
hive sql語句轉換成mapreduce
1.hive是什麼?
2.MapReduce框架實現SQL基本操作的原理是什麼?
3.Hive怎樣實現SQL的詞法和語法解析?
Hive是基於Hadoop的一個數據倉庫系統,在各大公司都有廣泛的應用。美團資料倉庫也是基於Hive搭建,每天執行近萬次的Hive ETL計算流程,負責每天數百GB的資料儲存和分析。Hive的穩定性和效能對我們的資料分析非常關鍵。
在幾次升級Hive的過程中,我們遇到了一些大大小小的問題。通過向社群的 諮詢和自己的努力,在解決這些問題的同時我們對Hive將SQL編譯為MapReduce的過程有了比較深入的理解。對這一過程的理解不僅幫助我們解決了 一些Hive的bug,也有利於我們優化Hive SQL,提升我們對Hive的掌控力,同時有能力去定製一些需要的功能。
MapReduce實現基本SQL操作的原理
詳細講解SQL編譯為MapReduce之前,我們先來看看MapReduce框架實現SQL基本操作的原理
Join的實現原理
select u.name, o.orderid from order o join user u on o.uid = u.uid;
在map的輸出value中為不同表的資料打上tag標記,在reduce階段根據tag判斷資料來源。MapReduce的過程如下(這裡只是說明最基本的Join的實現,還有其他的實現方式)

Group By的實現原理
select rank, isonline, count(*) from city group by rank, isonline;
將GroupBy的欄位組合為map的輸出key值,利用MapReduce的排序,在reduce階段儲存LastKey區分不同的key。MapReduce的過程如下(當然這裡只是說明Reduce端的非Hash聚合過程)

Distinct的實現原理
select dealid, count(distinct uid) num from order group by dealid;
當只有一個distinct欄位時,如果不考慮Map階段的Hash GroupBy,只需要將GroupBy欄位和Distinct欄位組合為map輸出key,利用mapreduce的排序,同時將GroupBy欄位作 為reduce的key,在reduce階段儲存LastKey即可完成去重
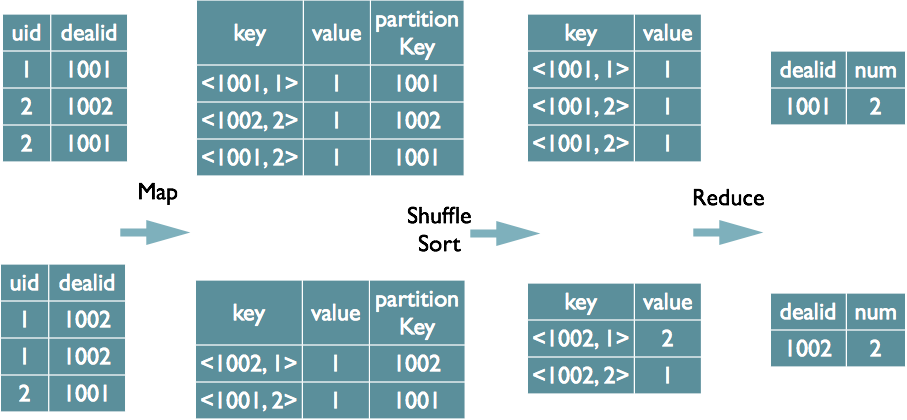
如果有多個distinct欄位呢,如下面的SQL
select dealid, count(distinct uid), count(distinct date) from order group by dealid;
實現方式有兩種:
(1)如果仍然按照上面一個distinct欄位的方法,即下圖這種實現方式,無法跟據uid和date分別排序,也就無法通過LastKey去重,仍然需要在reduce階段在記憶體中通過Hash去重

(2)第二種實現方式,可以對所有的distinct欄位編號,每行資料生成n行資料,那麼相同欄位就會分別排序,這時只需要在reduce階段記錄LastKey即可去重。
這種實現方式很好的利用了MapReduce的排序,節省了reduce階段去重的記憶體消耗,但是缺點是增加了shuffle的資料量。
需要注意的是,在生成reduce value時,除第一個distinct欄位所在行需要保留value值,其餘distinct資料行value欄位均可為空。
