
python爬蟲編碼徹底解決
目錄
編碼原理及區別
- 第一階段:編碼的由來:大家都知道計算機的母語是英語,英語是由26個字母組成的。所以最初的計算機字元編碼是通過ASCII來編碼的,也是現今最通用的單位元組編碼系統,使用7位二進位制數來表示所有的字母、數字、標點符號及一些特殊控制字元,作為美國編碼標準來使用。
- 第二階段:由於計算機的不斷普及,計算機進入了不同的國家和地區。很快表現出了眾多的水土不服的症狀。比如:中國人就表示不服,就不能讓計算機說中文嗎?但是ASCII編碼用上渾身解數256個字元也不夠中文用啊。
因此後來出現了Unicode編碼。Unicode編碼通常由兩個位元組組成,共表示256*256個字元,即所謂的UCS-2。某些生僻的字還會用到四個位元組,即UCS-4。Unicode向下相容ASCII。 - 第三個階段:在Unicode中,很快,美國人不高興了,原本用一個位元組就夠了,現在卻要用兩個位元組來表示,非常浪費儲存空間和傳輸速度。人們再發揮聰明才智,於是出現了UTF-8編碼。主要針對空間浪費的問題。UTF-8從英文字母的一個位元組,到中文的通常的三個位元組,再到某些生僻字的六個位元組。解決了空間浪費的問題,並且相容老大哥ASCII編碼。這樣一些老古董軟體在UTF-8編碼中可以繼續工作了。
另外需要注意的是漢字在Unicode編碼和UTF-8編碼中通常是不同的。 - 第四個階段:同樣我們祖國也制定了自己的一套標準。那就是GB2312和GBK。但是大多數還是直接用的UTF-8。UTF-8/UTF-16等是對Unicode進行了編碼,是其一種實現方式。
另外還有ISO-8859-1,ISO-8859-1是單位元組編碼,向下相容ASCII,是許多歐洲國家使用的編碼標準。
Unicode是國際通用的編碼標準,可以表示全世界的字元,但其字符集也是最複雜、佔用空間最大的。開發者可以根據需要進行選擇編碼方式。
編碼與解碼
decode:編碼
encode:解碼
如下圖:
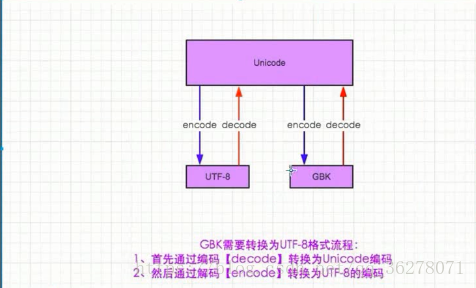
可以看出Unicode充當的一個翻譯官的角色,(差不多所有的編碼方式都可轉化為Unicode)
爬取中文百度首頁
第一步:
import requests
url=’https://www.baidu.com/’
html=requests.get(url).text
print(html)
輸出錯誤的結果如下圖

很明顯是編碼的問題,讓我們來看看百度用的什麼編碼。

再看看我們自己用的編碼:
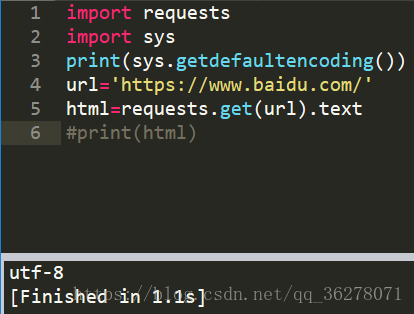
那麼問題來了,同樣都是utf-8為什麼會出現GBK錯誤呢?
第二步:
這個原因確實弄的我腦殼痛,怎麼也找不到原因,各種編碼都試過了結果還是不行。後來我想能不能直接輸出它的編碼方式。於是有了下面的結果。
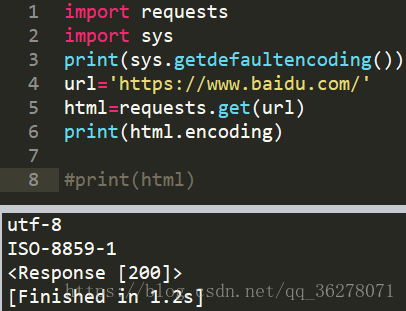
好傢伙!原來你他媽的不是utf-8編碼。把我害的好苦啊!
至於為什麼是‘ISO-8559-1’編碼我個人猜的應該是下載網頁的時候解壓縮導致的。注意啊是我猜的,我沒去看,有空去看看
第三步:
這下好了,應該可以解決了!
