caffe多工學習之多標籤分類
阿新 • • 發佈:2019-02-15
最近在參加一個識別的競賽,專案裡涉及了許多類別的分類,原本打算一個大的類別訓練一個分類模型,但是這樣會比較麻煩,對於同一圖片的分類會重複計算分類網路中的卷積層,浪費計算時間和效率。後來發現現在深度學習中的多工學習可以實現多標籤分類,所有的類別只需要訓練一個分類模型就行,其不同屬性的類別之間是共享卷積層的。我所有的專案開發都是基於caffe框架的,預設的,Caffe中的Data層只支援單維標籤,不支援多標籤分類。我也是參考了大牛的部落格修改了caffe裡面的原始碼,使得caffe支援多標籤分類。下面介紹怎麼在caffe中修改原始碼支援多標籤,包括訓練和測試過程的修改。
Caffe原始碼修改:
需要修改Caffe中的convert_imageset.cpp以支援多標籤,convert_imageset.cpp是在caffe的根目錄下的tools檔案下。我是直接下載了修改後的convert_imageset.cpp替換了我原來的convert_imageset.cpp。然後需要重新編譯caffe,進入caffe目錄下,輸入指令:
make clean
make –j4
make pycaffe
好了,到了這裡如果沒有出錯caffe就可以支援多標籤分類了,接下來就是根據自己的資料和多標籤類別數目訓練網路模型。
注:基於好多人找我要convert_imageset.cpp,我把它上傳了:
需要的可以自己去下載。
修改程式碼如下:
Caffe原始碼修改:
需要修改Caffe中的convert_imageset.cpp以支援多標籤,convert_imageset.cpp是在caffe的根目錄下的tools檔案下。我是直接下載了修改後的convert_imageset.cpp替換了我原來的convert_imageset.cpp。然後需要重新編譯caffe,進入caffe目錄下,輸入指令:
make clean
make –j4
make pycaffe
好了,到了這裡如果沒有出錯caffe就可以支援多標籤分類了,接下來就是根據自己的資料和多標籤類別數目訓練網路模型。
注:基於好多人找我要convert_imageset.cpp,我把它上傳了:
需要的可以自己去下載。
修改程式碼如下:
std::ifstream infile(argv[2]);
std::vector<std::pair<std::string, std::vector<float>> > lines;
std::string filename;
std::string label_count_string = argv[5];
int label_count = std::atoi(label_count_string.c_str());
std - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
訓練模型:
上面我們就有了多工的深度學習的基礎部分資料輸入。為了向上相容Caffe框架,我也是參考了大牛的部落格,摒棄了部分開源實現增加Data層標籤維度選項並修改Data層程式碼的做法,直接使用兩個Data層將資料讀入,即分別讀入資料和多維標籤。接下來詳細介紹訓練所需要做的步驟以及和修改。
1. Lmdb的資料製作
由於篇幅的原因,我只貼了部分主要的程式碼圖,注意下圖示紅的部分,第一個是你多標籤所需要的類別數目,第二個是一些資料的路徑。
由於現在為了支援多標籤,把資料和標籤分開了,以前的單標籤在data層資料和標籤在一起的對應的(自己的理解)。所以第三和第四初標紅的是test和train最後用於訓練的lmdb資料和對應多維標籤。這製作lmdb指令碼檔案我會放在我的部落格資源上:
http://download.csdn.net/detail/xjz18298268521/9708564
你們可以根據自己的需求下載後自己修改,執行指令碼檔案後,相對應的路徑下會生成對應的四個lmdb資料檔案。到這裡lmdb的資料製作完畢,後面的均值檔案的製作和原來的是一樣的。
2.修改訓練網路模型train_val.prototxt

#訓練資料層
name: "CaffeNet"
layer {
name: "data"
type: "Data"
top: "data" #原來的是兩層top
include {
phase: TRAIN
}
transform_param {
mirror: true
crop_size: 227
mean_file: "/home/xjz/multiple-caffe/caffe-master/examples/multiple-lable/caffenet/mean.binaryproto"
}
data_param {