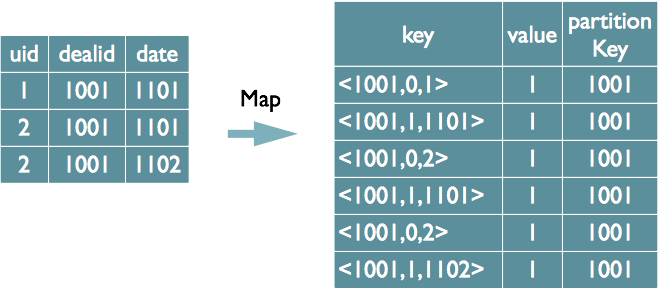
SQL轉化為MapReduce的過程
瞭解了MapReduce實現SQL基本操作之後,我們來看看Hive是如何將SQL轉化為MapReduce任務的,整個編譯過程分為六個階段:
- Antlr定義SQL的語法規則,完成SQL詞法,語法解析,將SQL轉化為抽象語法樹AST Tree
- 遍歷AST Tree,抽象出查詢的基本組成單元QueryBlock
- 遍歷QueryBlock,翻譯為執行操作樹OperatorTree
- 邏輯層優化器進行OperatorTree變換,合併不必要的ReduceSinkOperator,減少shuffle資料量
- 遍歷OperatorTree,翻譯為MapReduce任務
- 物理層優化器進行MapReduce任務的變換,生成最終的執行計劃
下面分別對這六個階段進行介紹
Phase1 SQL詞法,語法解析
Antlr
Hive使用Antlr實現SQL的詞法和語法解析。Antlr是一種語言識別的工具,可以用來構造領域語言。
這裡不詳細介紹Antlr,只需要瞭解使用Antlr構造特定的語言只需要編寫一個語法檔案,定義詞法和語法替換規則即可,Antlr完成了詞法分析、語法分析、語義分析、中間程式碼生成的過程。
Hive中語法規則的定義檔案在0.10版本以前是Hive.g一個檔案,隨著語法規則越來越複雜,由語法規則生成的Java解析類可能超過Java類文 件的最大上限,0.11版本將Hive.g拆成了5個檔案,詞法規則HiveLexer.g和語法規則的4個檔案 SelectClauseParser.g,FromClauseParser.g,IdentifiersParser.g,HiveParser.g。
抽象語法樹AST Tree
經過詞法和語法解析後,如果需要對錶達式做進一步的處理,使用 Antlr 的抽象語法樹語法Abstract Syntax Tree,在語法分析的同時將輸入語句轉換成抽象語法樹,後續在遍歷語法樹時完成進一步的處理。
下面的一段語法是Hive SQL中SelectStatement的語法規則,從中可以看出,SelectStatement包含select, from, where, groupby, having, orderby等子句。
(在下面的語法規則中,箭頭表示對於原語句的改寫,改寫後會加入一些特殊詞標示特定語法,比如TOK_QUERY標示一個查詢塊)
[SQL] 純文字檢視 複製程式碼
|
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 |
|
樣例SQL
為了詳細說明SQL翻譯為MapReduce的過程,這裡以一條簡單的SQL為例,SQL中包含一個子查詢,最終將資料寫入到一張表中
[SQL] 純文字檢視 複製程式碼
|
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 |
|
SQL生成AST Tree
Antlr對Hive SQL解析的程式碼如下,HiveLexerX,HiveParser分別是Antlr對語法檔案Hive.g編譯後自動生成的詞法解析和語法解析類,在這兩個類中進行復雜的解析。
[SQL] 純文字檢視 複製程式碼
|
01 02 03 04 05 06 07 08 09 10 11 12 13 14 |
|
最終生成的AST Tree如下圖右側(使用Antlr Works生成,Antlr Works是Antlr提供的編寫語法檔案的編輯器),圖中只是展開了骨架的幾個節點,沒有完全展開。
