
LevelDB(適用於寫多讀少場景)
一、LevelDB入門
LevelDB是Google開源的持久化KV單機資料庫,具有很高的隨機寫,順序讀/寫效能,但是隨機讀的效能很一般,也就是說,LevelDB很適合應用在查詢較少,而寫很多的場景。LevelDB應用了LSM (Log Structured Merge) 策略,lsm_tree對索引變更進行延遲及批量處理,並通過一種類似於歸併排序的方式高效地將更新遷移到磁碟,降低索引插入開銷,關於LSM,本文在後面也會簡單提及。
根據Leveldb官方網站的描述,LevelDB的特點和限制如下:
特點:
1、key和value都是任意長度的位元組陣列;
2、entry(即一條K-V記錄)預設是按照key的字典順序儲存的,當然開發者也可以過載這個排序函式;
3、提供的基本操作介面:Put()、Delete()、Get()、Batch();
4、支援批量操作以原子操作進行;
5、可以建立資料全景的snapshot(快照),並允許在快照中查詢資料;
6、可以通過前向(或後向)迭代器遍歷資料(迭代器會隱含的建立一個snapshot);
7、自動使用Snappy壓縮資料;
8、可移植性;
限制:
1、非關係型資料模型(NoSQL),不支援sql語句,也不支援索引;
2、一次只允許一個程序訪問一個特定的資料庫;
3、沒有內建的C/S架構,但開發者可以使用LevelDB庫自己封裝一個server;
python 版示例
安裝依賴
pip install leveldb
?| 1234567891011121314151617181920 | python 2.7 示例<br>>>> import leveldb>>> db = leveldb.LevelDB('./db')>>> db.Put('hello', 'world')>>> print db.Get('hello')world>>> db.Delete('hello')>>> db.Get('hello')Traceback (most recent call last):File "<stdin>", line 1, in <module>KeyError>>> for i in xrange(10):... db.Put(str(i), 'string_%s' % i)...>>> print list(db.RangeIter(key_from = '2', key_to = '5'))[('2', 'string_2'), ('3', 'string_3'), ('4', 'string_4'), ('5', 'string_5')]>>> batch = leveldb.WriteBatch()>>> for i in xrange(1000):... db.Put(str(i), 'string_%s' % i)...>>> db.Write(batch, sync = True)<br><br>python 3.5 將 字串進行編碼 如 'key'.encode() ,''.decode() <br><br>用於python3 sock通訊<br> |
插入資料示例
?| 1234567 | import leveldbdb = leveldb.LevelDB('./db')batch = leveldb.WriteBatch()for i in xrange(1000000):... db.Put(str(i),'string_%s' % i)...db.Write(batch,sync=True) |
下面生成一個目錄db,裡面包含若干檔案:

然後簡要說下各個檔案的含義:
1、CURRENT
2、LOG
3、LOCK
4、MANIFEST
下圖是LevelDB執行一段時間後的儲存模型快照:記憶體中的MemTable和Immutable MemTable以及磁碟上的幾種主要檔案:Current檔案,Manifest檔案,log檔案以及SSTable檔案。當然,LevelDb除了這六個主要部分還有一些輔助的檔案,但是以上六個檔案和資料結構是LevelDb的主體構成元素。
