
Spark Streaming 實戰案例(三) DStream Window操作
本節主要內容
- Window Operation
- 入門案例
1. Window Operation
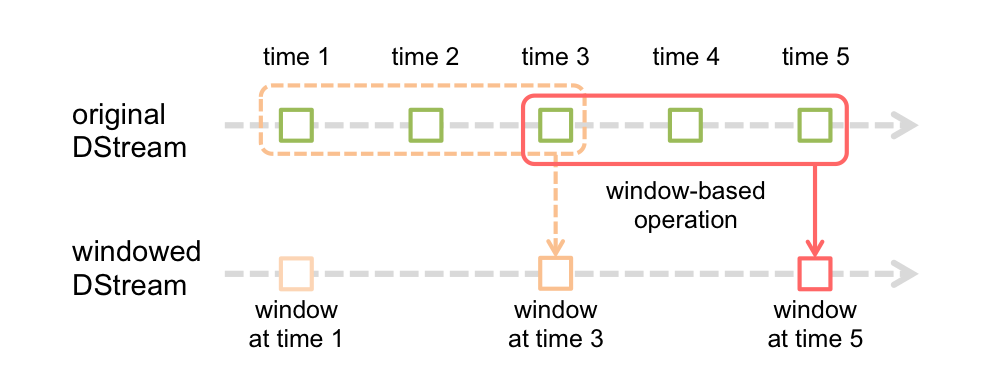
Spark Streaming提供視窗操作(Window Operation),如下圖所示:
上圖中,紅色實線表示視窗當前的滑動位置,虛線表示前一次視窗位置,視窗每滑動一次,落在該視窗中的RDD被一起同時處理,生成一個視窗DStream(windowed DStream),視窗操作需要設定兩個引數:
(1)視窗長度(window length),即視窗的持續時間,上圖中的視窗長度為3
(2)滑動間隔(sliding interval),視窗操作執行的時間間隔,上圖中的滑動間隔為2
這兩個引數必須是原始DStream 批處理間隔(batch interval)的整數倍(上圖中的原始DStream的batch interval為1)
2. 入門案例
- WindowWordCount——reduceByKeyAndWindow方法使用
import org.apache.spark.{SparkContext, SparkConf}
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming._
import org.apache.spark.streaming.StreamingContext._
object WindowWordCount {
def main(args: Array[String]) {
//傳入的引數為localhost 9999 通過下列程式碼啟動netcat server
root@sparkmaster:~# nc -lk 9999
- 1
再執行WindowWordCount
輸入下列語句
root@sparkmaster:~# nc -lk 9999
Spark is a fast and general cluster computing system for Big Data. It provides
- 1
觀察執行情況:
-------------------------------------------
Time: 1448778805000 ms(10秒,第一個滑動視窗時間)
-------------------------------------------
(provides,1)
(is,1)
(general,1)
(Big,1)
(fast,1)
(cluster,1)
(Data.,1)
(computing,1)
(Spark,1)
(a,1)
...
-------------------------------------------
Time: 1448778815000 ms(10秒後,第二個滑動視窗時間)
-------------------------------------------
(provides,1)
(is,1)
(general,1)
(Big,1)
(fast,1)
(cluster,1)
(Data.,1)
(computing,1)
(Spark,1)
(a,1)
...
-------------------------------------------
Time: 1448778825000 ms(10秒後,第三個滑動視窗時間)
-------------------------------------------
(provides,1)
(is,1)
(general,1)
(Big,1)
(fast,1)
(cluster,1)
(Data.,1)
(computing,1)
(Spark,1)
(a,1)
...
-------------------------------------------
Time: 1448778835000 ms(再經10秒後,超出window length視窗長度,不在計數範圍內)
-------------------------------------------
-------------------------------------------
Time: 1448778845000 ms
-------------------------------------------
同樣的語句輸入兩次
[email protected]:~# nc -lk 9999
Spark is a fast and general cluster computing system for Big Data. It provides
Spark is a fast and general cluster computing system for Big Data. It provides
Spark is a fast and general cluster computing system for Big Data. It provides
觀察執行結果如下:
Time: 1448779205000 ms
-------------------------------------------
(provides,2)
(is,2)
(general,2)
(Big,2)
(fast,2)
(cluster,2)
(Data.,2)
(computing,2)
(Spark,2)
(a,2)
...
