
[轉載] goroutine背後的系統知識
Go語言從誕生到普及已經三年了,先行者大都是Web開發的背景,也有了一些普及型的書籍,可系統開發背景的人在學習這些書籍的時候,總有語焉不詳的感覺,網上也有若干流傳甚廣的文章,可其中或多或少總有些與事實不符的技術描述。希望這篇文章能為比較缺少系統程式設計背景的Web開發人員介紹一下goroutine背後的系統知識。
1. 作業系統與執行庫
2. 併發與並行 (Concurrency and Parallelism)
3. 執行緒的排程
4. 併發程式設計框架
5. goroutine
1. 作業系統與執行庫
對於普通的電腦使用者來說,能理解應用程式是執行在作業系統之上就足夠了,可對於開發者,我們還需要了解我們寫的程式是如何在作業系統之上執行起來的,作業系統如何為應用程式提供服務,這樣我們才能分清楚哪些服務是作業系統提供的,而哪些服務是由我們所使用的語言的執行庫提供的。
除了記憶體管理、檔案管理、程序管理、外設管理等等內部模組以外,作業系統還提供了許多外部介面供應用程式使用,這些介面就是所謂的“系統呼叫”。從DOS時代開始,系統呼叫就是通過軟中斷的形式來提供,也就是著名的INT 21,程式把需要呼叫的功能編號放入AH暫存器,把引數放入其他指定的暫存器,然後呼叫INT 21,中斷返回後,程式從指定的暫存器(通常是AL)裡取得返回值。這樣的做法一直到奔騰2也就是P6出來之前都沒有變,譬如windows通過INT 2E提供系統呼叫,Linux則是INT 80,只不過後來的暫存器比以前大一些,而且可能再多一層跳轉表查詢。後來,Intel和AMD分別提供了效率更高的SYSENTER/SYSEXIT和SYSCALL/SYSRET
系統呼叫都提供什麼功能呢?用作業系統的名字加上對應的中斷編號到谷歌上一查就可以得到完整的列表 (Windows, Linux),這個列表就是作業系統和應用程式之間溝通的協議,如果需要超出此協議的功能,我們就只能在自己的程式碼裡去實現,譬如,對於記憶體管理,作業系統只提供程序級別的記憶體段的管理,譬如Windows的virtualmemory系列,或是Linux的brk,作業系統不會去在乎應用程式如何為新建物件分配記憶體,或是如何做垃圾回收,這些都需要應用程式自己去實現。如果超出此協議的功能無法自己實現,那我們就說該作業系統不支援該功能,舉個例子,Linux在2.6之前是不支援多執行緒的,無論如何在程式裡模擬,我們都無法做出多個可以同時執行的並符合POSIX 1003.1c語義標準的排程單元。
可是,我們寫程式並不需要去呼叫中斷或是SYSCALL指令,這是因為作業系統提供了一層封裝,在Windows上,它是NTDLL.DLL,也就是常說的Native API,我們不但不需要去直接呼叫INT 2E或SYSCALL,準確的說,我們不能直接去呼叫INT 2E或SYSCALL,因為Windows並沒有公開其呼叫規範,直接使用INT 2E或SYSCALL無法保證未來的相容性。在Linux上則沒有這個問題,系統呼叫的列表都是公開的,而且Linus非常看重相容性,不會去做任何更改,glibc裡甚至專門提供了syscall(2)來方便使用者直接用編號呼叫,不過,為了解決glibc和核心之間不同版本相容性帶來的麻煩,以及為了提高某些呼叫的效率(譬如__NR_ gettimeofday),Linux上還是對部分系統呼叫做了一層封裝,就是VDSO (早期叫linux-gate.so)。