子查詢1/2,分別對應右側第1/2兩個部分。
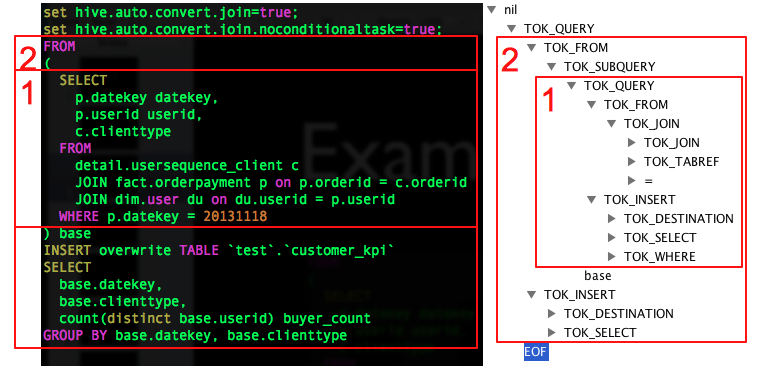
這裡注意一下內層子查詢也會生成一個TOK_DESTINATION節點。請看上面SelectStatement的語法規則,這個節點是在語法改寫中特 意增加了的一個節點。原因是Hive中所有查詢的資料均會儲存在HDFS臨時的檔案中,無論是中間的子查詢還是查詢最終的結果,Insert語句最終會將 資料寫入表所在的HDFS目錄下。
詳細來看,將記憶體子查詢的from子句展開後,得到如下AST Tree,每個表生成一個TOK_TABREF節點,Join條件生成一個“=”節點。其他SQL部分類似,不一一詳述。

Phase2 SQL基本組成單元QueryBlock
AST Tree仍然非常複雜,不夠結構化,不方便直接翻譯為MapReduce程式,AST Tree轉化為QueryBlock就是將SQL進一部抽象和結構化。
QueryBlock
QueryBlock是一條SQL最基本的組成單元,包括三個部分:輸入源,計算過程,輸出。簡單來講一個QueryBlock就是一個子查詢。
下圖為Hive中QueryBlock相關物件的類圖,解釋圖中幾個重要的屬性
- QB#aliasToSubq(表示QB類的aliasToSubq屬性)儲存子查詢的QB物件,aliasToSubq key值是子查詢的別名
- QB#qbp 即QBParseInfo儲存一個基本SQL單元中的給個操作部分的AST Tree結構,QBParseInfo#nameToDest這個HashMap儲存查詢單元的輸出,key的形式是inclause-i(由於Hive 支援Multi Insert語句,所以可能有多個輸出),value是對應的ASTNode節點,即TOK_DESTINATION節點。類QBParseInfo其餘 HashMap屬性分別儲存輸出和各個操作的ASTNode節點的對應關係。
- QBParseInfo#JoinExpr儲存TOK_JOIN節點。QB#QBJoinTree是對Join語法樹的結構化。
- QB#qbm儲存每個輸入表的元資訊,比如表在HDFS上的路徑,儲存表資料的檔案格式等。
- QBExpr這個物件是為了表示Union操作。

AST Tree生成QueryBlock
AST Tree生成QueryBlock的過程是一個遞迴的過程,先序遍歷AST Tree,遇到不同的Token節點,儲存到相應的屬性中,主要包含以下幾個過程
- TOK_QUERY => 建立QB物件,迴圈遞迴子節點
- TOK_FROM => 將表名語法部分儲存到QB物件的TOK_INSERT => 迴圈遞迴子節點
- TOK_DESTINATION => 將輸出目標的語法部分儲存在QBParseInfo物件的nameToDest屬性中
- TOK_SELECT => 分別將查詢表示式的語法部分儲存在destToAggregationExprs、TOK_WHERE => 將Where部分的語法儲存在QBParseInfo物件的destToWhereExpr屬性中
最終樣例SQL生成兩個QB物件,QB物件的關係如下,QB1是外層查詢,QB2是子查詢
QB1 \ QB2
Phase3 邏輯操作符Operator
Operator
Hive最終生成的MapReduce任務,Map階段和Reduce階段均由OperatorTree組成。邏輯操作符,就是在Map階段或者Reduce階段完成單一特定的操作。
