
面試常見題(非演算法)
linux和os:
netstat tcpdump ipcs ipcrm (如果這四個命令沒聽說過或者不能熟練使用,基本上可以回家,通過的概率較小 ^_^ ,這四個命令的熟練掌握程度基本上能體現面試者實際開發和除錯程式的經驗)
cpu 記憶體 硬碟 等等與系統性能除錯相關的命令必須熟練掌握,設定修改許可權 tcp網路狀態檢視 各程序狀態 抓包相關等相關命令 必須熟練掌握
awk sed需掌握
共享記憶體的使用實現原理(必考必問,然後共享記憶體段被對映進程序空間之後,存在於程序空間的什麼位置?共享記憶體段最大限制是多少?)
c++程序記憶體空間分佈(注意各部分的記憶體地址誰高誰低,注意棧從高道低分配,堆從低到高分配)
ELF是什麼?其大小與程式中全域性變數的是否初始化有什麼關係(注意.bss段)
使用過哪些程序間通訊機制,並詳細說明(重點)
makefile編寫,雖然比較基礎,但是會被問到
gdb除錯相關的經驗,會被問到
如何定位記憶體洩露?
動態連結和靜態連結的區別
32位系統一個程序最多多少堆記憶體
多執行緒和多程序的區別(重點 面試官最最關心的一個問題,必須從cpu排程,上下文切換,資料共享,多核cup利用率,資源佔用,等等各方面回答,然後有一個問題必須會被問到:哪些東西是一個執行緒私有的?答案中必須包含暫存器,否則悲催)
寫一個c程式辨別系統是64位 or 32位
寫一個c程式辨別系統是大端or小端位元組序
訊號:列出常見的訊號,訊號怎麼處理?
i++是否原子操作?並解釋為什麼???????
說出你所知道的各類linux系統的各類同步機制(重點),什麼是死鎖?如何避免死鎖(每個技術面試官必問)
列舉說明linux系統的各類非同步機制
exit() _exit()的區別?
如何實現守護程序?
linux的記憶體管理機制是什麼?
linux的任務排程機制是什麼?
標準庫函式和系統呼叫的區別?
補充一個坑爹坑爹坑爹坑爹的問題:系統如何將一個訊號通知到程序?(這一題哥沒有答出來)
c語言
1、巨集定義和展開(必須精通)
簡單巨集定義:#define N 100
型別重新命名: #define BOOL int
控制條件編譯: #define DEBUG
預定義巨集:
LINE 被編譯的檔案的行數
FILE 被編譯的檔案的名字
DATE 編譯的日期(格式”Mmm dd yyyy”)
TIME 編譯的時間(格式”hh:mm:ss”)
STDC 如果編譯器接受標準C,那麼值為1
使用帶引數的巨集替代實際的函式的優點:
1) 、 程式可能會稍微快些。一個函式呼叫在執行時通常會有些額外開銷——儲存上下文資訊、複製引數的值等。而一個巨集的呼叫則沒有這些執行開銷。
2) 、 巨集會更“通用”。與函式的引數不同,巨集的引數沒有型別。因此,只要預處理後的程式依然是合法的,巨集可以接受任何型別的引數。例如,我們可以使用MAX巨集從兩個數中選出較大的一個,數的型別可以是int,long int,float,double等等。
帶引數的巨集的一些缺點:
1) 、 編譯後的程式碼通常會變大。每一處巨集呼叫都會導致插入巨集的替換列表,由此導致程式的原始碼增加(因此編譯後的程式碼變大)。
2) 、巨集引數沒有型別檢查。當一個函式被呼叫時,編譯器會檢查每一個引數來確認它們是否是正確的型別。如果不是,或者將引數轉換成正確的型別,或者由編譯器產生一個出錯資訊。前處理器不會檢查巨集引數的型別,也不會進行型別轉換。
3) 、無法用一個指標來指向一個巨集。如在17.7節中將看到的,C語言允許指標指向函式。這一概念在特定的程式設計條件下非常有用。巨集會在預處理過程中被刪除,所以不存在類似的“指向巨集的指標”。因此,巨集不能用於處理這些情況。
4) 、巨集可能會不止一次地計算它的引數。函式對它的引數只會計算一次,而巨集可能會計算兩次甚至更多次。如果引數有副作用,多次計算引數的值可能會產生意外的結果。
#運算子
將一個巨集的引數轉換為字串字面量(字串字面量(string literal)是指雙引號引住的一系列字元,雙引號中可以沒有字元,可以只有一個字元,也可以有很多個字元)
【例項】
#define PRINT_INT(x) printf(#x " = %d\n", x)
//x之前的#運算子通知前處理器根據PRINT_INT的引數建立一個字串字面量。因此,呼叫
PRINT_INT(i/j);
//會變為
printf("i/j" " = %d\n", i/j);
//在C語言中相鄰的字串字面量會被合併,因此上邊的語句等價於:
printf("i/j = %d\n" #define STR(x) #x