可是,我們寫程式也很少直接呼叫NTDLL或者VDSO,而是通過更上一層的封裝,這一層處理了引數準備和返回值格式轉換、以及出錯處理和錯誤程式碼轉換,這就是我們所使用語言的執行庫,對於C語言,Linux上是glibc,Windows上是kernel32(或呼叫msvcrt),對於其他語言,譬如Java,則是JRE,這些“其他語言”的執行庫通常最終還是呼叫glibc或kernel32。
“執行庫”這個詞其實不止包括用於和編譯後的目標執行程式進行連結的庫檔案,也包括了指令碼語言或位元組碼解釋型語言的執行環境,譬如Python,C#的CLR,Java的JRE。
對系統呼叫的封裝只是執行庫的很小一部分功能,執行庫通常還提供了諸如字串處理、數學計算、常用資料結構容器等等不需要作業系統支援的功能,同時,執行庫也會對作業系統支援的功能提供更易用更高階的封裝,譬如帶快取和格式的IO、執行緒池。
所以,在我們說“某某語言新增了某某功能”的時候,通常是這麼幾種可能:
1. 支援新的語義或語法,從而便於我們描述和解決問題。譬如Java的泛型、Annotation、lambda表示式。
2. 提供了新的工具或類庫,減少了我們開發的程式碼量。譬如Python 2.7的argparse
3. 對系統呼叫有了更良好更全面的封裝,使我們可以做到以前在這個語言環境裡做不到或很難做到的事情。譬如Java NIO
但任何一門語言,包括其執行庫和執行環境,都不可能創造出作業系統不支援的功能,Go語言也是這樣,不管它的特性描述看起來多麼炫麗,那必然都是其他語言也可以做到的,只不過Go提供了更方便更清晰的語義和支援,提高了開發的效率。
2. 併發與並行 (Concurrency and Parallelism)
併發是指程式的邏輯結構。非併發的程式就是一根竹竿捅到底,只有一個邏輯控制流,也就是順序執行的(Sequential)程式,在任何時刻,程式只會處在這個邏輯控制流的某個位置。而如果某個程式有多個獨立的邏輯控制流,也就是可以同時處理(deal)多件事情,我們就說這個程式是併發的。這裡的“同時”,並不一定要是真正在時鐘的某一時刻(那是執行狀態而不是邏輯結構),而是指:如果把這些邏輯控制流畫成時序流程圖,它們在時間線上是可以重疊的。
並行是指程式的執行狀態。如果一個程式在某一時刻被多個CPU流水線同時進行處理,那麼我們就說這個程式是以並行的形式在執行。(嚴格意義上講,我們不能說某程式是“並行”的,因為“並行”不是描述程式本身,而是描述程式的執行狀態,但這篇小文裡就不那麼咬文嚼字,以下說到“並行”的時候,就是指代“以並行的形式執行”)顯然,並行一定是需要硬體支援的。
而且不難理解:
1. 併發是並行的必要條件,如果一個程式本身就不是併發的,也就是隻有一個邏輯控制流,那麼我們不可能讓其被並行處理。
2. 併發不是並行的充分條件,一個併發的程式,如果只被一個CPU流水線進行處理(通過分時),那麼它就不是並行的。
3. 併發只是更符合現實問題本質的表達方式,併發的最初目的是簡化程式碼邏輯,而不是使程式執行的更快;
這幾段略微抽象,我們可以用一個最簡單的例子來把這些概念例項化:用C語言寫一個最簡單的HelloWorld,它就是非併發的,如果我們建立多個執行緒,每個執行緒裡列印一個HelloWorld,那麼這個程式就是併發的,如果這個程式執行在老式的單核CPU上,那麼這個併發程式還不是並行的,如果我們用多核多CPU且支援多工的作業系統來執行它,那麼這個併發程式就是並行的。
