
10 scrapy框架解讀--深入理解爬蟲原理
阿新 • • 發佈:2019-02-15

scrapy框架結構圖:
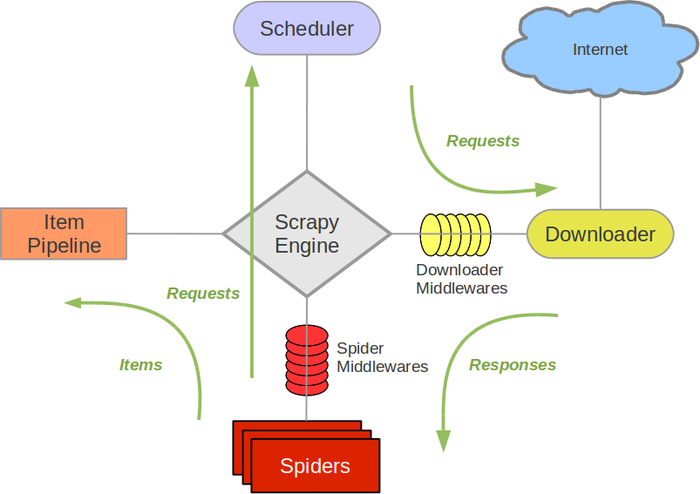
組成部分介紹:
Scrapy Engine:
負責元件之間資料的流轉,當某個動作發生時觸發事件Scheduler:
接收requests,並把他們入隊,以便後續的排程Downloader:
負責抓取網頁,並傳送給引擎,之後抓取結果將傳給spiderSpiders:
使用者編寫的可定製化的部分,負責解析response,產生items和URLItem Pipeline:
負責處理item,典型的用途:清洗、驗證、持久化Downloader middlewares:
位於引擎和下載器之間的一個鉤子,處理傳送到下載器的requests和傳送到引擎的response(若需要在Requests到達Downloader之前或者是responses到達spiders之前做一些預處理,可以使用該中介軟體來完成)Spider middlewares:
位於引擎和抓取器之間的一個鉤子,處理抓取器的輸入和輸出
(在spiders產生的Items到達Item Pipeline之前做一些預處理或response到達spider之前做一些處理)
Scrapy中的資料流:
- Scrapy中的資料流由執行引擎控制,其過程如下:
- 引擎開啟一個網站(open a domain),找到處理該網站的spider,並向該spider請求第一個要爬取的url(s);
- 引擎從spider中獲取到第一個要爬取的url並在排程器(scheduler)以requests排程;
- 引擎向排程器請求下一個要爬取的url;
- 排程器返回下一個要爬取的url給引擎,引擎將url通過下載器中介軟體(請求requests方向)轉發給下載器(Downloader);
- 一旦頁面下載完畢,下載器生成一個該頁面的responses,並將其通過下載器中介軟體(返回responses方向)傳送給引擎;
- 引擎從下載器中接收到responses並通過spider中介軟體(輸入方向)傳送給spider處理;
- spider處理responses並返回爬取到的Item及(跟進的)新的resquests給引擎
- 引擎將(spider返回的)爬取到的Item給Item Pipeline,將(spider返回的)requests給排程器;
- (從第二部)重複直到(排程器中沒有更多的request)引擎關閉該網站
中介軟體的編寫:
down loader middle ware – 檢視文件151頁
spider middle wares – 檢視文件162頁