基本的操作符包括TableScanOperator,SelectOperator,FilterOperator,JoinOperator,GroupByOperator,ReduceSinkOperator
從名字就能猜出各個操作符完成的功能,TableScanOperator從MapReduce框架的Map介面原始輸入表的資料,控制掃描表的資料行數,標記是從原表中取資料。JoinOperator完成Join操作。FilterOperator完成過濾操作
ReduceSinkOperator將Map端的欄位組合序列化為Reduce Key/value, Partition Key,只可能出現在Map階段,同時也標誌著Hive生成的MapReduce程式中Map階段的結束。
Operator在Map Reduce階段之間的資料傳遞都是一個流式的過程。每一個Operator對一行資料完成操作後之後將資料傳遞給childOperator計算。
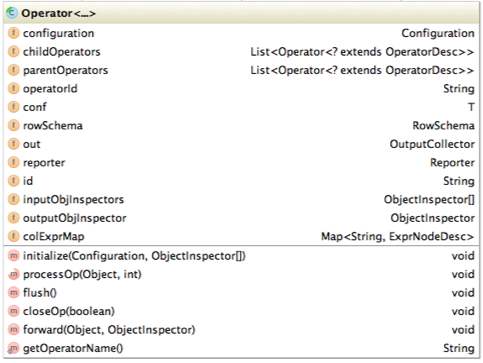
Operator類的主要屬性和方法如下
- RowSchema表示Operator的輸出欄位
- InputObjInspector outputObjInspector解析輸入和輸出欄位
- processOp接收父Operator傳遞的資料,forward將處理好的資料傳遞給子Operator處理
- Hive每一行資料經過一個Operator處理之後,會對欄位重新編號,colExprMap記錄每個表示式經過當前Operator處理前後的名稱對應關係,在下一個階段邏輯優化階段用來回溯欄位名
- 由 於Hive的MapReduce程式是一個動態的程式,即不確定一個MapReduce Job會進行什麼運算,可能是Join,也可能是GroupBy,所以Operator將所有執行時需要的引數儲存在OperatorDesc 中,OperatorDesc在提交任務前序列化到HDFS上,在MapReduce任務執行前從HDFS讀取並反序列化。Map階段 OperatorTree在HDFS上的位置在Job.getConf(“hive.exec.plan”)
+ “/map.xml”
QueryBlock生成Operator Tree
QueryBlock生成Operator Tree就是遍歷上一個過程中生成的QB和QBParseInfo物件的儲存語法的屬性,包含如下幾個步驟:
- QB#aliasToSubq => 有子查詢,遞迴呼叫
- QB#aliasToTabs => TableScanOperator
- QBParseInfo#joinExpr => QBJoinTree => ReduceSinkOperator + JoinOperator
- QBParseInfo#destToWhereExpr => FilterOperator
- QBParseInfo#destToGroupby => ReduceSinkOperator + GroupByOperator
- QBParseInfo#destToOrderby => ReduceSinkOperator + ExtractOperator
由於Join/GroupBy/OrderBy均需要在Reduce階段完成,所以在生成相應操作的Operator之前都會先生成一個ReduceSinkOperator,將欄位組合並序列化為Reduce Key/value, Partition Key