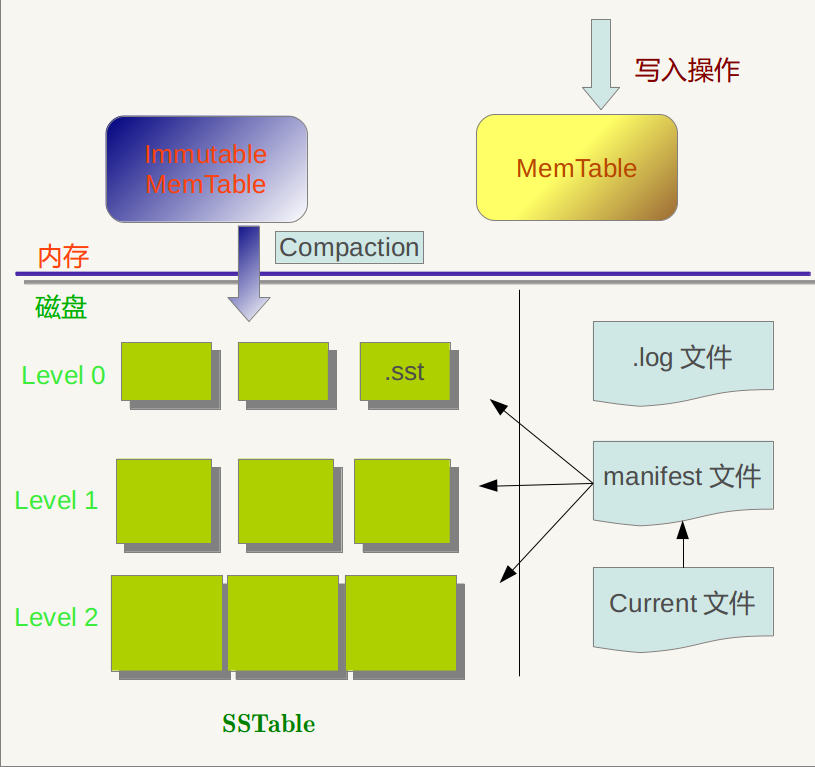
log檔案、MemTable、SSTable檔案都是用來儲存k-v記錄的,下面再說說manifest和Current檔案的作用。
SSTable中的某個檔案屬於特定層級,而且其儲存的記錄是key有序的,那麼必然有檔案中的最小key和最大key,這是非常重要的資訊,Manifest 就記載了SSTable各個檔案的管理資訊,比如屬於哪個Level,檔名稱叫啥,最小key和最大key各自是多少。下圖是Manifest所儲存內容的示意:

另外,在LevleDb的執行過程中,隨著Compaction的進行,SSTable檔案會發生變化,會有新的檔案產生,老的檔案被廢棄,Manifest也會跟著反映這種變化,此時往往會新生成Manifest檔案來記載這種變化,而Current則用來指出哪個Manifest檔案才是我們關心的那個Manifest檔案。
二、讀寫資料

寫操作流程:
1、順序寫入磁碟log檔案;
2、寫入記憶體memtable(採用skiplist結構實現);
3、寫入磁碟SST檔案(sorted string table files),這步是資料歸檔的過程(永久化儲存);
注意:
- log檔案的作用是是用於系統崩潰恢復而不丟失資料,假如沒有Log檔案,因為寫入的記錄剛開始是儲存在記憶體中的,此時如果系統崩潰,記憶體中的資料還沒有來得及Dump到磁碟,所以會丟失資料;
- 在寫memtable時,如果其達到check point(滿員)的話,會將其改成immutable memtable(只讀),然後等待dump到磁碟SST檔案中,此時也會生成新的memtable供寫入新資料;
- memtable和sst檔案中的key都是有序的,log檔案的key是無序的;
- LevelDB刪除操作也是插入,只是標記Key為刪除狀態,真正的刪除要到Compaction的時候才去做真正的操作;
- LevelDB沒有更新介面,如果需要更新某個Key的值,只需要插入一條新紀錄即可;或者先刪除舊記錄,再插入也可;
讀操作流程:
1、在記憶體中依次查詢memtable、immutable memtable;
2、如果配置了cache,查詢cache;
3、根據mainfest索引檔案,在磁碟中查詢SST檔案;

舉個例子:我們先往levelDb裡面插入一條資料 {key="www.samecity.com" value="我們"},過了幾天,samecity網站改名為:69同城,此時我們插入資料{key="www.samecity.com" value="69同城"},同樣的key,不同的value;邏輯上理解好像levelDb中只有一個儲存記錄,即第二個記錄,但是在levelDb中很可能存在兩條記錄,即上面的兩個記錄都在levelDb中儲存了,此時如果使用者查詢key="www.samecity.com",我們當然希望找到最新的更新記錄,也就是第二個記錄返回,因此,查詢的順序應該依照資料更新的新鮮度來,對於SSTable檔案來說,如果同時在level L和Level L+1找到同一個key,level L的資訊一定比level L+1的要新。
三、SSTable檔案
SST檔案並不是平坦的結構,而是分層組織的,這也是LevelDB名稱的來源。
SST檔案的一些實現細節:
1、每個SST檔案大小上限為2MB,所以,LevelDB通常儲存了大量的SST檔案;
2、SST檔案由若干個4K大小的blocks組成,block也是讀/寫操作的最小單元;
3、SST檔案的最後一個block是一個index,指向每個data block的起始位置,以及每個block第一個entry的key值(block內的key有序儲存);
4、使用Bloom filter加速查詢,只要掃描index,就可以快速找出所有可能包含指定entry的block。