int main(int argc char** argv)
{
printf("%s\n", STR(It's a long string)); //注意:並沒有雙引號,輸出 It's a long str
return 0;
}##運算子
“##”被稱為 連線符(concatenator),它是一種預處理運算子, 用來把兩個語言符號(Token)組合成單個語言符號
【例項】
#define MK_ID(n) i##n
int MK_ID(1), MK_ID(2), MK_ID(3);
//預處理後宣告變為:
int i1, i2, i3;#define GENERIC_MAX (type) \
type type##_max(type x, type y) \
{ \
return x > y ? x :y; \
}
GENERIC_MAX(float)
//展開為
float float_max(float x, float y) { return x > y ? x :y; }巨集的通用屬性:
1) 、巨集的替換列表可以包含對另一個巨集的呼叫。
2) 、前處理器只會替換完整的記號,而不會替換記號的片斷。因此,前處理器會忽略嵌在識別符號名、字元常量、字串字面量之中的巨集名。
3) 、一個巨集定義的作用範圍通常到出現這個巨集的檔案末尾。由於巨集是由前處理器處理的,他們不遵從通常的範圍規則。一個定義在函式中的巨集並不是僅在函式內起作用,而是作用到檔案末尾。
4) 、巨集不可以被定義兩遍,除非新的定義與舊的定義是一樣的。小的間隔上的差異是允許的,但是巨集的替換列表(和引數,如果有的話)中的記號都必須一致。
5) 、巨集可以使用#undef指令“取消定義”。#undef指令有如下形式:
#undef N
會刪除巨集N當前的定義。(如果N沒有被定義成一個巨集,#undef指令沒有任何作用。)#undef指令的一個用途是取消一個巨集的現有定義,以便於重新給出新的定義。
參考:C語言中的巨集定義
2、位操作(必須精通)
參考:C 位運算子 及有用位運算
3、指標操作和計算(必須精通)
4、記憶體分配(必須精通)
5、位元組對齊
滿足以下兩點個:
1) 結構體每個成員相對於結構體首地址的偏移量都是本成員大小的整數倍,如不滿足則加上填充位元組;
2) 結構體的總大小為結構體最寬的基本型別成員大小的整數倍,如不滿足則在最後加上填充字;
struct A {
int a;
char b;
short c;
}; 分析sizeof(A):
首先第一個 int 為 4 。----
其次 char 為 1,char 成員相對於首地址的偏移量為4, 4是char 本身大小 1 的整數倍,所以可以接著安置。-----
然後 short 為2,short 成員相對於首地址的偏移量為5,5不是short 本身大小 2 的整數倍,所以在填充到6。-----X--
最後計算總大小,int 4 char 1 填充 1 short 2 = 8,8是最寬int 4 的整數倍。所以後面不再填充。
參考:位元組對齊
6、sizeof必考
- sizeof 計算字串長度
char str1[20] = "0123456789";
char str2[] = "0123456789";
int a = sizeof(str1); //20 計算str1所佔的記憶體空間,以位元組為單位
int b = sizeof(str2); //11, 注意要還要加上 '\0'
int c = strlen(str1); //10, 注意 strlen 引數只能是char*, 且必須以'\0'結尾
int d = strlen(str2); //102、8、類空間大小
空類:1位元組
基類物件的儲存空間大小為:
非static資料成員的大小 + 4 個位元組(虛擬函式的儲存空間)
派生類物件的儲存空間大小為:
基類儲存空間 + 派生類特有的非static資料成員的儲存空間
虛繼承的情況下,派生類物件的儲存空間大小為:
基類的儲存空間 + 派生類特有的非static資料成員的儲存空間 + 4位元組(每一個類的虛擬函式儲存空間。)
3、sizeof 計算聯合體大小(同樣需要位元組對齊)
uniton u2
{
char a[13];
int b;
};
sizeof(u2) == 16;
//最大成員為13,但要按int的對齊方式(也就是要能整除sizeof(int) = 4,b必須放到離首地址偏移量為16的地方) 7、各類庫函式必須非常熟練的實現
8、哪些庫函式屬於高危函式,為什麼?(strcpy等等)
gets 最危險 使用 fgets(buf, size, stdin)。這幾乎總是一個大問題!