接下來詳細分析樣例SQL生成OperatorTree的過程
先序遍歷上一個階段生成的QB物件
首先根據子QueryBlock
[Plain Text] 純文字檢視 複製程式碼
|
1 |
|
先序遍歷QBJoinTree,類QBJoinTree儲存左右表的ASTNode和這個查詢的別名,最終生成的查詢樹如下 base / \ p du / \ c p
前序遍歷detail.usersequence_client和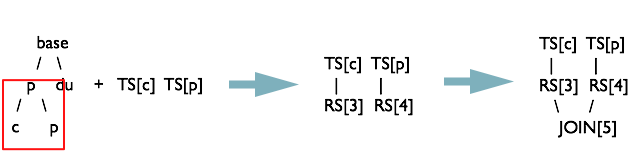
圖中 TS=TableScanOperator RS=ReduceSinkOperator JOIN=JoinOperator
生成中間表與dim.user的Join操作樹
根據QB2 FilterOperator。此時QB2遍歷完成。
下圖中SelectOperator在某些場景下會根據一些條件判斷是否需要解析欄位。

圖中 FIL= FilterOperator SEL= SelectOperator
根據QB1的QBParseInfo#destToGroupby生成ReduceSinkOperator + GroupByOperator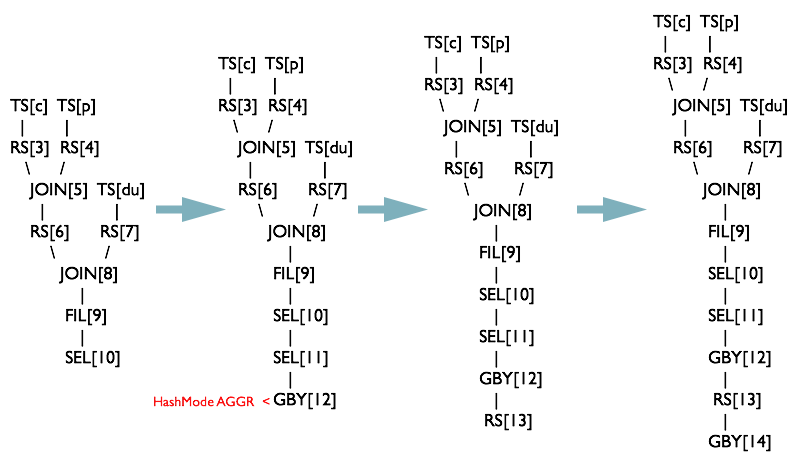
圖中 GBY= GroupByOperator
GBY[12]是HASH聚合,即在記憶體中通過Hash進行聚合運算
最終都解析完後,會生成一個FileSinkOperator,將資料寫入HDFS
圖中FS=FileSinkOperator
Phase4 邏輯層優化器
大部分邏輯層優化器通過變換OperatorTree,合併操作符,達到減少MapReduce Job,減少shuffle資料量的目的。
② MapJoinProcessor
② GroupByOptimizer
① PredicatePushDown
ColumnPruner
|
名稱 |
作用 |
|
② SimpleFetchOptimizer |
優化沒有GroupBy表示式的聚合查詢 |
|
MapJoin,需要SQL中提供hint,0.11版本已不用 |
|
|
② BucketMapJoinOptimizer |
BucketMapJoin |
|
Map端聚合 |
|
|
① ReduceSinkDeDuplication |
合併線性的OperatorTree中partition/sort key相同的reduce |
|
謂詞前置 |
|
|
① CorrelationOptimizer |
利用查詢中的相關性,合併有相關性的Job,HIVE-2206 |
|
欄位剪枝 |
表格中①的優化器均是一個Job幹盡可能多的事情/合併。②的都是減少shuffle資料量,甚至不做Reduce。
CorrelationOptimizer優化器非常複雜,都能利用查詢中的相關性,合併有相關性的Job,參考 Hive Correlation Optimizer
對於樣例SQL,有兩個優化器對其進行優化。下面分別介紹這兩個優化器的作用,並補充一個優化器ReduceSinkDeDuplication的作用
PredicatePushDown優化器
斷言判斷提前優化器將OperatorTree中的FilterOperator提前到TableScanOperator之後
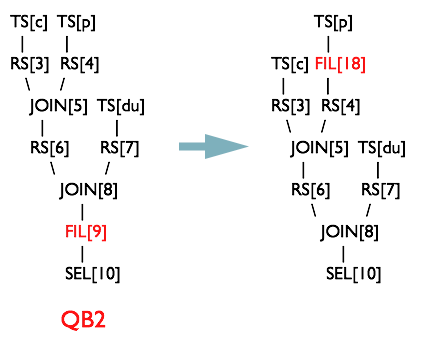