再輸入一次
[email protected]:~# nc -lk 9999
Spark is a fast and general cluster computing system for Big Data. It provides
Spark is a fast and general cluster computing system for Big Data. It provides
Spark is a fast and general cluster computing system for Big Data. It provides
Spark is a fast and general cluster computing system for Big Data. It provides計算結果如下:
-------------------------------------------
Time: 1448779215000 ms
-------------------------------------------
(provides,3)
(is,3)
(general,3)
(Big,3)
(fast,3)
(cluster,3)
(Data.,3)
(computing,3)
(Spark,3)
(a,3)
...
再輸入一次
[email protected]:~# nc -lk 9999
Spark is a fast and general cluster computing system for Big Data. It provides
Spark is a fast and general cluster computing system for Big Data. It provides
Spark is a fast and general cluster computing system for Big Data. It provides
Spark is a fast and general cluster computing system for Big Data. It provides
Spark is a fast and general cluster computing system for Big Data. It provides計算結果如下:
-------------------------------------------
Time: 1448779225000 ms
-------------------------------------------
(provides,4)
(is,4)
(general,4)
(Big,4)
(fast,4)
(cluster,4)
(Data.,4)
(computing,4)
(Spark,4)
(a,4)
...
-------------------------------------------
Time: 1448779235000 ms
-------------------------------------------
(provides,2)
(is,2)
(general,2)
(Big,2)
(fast,2)
(cluster,2)
(Data.,2)
(computing,2)
(Spark,2)
(a,2)
...
-------------------------------------------
Time: 1448779245000 ms
-------------------------------------------
(provides,1)
(is,1)
(general,1)
(Big,1)
(fast,1)
(cluster,1)
(Data.,1)
(computing,1)
(Spark,1)
(a,1)
...
-------------------------------------------
Time: 1448779255000 ms
-------------------------------------------
-------------------------------------------
Time: 1448779265000 ms
-------------------------------------------2 WindowWordCount——countByWindow方法使用
import org.apache.spark.{SparkContext, SparkConf}
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming._
import org.apache.spark.streaming.StreamingContext._
object WindowWordCount {
def main(args: Array[String]) {
if (args.length != 4) {
System.err.println("Usage: WindowWorldCount <hostname> <port> <windowDuration> <slideDuration>")
System.exit(1)
}
StreamingExamples.setStreamingLogLevels()
val conf = new SparkConf().setAppName("WindowWordCount").setMaster("local[2]")
val sc = new SparkContext(conf)
// 建立StreamingContext
val ssc = new StreamingContext(sc, Seconds(5))
// 定義checkpoint目錄為當前目錄
ssc.checkpoint(".")
val lines = ssc.socketTextStream(args(0), args(1).toInt, StorageLevel.MEMORY_ONLY_SER)
val words = lines.flatMap(_.split(" "))
//countByWindowcountByWindow方法計算基於滑動視窗的DStream中的元素的數量。
val countByWindow=words.countByWindow(Seconds(args(2).toInt), Seconds(args(3).toInt))
countByWindow.print()
ssc.start()
ssc.awaitTermination()
}
}啟動
root@sparkmaster:~# nc -lk 9999
然後執行WindowWordCount
輸入
root@sparkmaster:~# nc -lk 9999
Spark is a fast and general cluster computing system for Big Data察看執行結果:
-------------------------------------------
Time: 1448780625000 ms
-------------------------------------------
0
-------------------------------------------
Time: 1448780635000 ms
-------------------------------------------
12
-------------------------------------------
Time: 1448780645000 ms
-------------------------------------------
12
-------------------------------------------
Time: 1448780655000 ms
-------------------------------------------
12
-------------------------------------------
Time: 1448780665000 ms
-------------------------------------------
0
-------------------------------------------
Time: 1448780675000 ms
-------------------------------------------
0
3 WindowWordCount——reduceByWindow方法使用
//reduceByWindow方法基於滑動視窗對源DStream中的元素進行聚合操作,返回包含單元素的一個新的DStream。
val reduceByWindow=words.map(x=>1).reduceByWindow(_+_,_-_Seconds(args(2).toInt), Seconds(args(3).toInt))上面的例子其實是countByWindow的實現,可以在countByWindow原始碼實現中得到驗證
def countByWindow(
windowDuration: Duration,
slideDuration: Duration): DStream[Long] = ssc.withScope {
this.map(_ => 1L).reduceByWindow(_ + _, _ - _, windowDuration, slideDuration)
}而reduceByWindow又是通過reduceByKeyAndWindow方法來實現的,具體程式碼如下
def reduceByWindow(
reduceFunc: (T, T) => T,
invReduceFunc: (T, T) => T,
windowDuration: Duration,
slideDuration: Duration
): DStream[T] = ssc.withScope {
this.map(x => (1, x))
.reduceByKeyAndWindow(reduceFunc, invReduceFunc, windowDuration, slideDuration, 1)
.map(_._2)
}與前面的例子中的reduceByKeyAndWindow方法不同的是這裡的reduceByKeyAndWindow方法多了一個invReduceFunc引數,方法完整原始碼如下:
/**
* Return a new DStream by applying incremental `reduceByKey` over a sliding window.