5、同一個block內的key可以共享字首(只儲存一次),這樣每個key只要儲存自己唯一的字尾就行了。如果block中只有部分key需要共享字首,在這部分key與其它key之間插入"reset"標識。
由log直接讀取的entry會寫到Level 0的SST中(最多4個檔案);
當Level 0的4個檔案都儲存滿了,會選擇其中一個檔案Compact到Level 1的SST中;
注意:Level 0的SSTable檔案和其它Level的檔案相比有特殊性:這個層級內的.sst檔案,兩個檔案可能存在key重疊,比如有兩個level 0的sst檔案,檔案A和檔案B,檔案A的key範圍是:{bar, car},檔案B的Key範圍是{blue,samecity},那麼很可能兩個檔案都存在key=”blood”的記錄。對於其它Level的SSTable檔案來說,則不會出現同一層級內.sst檔案的key重疊現象,就是說Level L中任意兩個.sst檔案,那麼可以保證它們的key值是不會重疊的。
Log:最大4MB (可配置), 會寫入Level 0;
Level 0:最多4個SST檔案,;
Level 1:總大小不超過10MB;
Level 2:總大小不超過100MB;
Level 3+:總大小不超過上一個Level ×10的大小。
比如:0 ↠ 4 SST, 1 ↠ 10M, 2 ↠ 100M, 3 ↠ 1G, 4 ↠ 10G, 5 ↠ 100G, 6 ↠ 1T, 7 ↠ 10T
在讀操作中,要查詢一條entry,先查詢log,如果沒有找到,然後在Level 0中查詢,如果還是沒有找到,再依次往更底層的Level順序查詢;如果查找了一條不存在的entry,則要遍歷一遍所有的Level才能返回"Not Found"的結果。
在寫操作中,新資料總是先插入開頭的幾個Level中,開頭的這幾個Level儲存量也比較小,因此,對某條entry的修改或刪除操作帶來的效能影響就比較可控。
可見,SST採取分層結構是為了最大限度減小插入新entry時的開銷;
Compaction操作
對於LevelDb來說,寫入記錄操作很簡單,刪除記錄僅僅寫入一個刪除標記就算完事,但是讀取記錄比較複雜,需要在記憶體以及各個層級檔案中依照新鮮程度依次查詢,代價很高。為了加快讀取速度,levelDb採取了compaction的方式來對已有的記錄進行整理壓縮,通過這種方式,來刪除掉一些不再有效的KV資料,減小資料規模,減少檔案數量等。
LevelDb的compaction機制和過程與Bigtable所講述的是基本一致的,Bigtable中講到三種類型的compaction: minor ,major和full:
- minor Compaction,就是把memtable中的資料匯出到SSTable檔案中;
- major compaction就是合併不同層級的SSTable檔案;
- full compaction就是將所有SSTable進行合併;
LevelDb包含其中兩種,minor和major。
Minor compaction 的目的是當記憶體中的memtable大小到了一定值時,將內容儲存到磁碟檔案中,如下圖:

immutable memtable其實是一個SkipList,其中的記錄是根據key有序排列的,遍歷key並依次寫入一個level 0 的新建SSTable檔案中,寫完後建立檔案的index 資料,這樣就完成了一次minor compaction。從圖中也可以看出,對於被刪除的記錄,在minor compaction過程中並不真正刪除這個記錄,原因也很簡單,這裡只知道要刪掉key記錄,但是這個KV資料在哪裡?那需要複雜的查詢,所以在minor compaction的時候並不做刪除,只是將這個key作為一個記錄寫入檔案中,至於真正的刪除操作,在以後更高層級的compaction中會去做。