NonBlockingOpDeDupProc優化器
ReduceSinkDeDuplication優化器
ReduceSinkDeDuplication可以合併線性相連的兩個RS。實際上CorrelationOptimizer是 ReduceSinkDeDuplication的超集,能合併線性和非線性的操作RS,但是Hive先實現的 ReduceSinkDeDuplication
譬如下面這條SQL語句
[Python] 純文字檢視 複製程式碼
|
1 |
|
經過前面幾個階段之後,會生成如下的OperatorTree,兩個Tree是相連的,這裡沒有畫到一起
這時候遍歷OperatorTree後能發現前前後兩個RS輸出的Key值和PartitionKey如下
parentRS
|
Key |
PartitionKey |
|
|
childRS |
key |
key |
|
key,value |
key,value |
ReduceSinkDeDuplication優化器檢測到:1. pRS Key完全包含cRS Key,且排序順序一致;2. pRS PartitionKey完全包含cRS PartitionKey。符合優化條件,會對執行計劃進行優化。
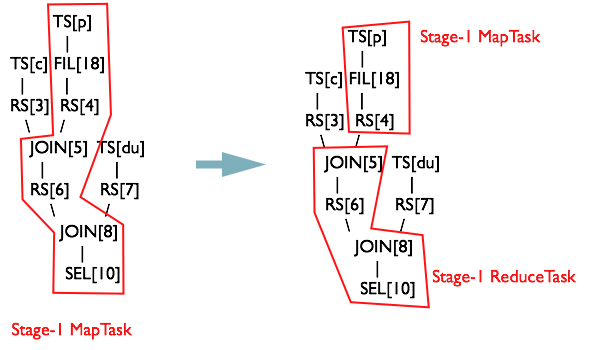
ReduceSinkDeDuplication將childRS和parentheRS與childRS之間的Operator刪掉,保留的RS的Key為key,value欄位,PartitionKey為key欄位。合併後的OperatorTree如下:
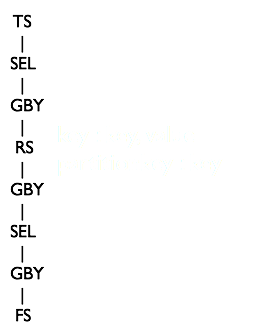
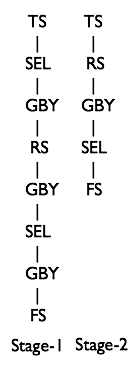
Phase5 OperatorTree生成MapReduce Job的過程
OperatorTree轉化為MapReduce Job的過程分為下面幾個階段
- 對輸出表生成MoveTask
- 從OperatorTree的其中一個根節點向下深度優先遍歷
- ReduceSinkOperator標示Map/Reduce的界限,多個Job間的界限
- 遍歷其他根節點,遇過碰到JoinOperator合併MapReduceTask
- 生成StatTask更新元資料
- 剪斷Map與Reduce間的Operator的關係
對輸出表生成MoveTask
由上一步OperatorTree只生成了一個FileSinkOperator,直接生成一個MoveTask,完成將最終生成的HDFS臨時檔案移動到目標表目錄下
MoveTask[Stage-0] Move Operator
開始遍歷
將OperatorTree中的所有根節點儲存在一個toWalk的陣列中,迴圈取出陣列中的元素(省略QB1,未畫出)

取出最後一個元素TS[p]放入棧 opStack{TS[p]}中
Rule #1 TS% 生成MapReduceTask物件,確定MapWork
發現棧中的元素符合下面規則R1(這裡用python程式碼簡單表示)
[Python] 純文字檢視 複製程式碼
|
1 |
|
生成一個MapReduceTask[Stage-1]物件的MapReduceTask[Stage-1]包含了以

Rule #2 TS%.*RS% 確定ReduceWork
繼續遍歷TS[p]的子Operator,將子Operator存入棧opStack中