source: "/home/xjz/multiple-caffe/caffe-master/examples/multiple-lable/caffenet/ten_classes_train_lmdb"
batch_size: 128
backend: LMDB
}
}
#訓練資料標籤層
layer {
name: "data"
type: "Data"
top: "label"
include {
phase: TRAIN
}
data_param {
source: "/home/xjz/multiple-caffe/caffe-master/examples/multiple-lable/caffenet/ten_classes_train_label_lmdb"
batch_size: 128
backend: LMDB
}
}
#測試資料層
layer {
name: "data"
type: "Data"
top: "data"
include {
phase: TEST
}
transform_param {
mirror: false
crop_size: 227
mean_file: "/home/xjz/multiple-caffe/caffe-master/examples/multiple-lable/caffenet/mean.binaryproto"
}
data_param {
source: "/home/xjz/multiple-caffe/caffe-master/examples/multiple-lable/caffenet/ten_classes_val_lmdb"
batch_size: 100
backend: LMDB
}
}
#測試資料標籤層
layer {
name: "data"
type: "Data"
top: "label"
include {
phase: TEST
}
data_param {
source: "/home/xjz/multiple-caffe/caffe-master/examples/multiple-lable/caffenet/ten_classes_val_label_lmdb"
batch_size: 100
backend: LMDB
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
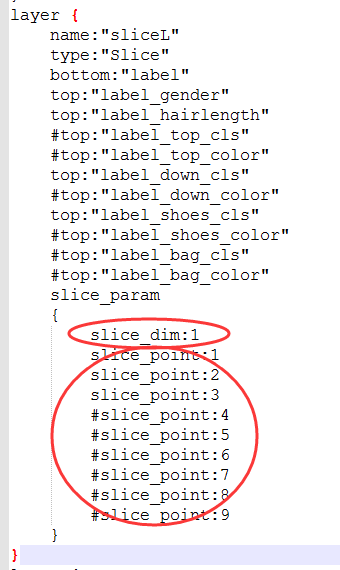
修改完網路模型的data層,後面需要將標籤資料庫中的內容進行切分,拆分成各個屬性的標籤,需要新增Slice層,Slice層是將一個輸入層根據切割指標給定的維度(現在只有num和channel)切割成多個輸出層,如下圖所示。有幾類標籤就定義幾類top並命名不同,用於連線最後的accuracy層。對於slice層的引數:
- slice_dim: 目標維度,0 for num and 1for channel,一般選1;
- slice_point:指定選定維數的索引(索引的數量必須等於blob數量減去一),我一共是4,所以減一為3。
3.最後的損失函式的設計
以前單標籤的時候,只需要設計一個損失函式,現在是多標籤分類需要設計多個損失函式層,使得每一大類別對應一個損失函式層,下圖是一個類別的損失函式層和對應的test層:
對於Accuracy層中的兩個bottom:第一個需要連線對應的全連線層,第二個需要連線前面用slice層切割對應的標籤層。
對於softmaxwithloss層的兩個bottom:第一個需要連線對應的全連線層,第二個需要連線前面用slice層切割對應的標籤層。Loss_weight:需要填寫這個損失函式的損失值在最終總的損失函式值中所佔的權重值,一般的,建議所有任務的權重值相加為1,如果這個數值不設定,可能會導致網路收斂不穩定,這是因為多工學習中對不同任務的梯度進行累加,導致梯度過大,甚至可能引發引數溢位錯誤導致網路訓練失敗。
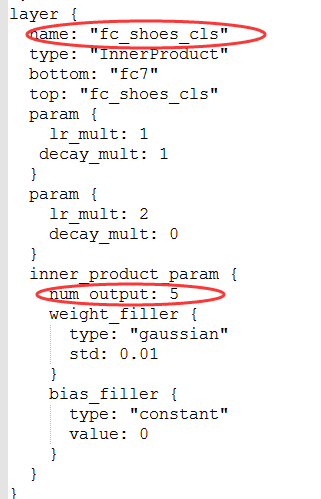
這裡還有一個問題,就是以前單標籤的時候,最後一層的全連線層fc8層的out_num是固定的,大小是根據單標籤分類的類別數目來定的,而現在多標籤中的每一個標籤的類別屬性大小是不同一的。所以這裡在每一標籤對應的損失函式前新增一個全連線層,對應的輸出out_num大小等於對應標籤的類別數目。新增的所有全連線層都連線到原來的第二個全連線層,即fc7層,如下圖所示,到這裡訓練基本的都準備完畢,後面的訓練的步驟和原來單標籤的訓練基本是一樣的,接下來就可以訓練了。
測試過程
修改deploy.prototxt檔案,前面的網路層是不需要修改的,只需要修改對應的最後一層全連線層和損失函式層,修改的方式和前面訓練trian_val.prototxt的是一樣的,每一個標籤類別需要一個屬於自己的全連線層和損失函式層,如下圖所示: