啦,那一大長串是一個JsArray,裡邊裝的是JsObject )
然後因為"values"列的每一行本身就是一個數組,我們再遍歷"values" 每一行的那個陣列的所有元素,把他們存成JsObject就可以了.
也就是兩層for迴圈就搞定了.
構造完畢之後,我們繼續遍歷 directionType列的每一行,搞出行數個JsObject物件出來,再存成一個數組,這個陣列再作為屬性值給一個key值,就OK啦.
So,總體思路就是, 深入遍歷到所需jsonObject的最底層, 把最底層組裝好,對應好key,存成一個value,在往上一層一層組裝好. 有點像遞迴的思路.