當第一個RS進棧後,即棧opStack = {TS[p], FIL[18], RS[4]}時,就會滿足下面的規則R2
[Python] 純文字檢視 複製程式碼
|
1 |
|
這時候在ReduceWork屬性儲存
Rule #3 RS%.*RS% 生成新MapReduceTask物件,切分MapReduceTask
繼續遍歷JOIN[5]的子Operator,將子Operator存入棧opStack中
當第二個RS放入棧時,即當棧
[Python] 純文字檢視 複製程式碼
|
1 |
|
這時候建立一個新的JOIN[5]和JOIN[5]生成一個子OperatorRS[6]生成一個MapReduceTask[Stage-2]物件的TS[20]的引用。
新生成的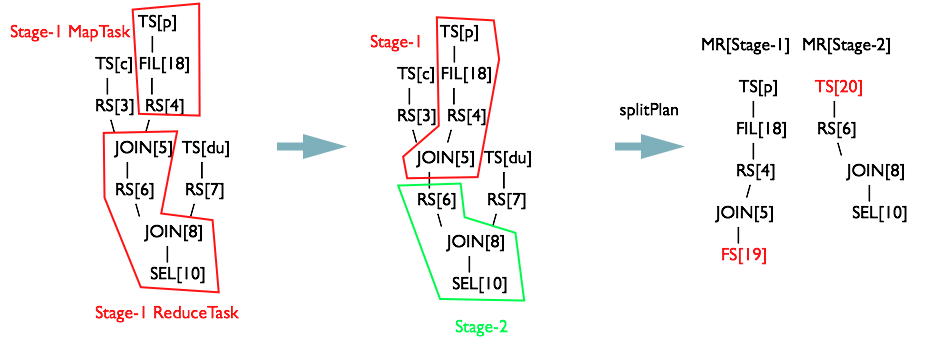
繼續遍歷RS[6]的子Operator,將子Operator存入棧opStack中
當
同理生成
R4 FS% 連線MapReduceTask與MoveTask
最終將所有子Operator存入棧中之後,
[Python] 純文字檢視 複製程式碼
|
1 |
|
這時候將MapReduceTask[Stage-3]連線起來,並生成一個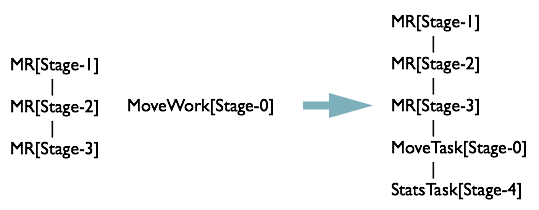
合併Stage
此時並沒有結束,還有兩個根節點沒有遍歷。
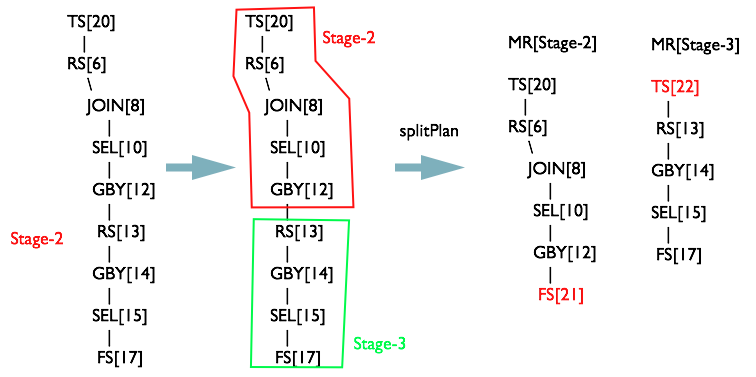
將opStack棧清空,將toWalk的第二個元素加入棧。會發現MapReduceTask[Stage-5]
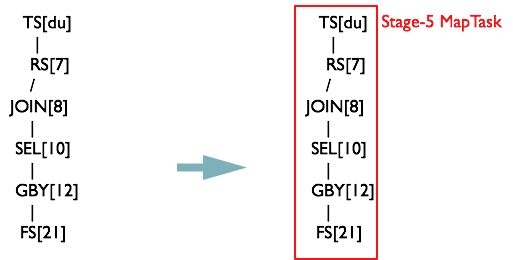
繼續從opStack={TS[du],
RS[7]}時,滿足規則R2 TS%.*RS%
此時將MapReduceTask[Stage-5]的Map<Operator,
MapReduceWork>物件中發現,MapReduceTask[Stage-2]和
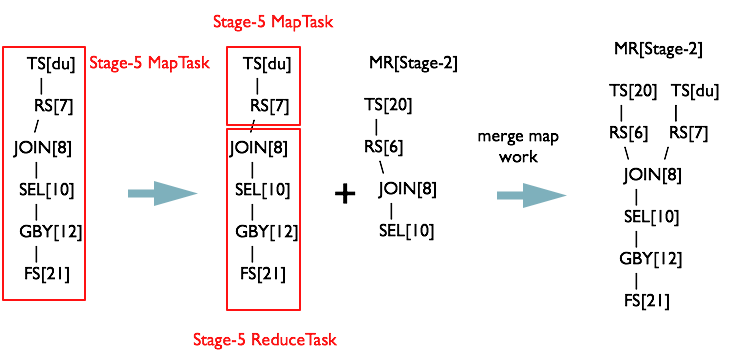
同理從最後一個根節點
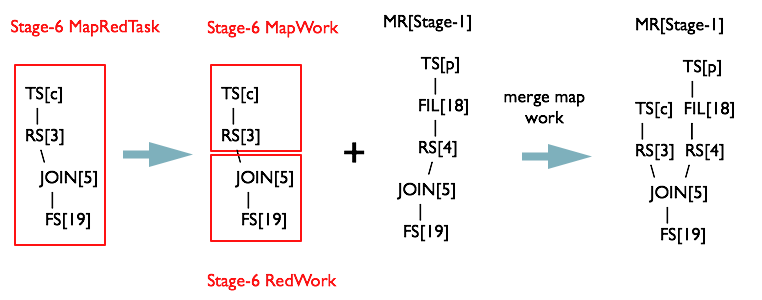
切分Map Reduce階段
最後一個階段,將MapWork和ReduceWork中的OperatorTree以RS為界限剪開

OperatorTree生成MapReduceTask全貌
最終共生成3個MapReduceTask,如下圖
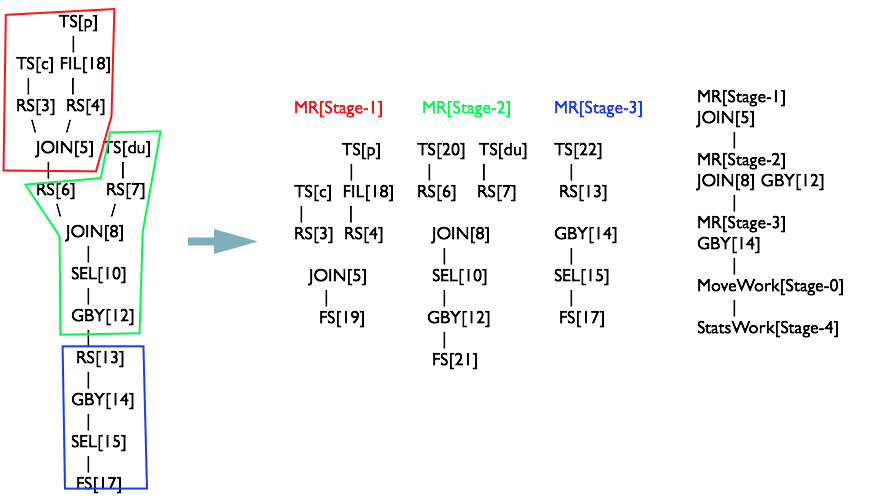
Phase6 物理層優化器
這裡不詳細介紹每個優化器的原理,單獨介紹一下MapJoin的優化器
SortMergeJoinResolver
CommonJoinResolver + MapJoinResolver
|
名稱 |
作用 |
|
Vectorizer |
HIVE-4160,將在0.13中釋出 |
|
與bucket配合,類似於歸併排序 |
|
|
SamplingOptimizer |
並行order by優化器,在0.12中釋出 |
|
MapJoin優化器 |
MapJoin原理
MapJoin簡單說就是在Map階段將小表讀入記憶體,順序掃描大表完成Join。
上圖是Hive MapJoin的原理圖,出自Facebook工程師Liyin Tang的一篇介紹Join優化的slice,從圖中可以看出MapJoin分為兩個階段:
-