還有一個略微複雜的例子,更能說明併發不一定可以並行,而且併發不是為了效率,就是Go語言例子裡計算素數的sieve.go。我們從小到大針對每一個因子啟動一個程式碼片段,如果當前驗證的數能被當前因子除盡,則該數不是素數,如果不能,則把該數傳送給下一個因子的程式碼片段,直到最後一個因子也無法除盡,則該數為素數,我們再啟動一個它的程式碼片段,用於驗證更大的數字。這是符合我們計算素數的邏輯的,而且每個因子的程式碼處理片段都是相同的,所以程式非常的簡潔,但它無法被並行,因為每個片段都依賴於前一個片段的處理結果和輸出。
併發可以通過以下方式做到:
1. 顯式地定義並觸發多個程式碼片段,也就是邏輯控制流,由應用程式或作業系統對它們進行排程。它們可以是獨立無關的,也可以是相互依賴需要互動的,譬如上面提到的素數計算,其實它也是個經典的生產者和消費者的問題:兩個邏輯控制流A和B,A產生輸出,當有了輸出後,B取得A的輸出進行處理。執行緒只是實現併發的其中一個手段,除此之外,執行庫或是應用程式本身也有多種手段來實現併發,這是下節的主要內容。
2. 隱式地放置多個程式碼片段,在系統事件發生時觸發執行相應的程式碼片段,也就是事件驅動的方式,譬如某個埠或管道接收到了資料(多路IO的情況下),再譬如程序接收到了某個訊號(signal)。
並行可以在四個層面上做到:
1. 多臺機器。自然我們就有了多個CPU流水線,譬如Hadoop叢集裡的MapReduce任務。
2. 多CPU。不管是真的多顆CPU還是多核還是超執行緒,總之我們有了多個CPU流水線。
3. 單CPU核裡的ILP(Instruction-level parallelism),指令級並行。通過複雜的製造工藝和對指令的解析以及分支預測和亂序執行,現在的CPU可以在單個時鐘週期內執行多條指令,從而,即使是非併發的程式,也可能是以並行的形式執行。
4. 單指令多資料(Single instruction, multiple data. SIMD),為了多媒體資料的處理,現在的CPU的指令集支援單條指令對多條資料進行操作。
其中,1牽涉到分散式處理,包括資料的分佈和任務的同步等等,而且是基於網路的。3和4通常是編譯器和CPU的開發人員需要考慮的。這裡我們說的並行主要針對第2種:單臺機器內的多核CPU並行。
在CMU那本著名的《Computer Systems: A Programmer’s Perspective》裡的這張圖也非常直觀清晰: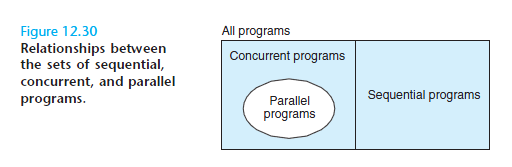
3. 執行緒的排程
上一節主要說的是併發和並行的概念,而執行緒是最直觀的併發的實現,這一節我們主要說作業系統如何讓多個執行緒併發的執行,當然在多CPU的時候,也就是並行的執行。我們不討論程序,程序的意義是“隔離的執行環境”,而不是“單獨的執行序列”。
我們首先需要理解IA-32 CPU的指令控制方式,這樣才能理解如何在多個指令序列(也就是邏輯控制流)之間進行切換。CPU通過CS:EIP暫存器的值確定下一條指令的位置,但是CPU並不允許直接使用MOV指令來更改EIP的值,必須通過JMP系列指令、CALL/RET指令、或INT中斷指令來實現程式碼的跳轉;在指令序列間切換的時候,除了更改EIP之外,我們還要保證程式碼可能會使用到的各個暫存器的值,尤其是棧指標SS:ESP,以及EFLAGS標誌位等,都能夠恢復到目標指令序列上次執行到這個位置時候的狀態。
