
【論文筆記】Text-Recognition_簡略版_201606
【1】Shi B, Wang X, Lv P, et al. Robust Scene Text Recognition with Automatic Rectification[J]. arXiv preprint arXiv:1603.03915, 2016.
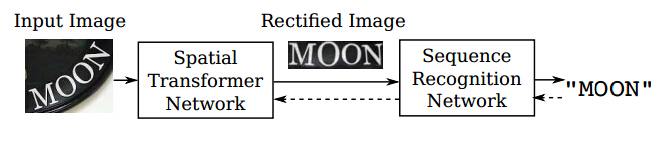
上圖即為本篇論文的系統框架:包括 Spatial Transformer Network (STN ) 以及 Sequence Recognition Network (SRN ) 兩個網路結構。其中, STN 通過 Thin-Plate-Spline 變換,能夠將透射變換或者彎曲的文字圖片對齊到一個正規的、更易讀的圖片;SRN 能夠直接將輸入的文字圖片識別為一個文字序列。
這個系統是一個端到端的文字識別系統,在訓練過程中也不需要額外標記字串的關鍵點、字元位置等。同時,由於 STN 和 SRN 這兩個網路的共同作用,該系統在自然場景的文字識別方面取得了 state-of-the-art 的結果,特別是對於那些有著各種形變的字元圖片。
相關推薦
【論文筆記】Text-Recognition_簡略版_201606
【1】Shi B, Wang X, Lv P, et al. Robust Scene Text Recognition with Automatic Rectification[J]. arXiv p
【論文筆記】3D人臉重建_簡略版(時時更新中)
20160221 1. Liu F, Zeng D, Li J, et al. Cascaded regressor based 3d face reconstruction from a single arbitrary view image[J]. a
【論文筆記】Deep Structured Output Learning for Unconstrained Text Recognition
寫在前面: 我看的paper大多為Computer Vision、Deep Learning相關的paper,現在基本也處於入門階段,一些理解可能不太正確。說到底,小女子才疏學淺,如果有錯誤及理解不透
【論文筆記】FOTS: Fast Oriented Text Spotting with a Unified Network
pdf連結:https://arxiv.org/pdf/1801.01671.pdf資料集的相關情況:1.ICDAR2013ICDAR2013包括四個資料夾,分別是:訓練影象集:Challenge2_Training_Task12_Images訓練標註集:Challenge2
【論文筆記】T Test
nor thum pan n-1 統計學 for nes 其它 align 用來算兩組數的差別大小 只要是一種叫做p-value的 就是說假如你測定一個實驗的p-value是5%也就是說你有95%的信心確定這個實驗它是正確的在正規的實驗裏 只有當p-value小於5%的時候
Reading Wikipedia to Answer Open-Domain Questions【論文筆記】
一、摘要 這篇文章主要是介紹使用維基百科作為唯一的知識庫來解決開放域問答。大規模機器閱讀任務的主要挑戰是文件檢索(查詢相關文章)和機器閱讀理解(從文章中確定答案片段)。作者的方法將基於bigram hashing 和TF-IDF匹配的搜尋元件與經過訓練以檢測維基百科段落中的答案的多層
Semantic Parsing via Staged Query Graph Generation: Question Answering with Knowledge Base【論文筆記】
一、摘要 我們對知識庫問答提出一個新穎的語義解析框架。我們定義了一個類似於知識庫子圖的查詢圖,可以直接對映為邏輯形式。語義解析被簡化為查詢圖生成,被表述為分階段搜尋問題。與傳統方法不同,我們的方法在早期就利用知識庫來修剪搜尋空間,從而簡化語義匹配問題。通過應用實體鏈指系統和深度卷
Question Answering over Freebase with Multi-Column Convolutional Neural Networks【論文筆記】
一、概要 通過知識庫回答自然語言問題是一個重要的具有挑戰性的任務。大多數目前的系統依賴於手工特徵和規則。本篇論文,我們介紹了MCCNNs,從三個不同層面(答案路徑,答案型別,答案上下文)來理解問題。同時,在知識庫中我們共同學習實體和關係的低維詞向量。問答對用於訓練模型以對候選答案
Context-Aware Basic Level Concepts Detection in Folksonomies【論文筆記】