strcpy 很危險 改為使用 strncpy。
c++
一個String類的完整實現
(注意:賦值構造,operator=是關鍵)
class MyString
{
public:
//建構函式
MyString();
MyString(const MyString&);
MyString(const char*);
MyString(const size_t,const char);
//解構函式
~MyString();
//屬性
size_t length();//字串的長度
bool empty();//字串是否為空
const char* c_str();//返回C風格字串的指標
//讀寫操作符
friend ostream& operator<< (ostream&,const MyString&);
friend istream& operator>> (istream&,MyString&);
//‘+’操作符
friend MyString operator+(const MyString&,const MyString&);
//比較操作符
friend bool operator==(const MyString&,const MyString&);
friend bool operator!=(const MyString&,const MyString&);
friend bool operator<(const MyString&,const MyString&);
friend bool operator<=(const MyString&,const MyString&);
friend bool operator>(const MyString&,const MyString&);
friend bool operator>=(const MyString&,const MyString&);
//下標操作符
char& operator[] (const size_t);
const char& operator[] (const size_t)const;
//賦值操作符
MyString& operator=(const MyString&);
//'+='操作符
MyString& operator+=(const MyString&);
//子串操作
MyString substr(size_t,size_t);
//新增操作
MyString& append(const MyString&);
//插入操作
MyString& insert(size_t,const MyString&);
//替換操作
MyString& assign(const MyString&,size_t,size_t);
//刪除操作
MyString& erase(size_t,size_t);
private:
size_t strLength;
char* p_str;
};虛擬函式的作用和實現原理
(必問必考,實現原理必須很熟)
虛擬函式的作用:
可以讓成員函式操作一般化,用基類的指標指向不同的派生類的物件時, 基類指標呼叫其虛成員函式,則會呼叫其真正指向物件的成員函式,而不是基類中定義的成員函式(只要派生類改寫了該成員函式)。
實現原理:
每個類用了一個虛表,每個類的物件用了一個虛指標。
class A
{
public:
virtual void f();
virtual void g();
private:
int a;
};
class B : public A
{
public:
void g();
private:
int b;
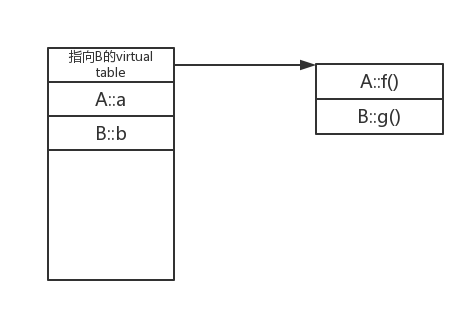
};編譯器為A類準備了一個虛表vtableA,內容如下:

B因為繼承了A,所以編譯器也為B準備了一個虛表vtableB,內容如下:

當有B bB;的時候,編譯器分配空間時,除了A的int a,B的成員int b;以外,還分配了一個虛指標vptr,指向B的虛表vtableB,bB的佈局如下:

當如下語句的時候:
A *pa = &bB;pa的結構就是A的佈局(就是說用pa只能訪問的到bB物件的前兩項,訪問不到第三項int b)
那 麼pa->g()中,編譯器知道的是,g是一個宣告為virtual的成員函式,而且其入口地址放在表格(無論是vtalbeA表還是 vtalbeB表)的第2項,那麼編譯器編譯這條語句的時候就如是轉換:call *(pa->vptr)[1](C語言的陣列索引從0開始哈~)。
這一項放的是B::g()的入口地址,則就實現了多型。(注意bB的vptr指向的是B的虛表vtableB)
sizeof一個類求大小(注意成員變數,函式,虛擬函式,繼承等等對大小的影響)
指標和引用的區別
★ 相同點:
1. 都是地址的概念;
指標指向一塊記憶體,它的內容是所指記憶體的地址;引用是某塊記憶體的別名。
★ 區別:
1. 指標是一個實體,而引用僅是個別名;
2. 引用使用時無需解引用(*),指標需要解引用;
3. 引用只能在定義時被初始化一次,之後不可變;指標可變; 引用“從一而終” ^_^
4. 引用沒有 const(int & const ref = value; 錯誤),指標有 const,const 的指標不可變;
5. 引用不能為空,指標可以為空;引用被建立的同時必須被初始化
6. “sizeof 引用”得到的是所指向的變數(物件)的大小,而“sizeof 指標”得到的是指標本身(所指向的變數或物件的地址)的大小;
typeid(T) == typeid(T&) 恆為真,sizeof(T) == sizeof(T&) 恆為真,但是當引用作為成員時,其佔用空間與指標相同(沒找到標準的規定)。
7. 指標和引用的自增(++)運算意義不一樣;
8. 不能有NULL 引用,引用必須與合法的儲存單元關聯(指標則可以是NULL)
string& rs;// 錯誤,引用必須被初始化
int const & ref = value;
const int & ref = value;
int & const ref = value; //錯誤多重類構造和析構的順序
stl各容器的實現原理
STL共有六大元件
1、容器。2、演算法。3、迭代器。4、仿函式。6、介面卡。
容器
序列式容器:
vector-陣列,元素不夠時再重新分配記憶體,拷貝原來陣列的元素到新分配的陣列中。
list-(環狀)雙向連結串列
slist-單向連結串列。
deque-
雙向佇列是一種雙向開口的連續線性空間,可以高效的在頭尾兩端插入和刪除元素
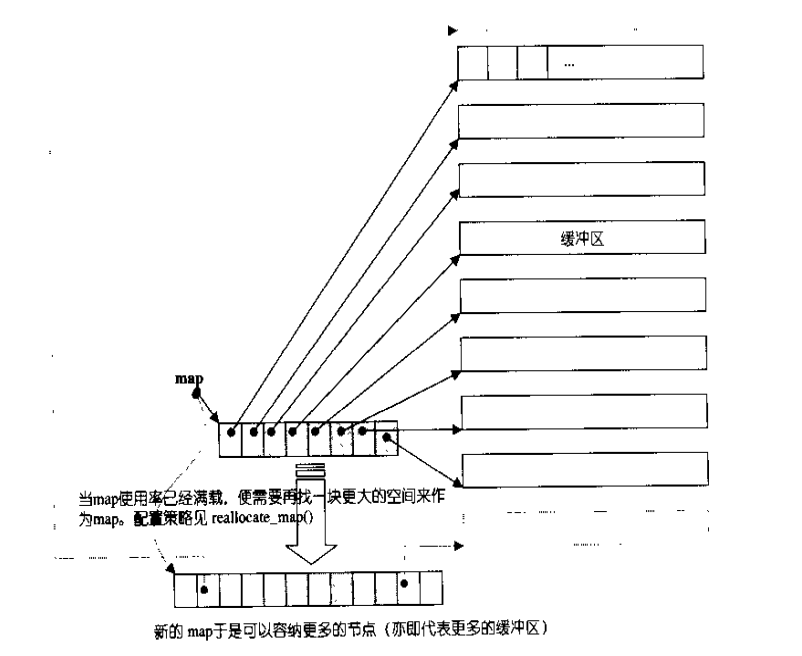