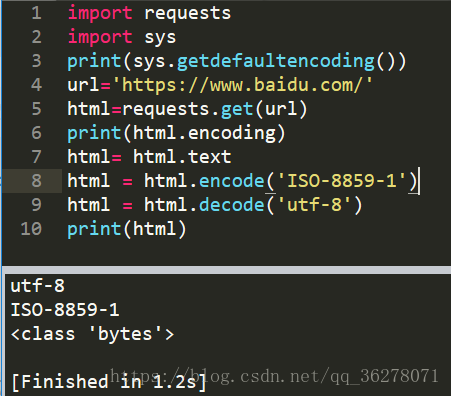
著實有些尷尬,按道理說應該能夠輸出正確答案了呀!可現在卻什麼都沒了。於是我又想起了有一個輸出格式的,我猜應該是這個原因。
於是我添加了如下程式碼
import io
sys.stdout=io.TextIOWrapper(sys.stdout.buffer,encoding='utf-8')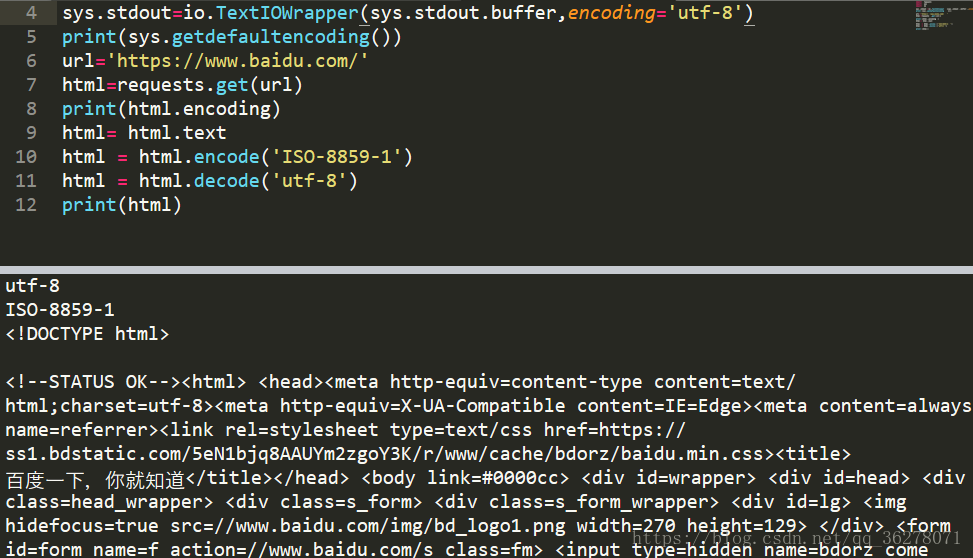
到這裡,這次編碼風波終於過去了!
BeautifulSoup庫
解決編碼問題期間看到別人寫的python程式碼,突然發現一個很好用的包,BeautifulSoup。於是我也裝了個完了玩。
將下載下來的百度的原始碼生成了一個soup物件,於是有了後面的漂亮的格式。
新增程式碼如下:
from bs4 import BeautifulSoup
#使用ISO-8859-1解碼之後的程式碼
soup = BeautifulSoup(html)
print(soup.prettify())效果如下:
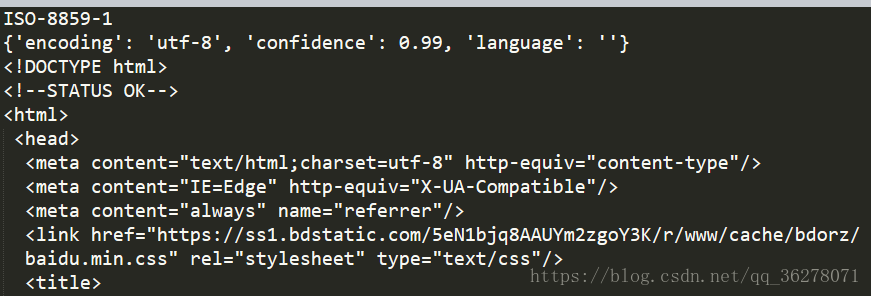
是不是漂亮多了!
其實BeautifulSoup的功能遠不止次,之後的應用過一段時間補上。
到此這篇部落格就結束了,這篇部落格也是治好了我多年的心病,就以為這個梗弄的我好久沒有用過python爬蟲了,現在解決了,以後一定會勤加練習。