* The reduced value of over a new window is calculated using the old window's reduced value :
* 1. reduce the new values that entered the window (e.g., adding new counts)
*
* 2. "inverse reduce" the old values that left the window (e.g., subtracting old counts)
*
* This is more efficient than reduceByKeyAndWindow without "inverse reduce" function.
* However, it is applicable to only "invertible reduce functions".
* Hash partitioning is used to generate the RDDs with Spark's default number of partitions.
* @param reduceFunc associative reduce function
* @param invReduceFunc inverse reduce function
* @param windowDuration width of the window; must be a multiple of this DStream's
* batching interval
* @param slideDuration sliding interval of the window (i.e., the interval after which
* the new DStream will generate RDDs); must be a multiple of this
* DStream's batching interval
* @param filterFunc Optional function to filter expired key-value pairs;
* only pairs that satisfy the function are retained
*/
def reduceByKeyAndWindow(
reduceFunc: (V, V) => V,
invReduceFunc: (V, V) => V,
windowDuration: Duration,
slideDuration: Duration = self.slideDuration,
numPartitions: Int = ssc.sc.defaultParallelism,
filterFunc: ((K, V)) => Boolean = null
): DStream[(K, V)] = ssc.withScope {
reduceByKeyAndWindow(
reduceFunc, invReduceFunc, windowDuration,
slideDuration, defaultPartitioner(numPartitions), filterFunc
)
}具體來講,下面兩個方法得到的結果是一樣的,只是效率不同,後面的方法方式效率更高:
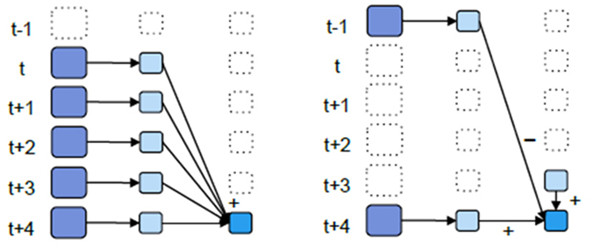
//以過去5秒鐘為一個輸入視窗,每1秒統計一下WordCount,本方法會將過去5秒鐘的每一秒鐘的WordCount都進行統計
//然後進行疊加,得出這個視窗中的單詞統計。 這種方式被稱為疊加方式,如下圖左邊所示
val wordCounts = words.map(x => (x, 1)).reduceByKeyAndWindow(_ + _, Seconds(5s),seconds(1))與
//計算t+4秒這個時刻過去5秒視窗的WordCount,可以將t+3時刻過去5秒的統計量加上[t+3,t+4]的統計量