分配中央控制器map(並非map容器),map記錄著一系列的固定長度的陣列的地址.記住這個map僅僅儲存的是陣列的地址,真正的資料在陣列中存放著.deque先從map中央的位置(因為雙向佇列,前後都可以插入元素)找到一個數組地址,向該陣列中放入資料,陣列不夠時繼續在map中找空閒的陣列來存資料。當map也不夠時重新分配記憶體當作新的map,把原來map中的內容copy的新map中。所以使用deque的複雜度要大於vector,儘量使用vector。
stack-基於deque。
queue-基於deque。
heap-完全二叉樹,使用最大堆排序,以陣列(vector)的形式存放。
priority_queue-基於heap。
關聯式容器:
set,map,multiset,multimap-
基於紅黑樹(RB-tree),一種加上了額外平衡條件的二叉搜尋樹。
hash table-
散列表。將待存資料的key經過對映函式變成一個數組(一般是vector)的索引,例如:資料的key%陣列的大小=陣列的索引(一般文字通過演算法也可以轉換為數字),然後將資料當作此索引的陣列元素。有些資料的key經過演算法的轉換可能是同一個陣列的索引值(碰撞問題,可以用線性探測,二次探測來解決),STL是用開鏈的方法來解決的,每一個數組的元素維護一個list,他把相同索引值的資料存入一個list,這樣當list比較短時執行刪除,插入,搜尋等演算法比較快。
hash_map,hash_set,hash_multiset,hash_multimap
基於hash table。
演算法
,,組成。要使用 STL中的演算法函式必須包含標頭檔案,對於數值演算法須包含,中則定義了一些模板類,用來宣告函式物件。
1、查詢容器元素find
vector<int>::iterator result;
result = find( v1.begin(), v1.end(), num_to_find );2、條件查詢容器元素find_if
bool divby5(int x) //傳入的是迭代器區間[first, last)的值
{
return x%5 ? 0:1; //能被5除盡返回1,則是在迭代器區間中找能除5除盡的數
}
vector<int>::iterator ilocation;
ilocation = find_if(v.begin(),v.end(),divby5);利用返回布林值的謂詞判斷pred,檢查迭代器區間[first,last)(閉開區間)上的每一個元素,
如果迭代器i滿足pred(*i)==true,表示找到元素並返回迭代值i(找到的第一個符合條件的元素);
未找到元素,返回末位置last。
3、統計等於某值的容器元素個數count
list<int> l;
count(l.begin(),l.end(),value)4、條件統計count_if
count_if(l.begin(),l.end(),pred)5、子序列搜尋search
search演算法函式在一個序列中搜索與另一序列匹配的子序列
vector<int>::iterator ilocation;
ilocation=search(v1.begin(),v1.end(),v2.begin(),v2.end());
if(ilocation!=v1.end()) //搜尋到了【例項】
// test343.cpp : Defines the entry point for the console application.