執行緒是作業系統對外提供的服務,應用程式可以通過系統呼叫讓作業系統啟動執行緒,並負責隨後的執行緒排程和切換。我們先考慮單顆單核CPU,作業系統核心與應用程式其實是也是在共享同一個CPU,當EIP在應用程式程式碼段的時候,核心並沒有控制權,核心並不是一個程序或執行緒,核心只是以真實模式執行的,程式碼段許可權為RING 0的記憶體中的程式,只有當產生中斷或是應用程式呼叫系統呼叫的時候,控制權才轉移到核心,在核心裡,所有程式碼都在同一個地址空間,為了給不同的執行緒提供服務,核心會為每一個執行緒建立一個核心堆疊,這是執行緒切換的關鍵。通常,核心會在時鐘中斷裡或系統呼叫返回前(考慮到效能,通常是在不頻繁發生的系統呼叫返回前),對整個系統的執行緒進行排程,計算當前執行緒的剩餘時間片,如果需要切換,就在“可執行”的執行緒佇列裡計算優先順序,選出目標執行緒後,則儲存當前執行緒的執行環境,並恢復目標執行緒的執行環境,其中最重要的,就是切換堆疊指標ESP,然後再把EIP指向目標執行緒上次被移出CPU時的指令。Linux核心在實現執行緒切換時,耍了個花槍,它並不是直接JMP,而是先把ESP切換為目標執行緒的核心棧,把目標執行緒的程式碼地址壓棧,然後JMP到__switch_to(),相當於偽造了一個CALL __switch_to()指令,然後,在__switch_to()的最後使用RET指令返回,這樣就把棧裡的目標執行緒的程式碼地址放入了EIP,接下來CPU就開始執行目標執行緒的程式碼了,其實也就是上次停在switch_to這個巨集展開的地方。
這裡需要補充幾點:(1) 雖然IA-32提供了TSS (Task State Segment),試圖簡化作業系統進行執行緒排程的流程,但由於其效率低下,而且並不是通用標準,不利於移植,所以主流作業系統都沒有去利用TSS。更嚴格的說,其實還是用了TSS,因為只有通過TSS才能把堆疊切換到核心堆疊指標SS0:ESP0,但除此之外的TSS的功能就完全沒有被使用了。(2) 執行緒從使用者態進入核心的時候,相關的暫存器以及使用者態程式碼段的EIP已經儲存了一次,所以,在上面所說的核心態執行緒切換時,需要儲存和恢復的內容並不多。(3) 以上描述的都是搶佔式(preemptively)的排程方式,核心以及其中的硬體驅動也會在等待外部資源可用的時候主動呼叫schedule(),使用者態的程式碼也可以通過sched_yield()系統呼叫主動發起排程,讓出CPU。
現在我們一臺普通的PC或服務裡通常都有多顆CPU (physical package),每顆CPU又有多個核 (processor core),每個核又可以支援超執行緒 (two logical processors for each core),也就是邏輯處理器。每個邏輯處理器都有自己的一套完整的暫存器,其中包括了CS:EIP和SS:ESP,從而,以作業系統和應用的角度來看,每個邏輯處理器都是一個單獨的流水線。在多處理器的情況下,執行緒切換的原理和流程其實和單處理器時是基本一致的,核心程式碼只有一份,當某個CPU上發生時鐘中斷或是系統呼叫時,該CPU的CS:EIP和控制權又回到了核心,核心根據排程策略的結果進行執行緒切換。但在這個時候,如果我們的程式用執行緒實現了併發,那麼作業系統可以使我們的程式在多個CPU上實現並行。
這裡也需要補充兩點:(1) 多核的場景裡,各個核之間並不是完全對等的,譬如在同一個核上的兩個超執行緒是共享L1/L2快取的;在有NUMA支援的場景裡,每個核訪問記憶體不同區域的延遲是不一樣的;所以,多核場景裡的執行緒排程又引入了“排程域”(scheduling domains)的概念,但這不影響我們理解執行緒切換機制。(2) 多核的場景下,中斷髮給哪個CPU?軟中斷(包括除以0,缺頁異常,INT指令)自然是在觸發該中斷的CPU上產生,而硬中斷則又分兩種情況,一種是每個CPU自己產生的中斷,譬如時鐘,這是每個CPU處理自己的,還有一種是外部中斷,譬如IO,可以通過APIC來指定其送給哪個CPU;因為排程程式只能控制當前的CPU,所以,如果IO中斷沒有進行均勻的分配的話,那麼和IO相關的執行緒就只能在某些CPU上執行,導致CPU負載不均,進而影響整個系統的效率。