通過MapReduce Local Task,將小表讀入記憶體,生成HashTableFiles上傳至Distributed Cache中,這裡會對HashTableFiles進行壓縮。
-
MapReduce Job在Map階段,每個Mapper從Distributed Cache讀取HashTableFiles到記憶體中,順序掃描大表,在Map階段直接進行Join,將資料傳遞給下一個MapReduce任務。

如果Join的兩張表一張表是臨時表,就會生成一個ConditionalTask,在執行期間判斷是否使用MapJoin
CommonJoinResolver優化器
CommonJoinResolver優化器就是將CommonJoin轉化為MapJoin,轉化過程如下
- 深度優先遍歷Task Tree
- 找到JoinOperator,判斷左右表資料量大小
- 對與小表 + 大表 => MapJoinTask,對於小/大表 + 中間表 => ConditionalTask
遍歷上一個階段生成的MapReduce任務,發現JOIN[8]中有一張表為臨時表,先對Stage-2進行深度拷貝(由於需要保留原始執行計劃為Backup
Plan,所以這裡將執行計劃拷貝了一份),生成一個MapJoinOperator替代JoinOperator,然後生成一個MapReduceLocalWork讀取小表生成HashTableFiles上傳至DistributedCache中。
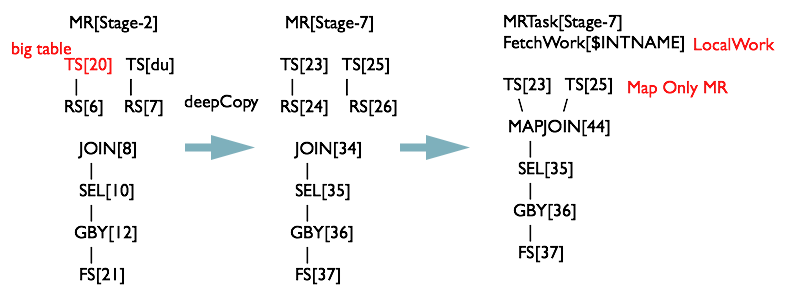
MapReduceTask經過變換後的執行計劃如下圖所示
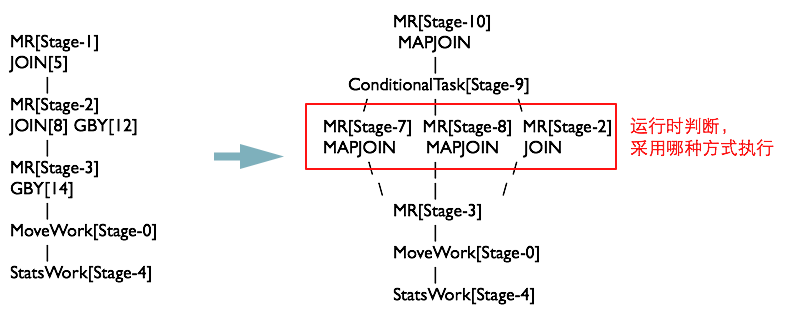
MapJoinResolver優化器
MapJoinResolver優化器遍歷Task Tree,將所有有local work的MapReduceTask拆成兩個Task

最終MapJoinResolver處理完之後,執行計劃如下圖所示

Hive SQL編譯過程的設計
從上述整個SQL編譯的過程,可以看出編譯過程的設計有幾個優點值得學習和借鑑
- 使用Antlr開源軟體定義語法規則,大大簡化了詞法和語法的編譯解析過程,僅僅需要維護一份語法檔案即可。
- 整體思路很清晰,分階段的設計使整個編譯過程程式碼容易維護,使得後續各種優化器方便的以可插拔的方式開關,譬如Hive 0.13最新的特性Vectorization和對Tez引擎的支援都是可插拔的。
- 每個Operator只完成單一的功能,簡化了整個MapReduce程式。
社群發展方向
Hive依然在迅速的發展中,為了提升Hive的效能,hortonworks公司主導的Stinger計劃提出了一系列對Hive的改進,比較重要的改進有:
- Vectorization - 使Hive從單行單行處理資料改為批量處理方式,大大提升了指令流水線和快取的利用率
- Hive on Tez - 將Hive底層的MapReduce計算框架替換為Tez計算框架。Tez不僅可以支援多Reduce階段的任務MRR,還可以一次性提交執行計劃,因而能更好的分配資源。
- Cost Based Optimizer - 使Hive能夠自動選擇最優的Join順序,提高查詢速度
- Implement insert, update, and delete in Hive with full ACID support - 支援表按主鍵的增量更新
我們也將跟進社群的發展,結合自身的業務需要,提升Hive型ETL流程的效能