//
#include "stdafx.h"
#include <iostream>
#include <string>
#include <vector>
#include <algorithm>
using namespace std;
int main(int argc, char* argv[])
{
string v1,v2;
cin>>v1>>v2;
string::iterator ilocation;
ilocation = search(v1.begin(),v1.end(),v2.begin(),v2.end());
if(ilocation!=v1.end())
cout<<"v2的元素包含在v1中,起始元素為"<<"v1["<<ilocation-v1.begin()<<']'<<endl;
else
cout<<"v2的元素不包含在v1中"<<endl;
return 0;
}二、變異演算法
是一組能夠修改容器元素資料的模板函式。
1、copy(v.begin(),v.end(),l.begin());將v中的元素複製到l中。
2、替換replace
replace演算法將指定元素值替換為新值。
3、隨機生成n個元素generate
函式原型:generate_n(v.begin(),5,rand);向從v.begin開始的後面5個位置隨機填寫資料。
4堆排序sort_heap
使用:
make_heap(v.begin(),v.end());
sort_heap(v.begin(),v.end());
排序sort
函式原型:sort(v.begin(),v.end());
extern c 的作用
(必須將編譯器的函式名修飾的機制解答的很透徹)
能夠正確實現C++程式碼呼叫其他C語言程式碼。加上extern “C”後,會指示編譯器這部分程式碼按C語言的進行編譯,而不是C++的。
由於C++支援函式過載,因此編譯器編譯函式的過程中會將函式的引數型別也加到編譯後的程式碼中,而不僅僅是函式名;而C語言並不支援函式過載,因此編譯C語言程式碼的函式時不會帶上函式的引數型別,一般之包括函式名。
這個功能十分有用處,因為在C++出現以前,很多程式碼都是C語言寫的,而且很底層的庫也是C語言寫的,為了更好的支援原來的C程式碼和已經寫好的C語言庫,需要在C++中儘可能的支援C,而extern “C”就是其中的一個策略。
這個功能主要用在下面的情況:
1、C++程式碼呼叫C語言程式碼
2、在C++的標頭檔案中使用
3、在多個人協同開發時,可能有的人比較擅長C語言,而有的人擅長C++,這樣的情況下也會有用到
【C/C++編譯修飾函式機制】
由於C、C++編譯器對函式的編譯處理是不完全相同的,尤其對於C++來說,支援函式的過載,編譯後的函式一般是以函式名和形參型別來命名的。
例如函式void fun(int, int),
C++語言編譯後的可能是_fun_int_int
而C語言沒有類似的過載機制,一般是利用函式名來指明編譯後的函式名的,對應上面的函式可能會是_fun這樣的名字。
#ifndef __INCvxWorksh /*防止該標頭檔案被重複引用*/
#define __INCvxWorksh
#ifdef __cplusplus //告訴編譯器,如果是cpp檔案,這部分程式碼按C語言的格式進行編譯,而不是C++的
extern "C"{
#endif
/*…*/
#ifdef __cplusplus
}
#endif
#endif /*end of __INCvxWorksh*/volatile的作用
(必須將cpu的暫存器快取機制回答的很透徹)
以volatile修飾的變數,編譯器對訪問該變數的程式碼就不再進行優化,從而可以提供對特殊地址的穩定訪問。
當要求使用 volatile 宣告的變數的值的時候,系統總是重新從它所在的記憶體讀取資料,即使它前面的指令剛剛從該處讀取過資料。而且讀取的資料立刻被儲存。
volatile int i=10;
int a = i;
...
// 其他程式碼,並未明確告訴編譯器,對 i 進行過操作
int b = i; //從新從i的位置讀取優化做法是,由於編譯器發現兩次從 i讀資料的程式碼之間的程式碼沒有對 i 進行過操作,它會自動把上次讀的資料放在 b 中。而不是重新從 i 裡面讀。
volatile用在如下的幾個地方:
1) 中斷服務程式中修改的供其它程式檢測的變數需要加volatile;
2) 多工環境下各任務間共享的標誌應該加volatile; 防止優化編譯器把變數從記憶體裝入CPU暫存器中,如果變數被裝入暫存器,那麼兩個執行緒有可能一個使用記憶體中的變數,一個使用暫存器中的變數
3) 儲存器對映的硬體暫存器通常也要加volatile說明,因為每次對它的讀寫都可能由不同意義;
static const的用法
- non-const static靜態成員變數不能在類的內部初始化
ISO C++ forbids in-class initialization of non-const static member - const成員變數也不能在類定義處初始化,只能通過建構函式初始化列表進行,並且必須有建構函式。
non-static data member initializers only available with -std=c++11
c++11允許const成員變數在類定義處初始化
class B
{
const int c_b = 9; //c++11才能通過
};
網路程式設計:
db:
mysql,會考sql語言,伺服器資料庫大規模資料怎麼設計,db各種效能指標
最後:補充一個最最重要,最最坑爹,最最有難度的一個題目:一個每秒百萬級訪問量的網際網路伺服器,每個訪問都有資料計算和I/O操作,如果讓你設計,你怎麼設計?