4. 併發程式設計框架
以上大概介紹了一個用多執行緒來實現併發的程式是如何被作業系統排程以及並行執行(在有多個邏輯處理器時),同時大家也可以看到,程式碼片段或者說邏輯控制流的排程和切換其實並不神祕,理論上,我們也可以不依賴作業系統和其提供的執行緒,在自己程式的程式碼段裡定義多個片段,然後在我們自己程式裡對其進行排程和切換。
為了描述方便,我們接下來把“程式碼片段”稱為“任務”。
和核心的實現類似,只是我們不需要考慮中斷和系統呼叫,那麼,我們的程式本質上就是一個迴圈,這個迴圈本身就是排程程式schedule(),我們需要維護一個任務的列表,根據我們定義的策略,先進先出或是有優先順序等等,每次從列表裡挑選出一個任務,然後恢復各個暫存器的值,並且JMP到該任務上次被暫停的地方,所有這些需要儲存的資訊都可以作為該任務的屬性,存放在任務列表裡。
看起來很簡單啊,可是我們還需要解決幾個問題:
(1) 我們執行在使用者態,是沒有中斷或系統呼叫這樣的機制來打斷程式碼執行的,那麼,一旦我們的schedule()程式碼把控制權交給了任務的程式碼,我們下次的排程在什麼時候發生?答案是,不會發生,只有靠任務主動呼叫schedule(),我們才有機會進行排程,所以,這裡的任務不能像執行緒一樣依賴核心排程從而毫無顧忌的執行,我們的任務裡一定要顯式的呼叫schedule(),這就是所謂的協作式(cooperative)排程。(雖然我們可以通過註冊訊號處理函式來模擬核心裡的時鐘中斷並取得控制權,可問題在於,訊號處理函式是由核心呼叫的,在其結束的時候,核心重新獲得控制權,隨後返回使用者態並繼續沿著訊號發生時被中斷的程式碼路徑執行,從而我們無法在訊號處理函式內進行任務切換)
(2) 堆疊。和核心排程執行緒的原理一樣,我們也需要為每個任務單獨分配堆疊,並且把其堆疊資訊儲存在任務屬性裡,在任務切換時也儲存或恢復當前的SS:ESP。任務堆疊的空間可以是在當前執行緒的堆疊上分配,也可以是在堆上分配,但通常是在堆上分配比較好:幾乎沒有大小或任務總數的限制、堆疊大小可以動態擴充套件(gcc有split stack,但太複雜了)、便於把任務切換到其他執行緒。
到這裡,我們大概知道了如何構造一個併發的程式設計框架,可如何讓任務可以並行的在多個邏輯處理器上執行呢?只有核心才有排程CPU的許可權,所以,我們還是必須通過系統呼叫建立執行緒,才可以實現並行。在多執行緒處理多工的時候,我們還需要考慮幾個問題:
(1) 如果某個任務發起了一個系統呼叫,譬如長時間等待IO,那當前執行緒就被核心放入了等待排程的佇列,豈不是讓其他任務都沒有機會執行?
在單執行緒的情況下,我們只有一個解決辦法,就是使用非阻塞的IO系統呼叫,並讓出CPU,然後在schedule()裡統一進行輪詢,有資料時切換回該fd對應的任務;效率略低的做法是不進行統一輪詢,讓各個任務在輪到自己執行時再次用非阻塞方式進行IO,直到有資料可用。
如果我們採用多執行緒來構造我們整個的程式,那麼我們可以封裝系統呼叫的介面,當某個任務進入系統呼叫時,我們就把當前執行緒留給它(暫時)獨享,並開啟新的執行緒來處理其他任務。
(2) 任務同步。譬如我們上節提到的生產者和消費者的例子,如何讓消費者在資料還沒有被生產出來的時候進入等待,並且在資料可用時觸發消費者繼續執行呢?