當某個level下的SSTable檔案數目超過一定設定值後,levelDb會從這個level的SSTable中選擇一個檔案(level>0),將其和高一層級的level+1的SSTable檔案合併,這就是major compaction。
我們知道在大於0的層級中,每個SSTable檔案內的Key都是由小到大有序儲存的,而且不同檔案之間的key範圍(檔案內最小key和最大key之間)不會有任何重疊。Level 0的SSTable檔案有些特殊,儘管每個檔案也是根據Key由小到大排列,但是因為level 0的檔案是通過minor compaction直接生成的,所以任意兩個level 0下的兩個sstable檔案可能再key範圍上有重疊。所以在做major compaction的時候,對於大於level 0的層級,選擇其中一個檔案就行,但是對於level 0來說,指定某個檔案後,本level中很可能有其他SSTable檔案的key範圍和這個檔案有重疊,這種情況下,要找出所有有重疊的檔案和level 1的檔案進行合併,即level 0在進行檔案選擇的時候,可能會有多個檔案參與major compaction。
LevelDb在選定某個level進行compaction後,還要選擇是具體哪個檔案要進行compaction,比如這次是檔案A進行compaction,那麼下次就是在key range上緊挨著檔案A的檔案B進行compaction,這樣每個檔案都會有機會輪流和高層的level 檔案進行合併。
如果選好了level L的檔案A和level L+1層的檔案進行合併,那麼問題又來了,應該選擇level L+1哪些檔案進行合併?levelDb選擇L+1層中和檔案A在key range上有重疊的所有檔案來和檔案A進行合併。也就是說,選定了level L的檔案A,之後在level L+1中找到了所有需要合併的檔案B,C,D…..等等。剩下的問題就是具體是如何進行major 合併的?就是說給定了一系列檔案,每個檔案內部是key有序的,如何對這些檔案進行合併,使得新生成的檔案仍然Key有序,同時拋掉哪些不再有價值的KV 資料。
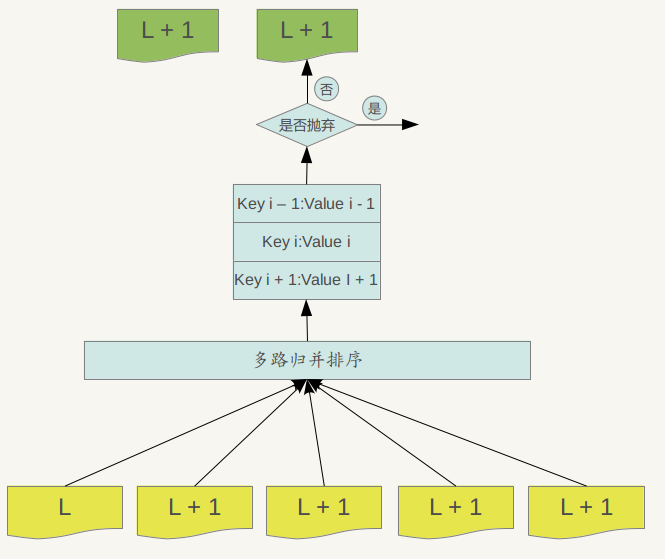
Major compaction的過程如下:對多個檔案採用多路歸併排序的方式,依次找出其中最小的Key記錄,也就是對多個檔案中的所有記錄重新進行排序。之後採取一定的標準判斷這個Key是否還需要儲存,如果判斷沒有儲存價值,那麼直接拋掉,如果覺得還需要繼續儲存,那麼就將其寫入level L+1層中新生成的一個SSTable檔案中。就這樣對KV資料一一處理,形成了一系列新的L+1層資料檔案,之前的L層檔案和L+1層參與compaction 的檔案資料此時已經沒有意義了,所以全部刪除。這樣就完成了L層和L+1層檔案記錄的合併過程。
那麼在major compaction過程中,判斷一個KV記錄是否拋棄的標準是什麼呢?其中一個標準是:對於某個key來說,如果在小於L層中存在這個Key,那麼這個KV在major compaction過程中可以拋掉。因為我們前面分析過,對於層級低於L的檔案中如果存在同一Key的記錄,那麼說明對於Key來說,有更新鮮的Value存在,那麼過去的Value就等於沒有意義了,所以可以刪除。
四、Cache
前面講過對於levelDb來說,讀取操作如果沒有在記憶體的memtable中找到記錄,要多次進行磁碟訪問操作。假設最優情況,即第一次就在level 0中最新的檔案中找到了這個key,那麼也需要讀取2次磁碟,一次是將SSTable的檔案中的index部分讀入記憶體,這樣根據這個index可以確定key是在哪個block中儲存;第二次是讀入這個block的內容,然後在記憶體中查詢key對應的value。
LevelDb中引入了兩個不同的Cache:Table Cache和Block Cache。其中Block Cache是配置可選的,即在配置檔案中指定是否開啟這個功能。
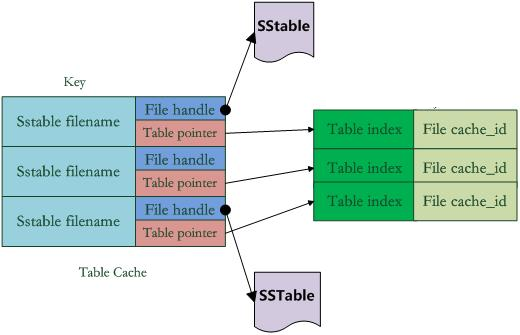