//再減去[t-2,t-1]的統計量,這種方法可以複用中間三秒的統計量,提高統計的效率。 這種方式被稱為增量方式,如下圖的右邊所示
val wordCounts = words.map(x => (x, 1)).reduceByKeyAndWindow(_ + _, _ - _, Seconds(5s),seconds(1))- 1
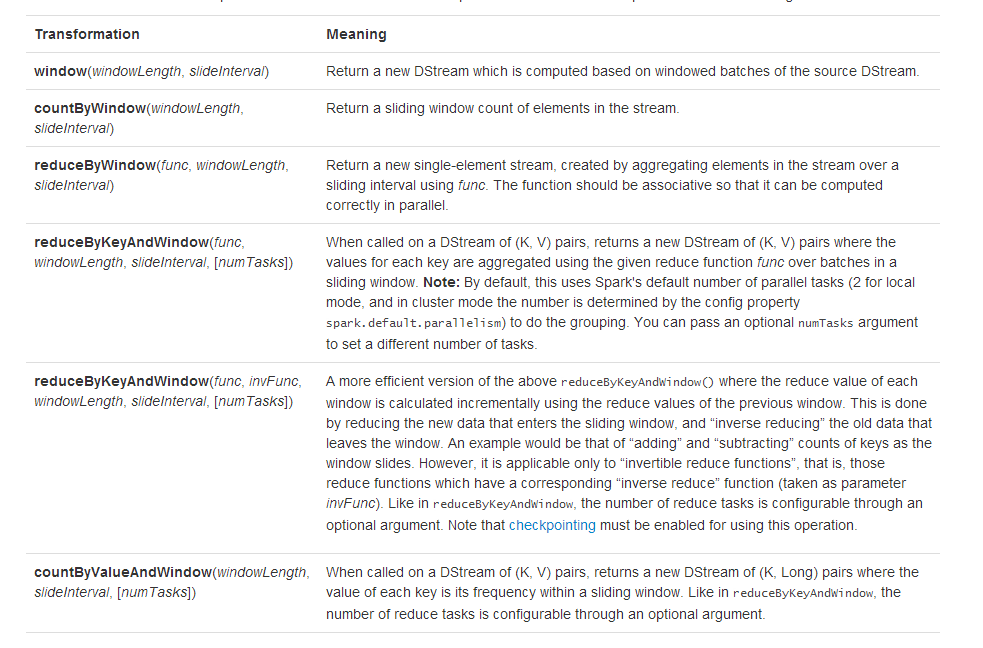
DStream支援的全部Window操作方法如下:
相關推薦
Spark Streaming 實戰案例(三) DStream Window操作
本節主要內容 Window Operation入門案例1. Window Operation Spark Streaming提供視窗操作(Window Operation),如下圖所示: 上圖中,紅色實線表示視窗當前的滑動位置,虛線表示前一次視窗位置,視窗每滑動一次,落在
Spark Streaming筆記整理(三):DS的transformation與output操作
job watermark number 這樣的 格式 current fix work eat DStream的各種transformation Transformation Meaning map(func) 對DStream中的各個元素進行func函數操作,然後
Spark Streaming程式設計指南(三)
DStreams轉換(Transformation) 和RDD類似,轉換中允許輸入DStream中的資料被修改。DStream支援很多Spark RDD上的轉換。常用的轉換如下。 轉換 含義 map(func) 將源DS
Java多線程編程模式實戰指南(三):Two-phase Termination模式
增加 row throws mgr 額外 finally join table 還需 停止線程是一個目標簡單而實現卻不那麽簡單的任務。首先,Java沒有提供直接的API用於停止線程。此外,停止線程時還有一些額外的細節需要考慮,如待停止的線程處於阻塞(等待鎖)或者等待狀態(等
Spring Boot實戰筆記(三)-- Spring常用配置(Bean的初始化和銷毀、Profile)
div nbsp troy string 實例化 public ive work 初始 一、Bean的初始化和銷毀 在我們的實際開發的時候,經常會遇到Bean在使用之前或之後做些必要的操作,Spring對Bean的生命周期操作提供了支持。在使用Java配置和註解配置下提
shell腳本案例(三)利用top命令精確監控cpu使用率
cpu 監控 shell linux 自動化 需求:利用top命令精確監控CPU 準備知識:top使用、基本的awk、dc(默認bash shell不支持小數點運算) 腳本如下 [root@arppining scripts]# cat cpu.sh #!/bin/bash - # t
Spark SQL筆記整理(三):加載保存功能與Spark SQL函數
code ren maven依賴 append 關聯 dfs 取值 struct nal 加載保存功能 數據加載(json文件、jdbc)與保存(json、jdbc) 測試代碼如下: package cn.xpleaf.bigdata.spark.scala.sql.p1
scala spark-streaming整合kafka (spark 2.3 kafka 0.10)
obj required word 錯誤 prope apache rop sta move Maven組件如下: <dependency> <groupId>org.apache.spark</groupId> <
spark RDD常用運算元(三)
- first、take、collect、count、top、takeOrdered、foreach、fold、reduce、countByValue、lookup 演算法解釋 first:返回第一個元素 take:rdd.t
大資料之電話日誌分析callLog案例(三)