在單執行緒的情況下,我們可以定義一個結構,其中有變數用於存放互動資料本身,以及資料的當前可用狀態,以及負責讀寫此資料的兩個任務的編號。然後我們的併發程式設計框架再提供read和write方法供任務呼叫,在read方法裡,我們迴圈檢查資料是否可用,如果資料還不可用,我們就呼叫schedule()讓出CPU進入等待;在write方法裡,我們往結構裡寫入資料,更改資料可用狀態,然後返回;在schedule()裡,我們檢查資料可用狀態,如果可用,則啟用需要讀取此資料的任務,該任務繼續迴圈檢測資料是否可用,發現可用,讀取,更改狀態為不可用,返回。程式碼的簡單邏輯如下:
struct chan {
bool ready,
int data
};
int read (struct chan *c) {
while (1) {
if (c->ready) {
c->ready = false;
return c->data;
} else {
schedule();
}
}
}
void write (struct chan *c, int i) {
while (1) {
if (c->ready) {
schedule();
} else {
c->data = i;
c->ready = true;
schedule(); // optional
return;
}
}
}
很顯然,如果是多執行緒的話,我們需要通過執行緒庫或系統呼叫提供的同步機制來保護對這個結構體內資料的訪問。
以上就是最簡化的一個併發框架的設計考慮,在我們實際開發工作中遇到的併發框架可能由於語言和執行庫的不同而有所不同,在功能和易用性上也可能各有取捨,但底層的原理都是殊途同歸。
譬如,glic裡的getcontext/setcontext/swapcontext系列庫函式可以方便的用來儲存和恢復任務執行狀態;Windows提供了Fiber系列的SDK API;這二者都不是系統呼叫,getcontext和setcontext的man page雖然是在section 2,但那只是SVR4時的歷史遺留問題,其實現程式碼是在glibc而不是kernel;CreateFiber是在kernel32裡提供的,NTDLL裡並沒有對應的NtCreateFiber。
在其他語言裡,我們所謂的“任務”更多時候被稱為“協程”,也就是Coroutine。譬如C++裡最常用的是Boost.Coroutine;Java因為有一層位元組碼解釋,比較麻煩,但也有支援協程的JVM補丁,或是動態修改位元組碼以支援協程的專案;PHP和Python的generator和yield其實已經是協程的支援,在此之上可以封裝出更通用的協程介面和排程;另外還有原生支援協程的Erlang等,筆者不懂,就不說了,具體可參見Wikipedia的頁面:http://en.wikipedia.org/wiki/Coroutine
由於儲存和恢復任務執行狀態需要訪問CPU暫存器,所以相關的執行庫也都會列出所支援的CPU列表。
從作業系統層面提供協程以及其並行排程的,好像只有OS X和iOS的Grand Central Dispatch,其大部分功能也是在執行庫裡實現的。
5. goroutine
Go語言通過goroutine提供了目前為止所有(我所瞭解的)語言裡對於併發程式設計的最清晰最直接的支援,Go語言的文件裡對其特性也描述的非常全面甚至超過了,在這裡,基於我們上面的系統知識介紹,列舉一下goroutine的特性,算是小結:
(1) goroutine是Go語言執行庫的功能,不是作業系統提供的功能,goroutine不是用執行緒實現的。具體可參見Go語言原始碼裡的pkg/runtime/proc.c
(2) goroutine就是一段程式碼,一個函式入口,以及在堆上為其分配的一個堆疊。所以它非常廉價,我們可以很輕鬆的建立上萬個goroutine,但它們並不是被作業系統所排程執行
(3) 除了被系統呼叫阻塞的執行緒外,Go執行庫最多會啟動$GOMAXPROCS個執行緒來執行goroutine
(4) goroutine是協作式排程的,如果goroutine會執行很長時間,而且不是通過等待讀取或寫入channel的資料來同步的話,就需要主動呼叫Gosched()來讓出CPU
(5) 和所有其他併發框架裡的協程一樣,goroutine裡所謂“無鎖”的優點只在單執行緒下有效,如果$GOMAXPROCS > 1並且協程間需要通訊,Go執行庫會負責加鎖保護資料,這也是為什麼sieve.go這樣的例子在多CPU多執行緒時反而更慢的原因
(6) Web等服務端程式要處理的請求從本質上來講是並行處理的問題,每個請求基本獨立,互不依賴,幾乎沒有資料互動,這不是一個併發程式設計的模型,而併發程式設計框架只是解決了其語義表述的複雜性,並不是從根本上提高處理的效率,也許是併發連線和併發程式設計的英文都是concurrent吧,很容易產生“併發程式設計框架和coroutine可以高效處理大量併發連線”的誤解。
(7) Go語言執行庫封裝了非同步IO,所以可以寫出貌似併發數很多的服務端,可即使我們通過調整$GOMAXPROCS來充分利用多核CPU並行處理,其效率也不如我們利用IO事件驅動設計的、按照事務型別劃分好合適比例的執行緒池。在響應時間上,協作式排程是硬傷。
(8) goroutine最大的價值是其實現了併發協程和實際並行執行的執行緒的對映以及動態擴充套件,隨著其執行庫的不斷髮展和完善,其效能一定會越來越好,尤其是在CPU核數越來越多的未來,終有一天我們會為了程式碼的簡潔和可維護性而放棄那一點點效能的差別。