一、概要 這篇論文討論了在 folksonomies中探索隱含語義的問題。在 folksonomies中,使用者建立和管理標籤來標註web資源。使用者建立的標籤的集合是潛在的語義資源。做了大量研究來抽取概念,甚至概念層次 (本體),這是知識表示的重要組成部分。沒有用於發現人類可接受和令人滿意
Question Answering with Subgraph Embeddings【論文筆記】
一、摘要 這篇論文提出一個系統,在大範圍主題的知識庫中,學習使用較少的手工特徵來回答問題。我們的模型學習單詞和知識庫組成的低維詞向量。這些表示用於根據候選答案對自然語言問題打分。使用成對的問題和對應答案的結構化表示,和成對的問題釋義來訓練系統,在最近的文獻基準中產生有競爭力的結果。 &n
Information Extraction over Structured Data: Question Answering with Freebase【論文筆記】
Information Extraction over Structured Data:Question Answering with Freebase 一、摘要
Semantic Parsing on Freebase from Question-Answer Pairs【論文筆記】
參考:https://zhuanlan.zhihu.com/p/25759682 原文:https://cs.stanford.edu/~pliang/papers/freebase-emnlp2013.pdf 一 、摘要 作者訓練了一個可擴充套件到Freebase的語義解析器,由於
vggface2人臉識別資料集 【論文筆記】VGGFace2——一個能夠用於識別不同姿態和年齡人臉的資料集
原 【論文筆記】VGGFace2——一個能夠用於識別不同姿態和年齡人臉的資料集 2018年01月10日 14:53:31 有來有去-CV 閱讀數:6701
【論文筆記】使用多流密集網路的密度感知單影象去雨
使用多流密集網路的密度感知單影象去雨 《Density-aware Single Image De-reaining using a Multi-stream Dense Network》 0 概要 這裡提出一種密度感知多路稠密連線神經網路演算法,DID-MDN,來雨量
【論文筆記】用形狀做擋風玻璃上的雨滴檢測《Detection Of Raindrop With Various Shapes On A Windshield》
《Detection of Raindrop with Various Shapes on a Windshield》 1 介紹 2 雨滴檢測方法 在白天和夜晚使用不同的演算法。通過整幅影象的強度水平判斷是白天還是夜晚。 2.1 白天的雨滴檢測方法 這個方法假設
【論文筆記】光流在視訊行為識別中的作用
0. 引言 在做視訊行為識別時,特別是基於two-stream框架時,常常會引入光流圖作為雙流網路其中一支的輸入。這是很常用,且在各資料集上已被證明有效的做法。但是,關於光流在行為識別中到底起到了什麼作用其實並沒有明確的研究。通常我們認為光流代表了視訊的m
【論文筆記】Margin Sample Mining Loss: A Deep Learning Based Method for Person Re-identification
摘要 Person re-identification (ReID) is an important task in computer vision. Recently, deep learning with a metric learning loss has becom
【論文筆記】Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
寫在前面: 我看的paper大多為Computer Vision、Deep Learning相關的paper,現在基本也處於入門階段,一些理解可能不太正確。說到底,小女子才疏學淺,如果有錯
【論文筆記】視訊物體檢測(VID)系列 NoScope:1000x的視訊檢索加速演算法
計算機視覺的進展,特別是近期深度神經網路的進展,使得在不斷增長的視訊資料中進行檢索成為可能。但是,基於神經網路去做大規模視訊檢索,直接的問題就是計算量激增。比如現在最快的物體檢測器能達到1~2.5x real time的效率(30~80fps),前提是買一個
【論文筆記】In Defense of the Triplet Loss for Person Re-Identification
1、前言 Triplet loss是非常常用的一種deep metric learning方法,在影象檢索領域有非常廣泛的應用,比如人臉識別、行人重識別、商品檢索等。傳統的triplet loss訓練需要一個三元組,包括三張圖片:achor,positive,