一、查詢使用者最近的通話資訊 -------------------------------------------- 1.實現分析 使用ssm可視介面提供查詢串 -- controller連線 hiveserver2 -- 將命令轉化成hsql語句 -- hive繫結hba
.Net Core 在 Linux-Centos上的部署實戰教程(三)
fuse use yun 失敗 重新 nginx配置 reload cat 實戰 綁定域名,利用Nginx反向代理來操作 1.安裝Nginx yun install nginx 安裝成功 2.啟動nginx service nginx
python實戰演練(三)購物車程序
%s end src mage imp sdi gin gif 名稱 一.實現功能 作業需求: 用戶入口:1.商品信息存在文件裏2.已購商品,余額記錄。第一次啟動程序時需要記錄工資,第二次啟動程序時談出上次余額3.允許用戶根據商品編號購買商品4.用戶選擇商品後,檢測是否夠,
MySql必知必會實戰練習(三)資料過濾 MySql必知必會實戰練習(二)資料檢索
在之前的部落格MySql必知必會實戰練習(一)表建立和資料新增中完成了各表的建立和資料新增,MySql必知必會實戰練習(二)資料檢索中介紹了所有的資料檢索操作,下面對資料過濾操作進行總結。 1. where子句操作符 等於: = 不等於: != 或 <> 小於:
Spark採坑系列(三)Spark操作Hive的坑
跟著教學試著用Idea程式設計,實現Spark查詢Hive中的表。結果上來就涼了。 搗鼓好久都不行,在網上查有說將hive-site.xml放到resource目錄就行,還有什麼hadoop針對windows使用者的許可權問題,結果都是扯淡。 其實問題還是處在程式碼上,直接附上程式碼了
Java 由淺入深GUI程式設計實戰練習(三)
一,專案介紹 1.可以檢視年,月,日等功能。能獲取今天的日期,並且能夠通過下拉年,月的列表。 2.當程式執行時,顯示的時間是系統當前時間。 3.可以手動輸入時間,確定後系統跳轉到制定的時間。 4.提供一種點選功能,通過點選實現年份,月份的自增和自減功能。 二,執行介面 三,程式碼詳情
Spark基礎-scala學習(三)
面向物件程式設計之Trait trait基礎知識 將trait作為介面使用 在trait中定義具體方法 在trait中定義具體欄位 在trait中定義抽象欄位 trait高階知識 為例項物件混入trait trait呼叫鏈 在trait中覆蓋抽象方法 混合使用t
微服務架構實戰篇(三):Spring boot2.0 + Mybatis + PageHelper實現增刪改查和分頁查詢功能
簡介 該專案主要利用Spring boot2.0 +Mybatis + PageHelper實現增刪改查和分頁查詢功能,快速搭建一套和資料庫互動的專案。 小工具一枚,歡迎使用和Star支援,如使用過程中碰到問題,可以提出Issue,我會盡力完善該Starter 版本基礎
《Python3網絡爬蟲實戰案例(崔慶才著)》 中文版PDF下載,附源代碼+視頻教程
圖片 網絡爬蟲 51cto 視頻教程 下載 網絡 png image ref 《Python3網絡爬蟲實戰案例(崔慶才著)》中文版PDF下載,附源代碼+視頻教程,帶目錄資料下載:https://pan.baidu.com/s/1OzxyHQMLOzWFMzjdQ8kEqQ《
Netty實戰手冊(三)
上篇已經講述瞭如何搭建基礎的服務結構,現在瞭解下如何完成與客戶端的通訊模型。 首先,在HandlerService中,處理接收來自客戶端的訊息: @Override public void receive( ChannelHandlerContext _ctx , Object _o
實戰演練(三)
1.羅馬數字與整數之間的轉換 羅馬數字包含以下七種字元:I,V,X,L,C,D和M 字元 數值 I 1 V 5 X 10 L 50 C 100 D 500 M 1000 例如,羅馬數字2寫做 II,即為兩個並排放置的的1、12寫做XII,即為 X + II,27寫做XXVII,即為X