如上圖,在Table Cache中,key值是SSTable的檔名稱,Value部分包含兩部分,一個是指向磁碟開啟的SSTable檔案的檔案指標,這是為了方便讀取內容;另外一個是指向記憶體中這個SSTable檔案對應的Table結構指標,table結構在記憶體中,儲存了SSTable的index內容以及用來指示block cache用的cache_id ,當然除此外還有其它一些內容。
比如在get(key)讀取操作中,如果levelDb確定了key在某個level下某個檔案A的key range範圍內,那麼需要判斷是不是檔案A真的包含這個KV。此時,levelDb會首先查詢Table Cache,看這個檔案是否在快取裡,如果找到了,那麼根據index部分就可以查詢是哪個block包含這個key。如果沒有在快取中找到檔案,那麼開啟SSTable檔案,將其index部分讀入記憶體,然後插入Cache裡面,去index裡面定位哪個block包含這個Key 。如果確定了檔案哪個block包含這個key,那麼需要讀入block內容,這是第二次讀取。
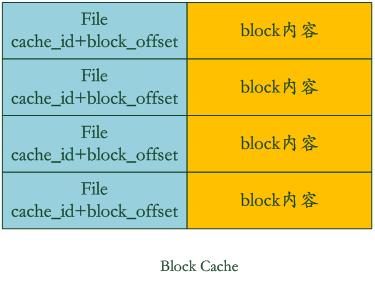
Block Cache是為了加快這個過程的,其中的key是檔案的cache_id加上這個block在檔案中的起始位置block_offset。而value則是這個Block的內容。
如果levelDb發現這個block在block cache中,那麼可以避免讀取資料,直接在cache裡的block內容裡面查詢key的value就行,如果沒找到呢?那麼讀入block內容並把它插入block cache中。levelDb就是這樣通過兩個cache來加快讀取速度的。從這裡可以看出,如果讀取的資料區域性性比較好,也就是說要讀的資料大部分在cache裡面都能讀到,那麼讀取效率應該還是很高的,而如果是對key進行順序讀取效率也應該不錯,因為一次讀入後可以多次被複用。但是如果是隨機讀取,您可以推斷下其效率如何。
五、版本控制
在Leveldb中,Version就代表了一個版本,它包括當前磁碟及記憶體中的所有檔案資訊。在所有的version中,只有一個是CURRENT(當前版本),其它都是歷史版本。
當執行一次compaction 或者 建立一個Iterator後,Leveldb將在當前版本基礎上建立一個新版本,當前版本就變成了歷史版本。
VersionSet 是所有Version的集合,管理著所有存活的Version。
VersionEdit 表示Version之間的變化,相當於delta 增量,表示有增加了多少檔案,刪除了檔案:
Version0 + VersionEdit --> Version1 Version0->Version1->Version2->Version3
VersionEdit會儲存到MANIFEST檔案中,當做資料恢復時就會從MANIFEST檔案中讀出來重建資料。
Leveldb的這種版本的控制,讓我想到了雙buffer切換,雙buffer切換來自於圖形學中,用於解決螢幕繪製時的閃屏問題,在伺服器程式設計中也有用處。
比如我們的伺服器上有一個字典庫,每天我們需要更新這個字典庫,我們可以新開一個buffer,將新的字典庫載入到這個新buffer中,等到載入完畢,將字典的指標指向新的字典庫。
Leveldb的version管理和雙buffer切換類似,但是如果原version被某個iterator引用,那麼這個version會一直保持,直到沒有被任何一個iterator引用,此時就可以刪除這個version。
學習參看
http://blog.csdn.net/qq112928/article/details/21172841
http://www.cnblogs.com/chenny7/p/4026447.html
http://www.cnblogs.com/haippy/archive/2011/12/04/2276064.html