
Spark常用函式講解之鍵值RDD轉換
| 1 2 3 4 5 6 7 8 9 10 |
object
MapValues {
def
main(args: Array[String]) {
val
conf = new SparkConf().setMaster("local").setAppName("map")
val
sc = new SparkContext(conf)val
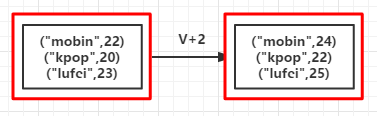
list = List(("mobin",22),("kpop",20),("lufei",23))
val
rdd = sc.parallelize(list)
val
mapValuesRDD = rdd.mapValues(_+2)
mapValuesRDD.foreach(println)
}
}
|
(mobin,24) (kpop,22) (lufei,25)(RDD依賴圖:紅色塊表示一個RDD區,黑色塊表示該分割槽集合,下同)

 2.flatMapValues(fun):對[K,V]型資料中的V值flatmap操作
(例2):
2.flatMapValues(fun):對[K,V]型資料中的V值flatmap操作
(例2):
| 1 2 3 4 |
//省略<br>val
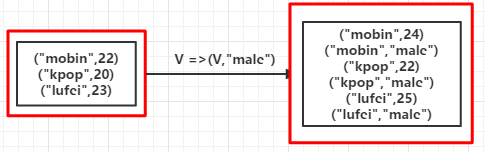
list = List(("mobin",22),("kpop",20),("lufei",23))
val
rdd = sc.parallelize(list)
val
mapValuesRDD = rdd.flatMapValues(x => Seq(x,"male"))
mapValuesRDD.foreach(println) |
(mobin,22) (mobin,male) (kpop,20) (kpop,male) (lufei,23) (lufei,male)如果是mapValues會輸出:
(mobin,List(22, male)) (kpop,List(20, male)) (lufei,List(23, male))(RDD依賴圖)

 3.comineByKey(createCombiner,mergeValue,mergeCombiners,partitioner,mapSideCombine)
comineByKey(createCombiner,mergeValue,mergeCombiners,numPartitions)
comineByKey(createCombiner,mergeValue,mergeCombiners)
createCombiner:在第一次遇到Key時建立組合器函式,將RDD資料集中的V型別值轉換C型別值(V => C),
如例3:
3.comineByKey(createCombiner,mergeValue,mergeCombiners,partitioner,mapSideCombine)
comineByKey(createCombiner,mergeValue,mergeCombiners,numPartitions)
comineByKey(createCombiner,mergeValue,mergeCombiners)
createCombiner:在第一次遇到Key時建立組合器函式,將RDD資料集中的V型別值轉換C型別值(V => C),
如例3:
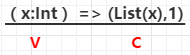
 mergeValue:合併值函式,再次遇到相同的Key時,將createCombiner道理的C型別值與這次傳入的V型別值合併成一個C型別值(C,V)=>C,
如例3:
mergeValue:合併值函式,再次遇到相同的Key時,將createCombiner道理的C型別值與這次傳入的V型別值合併成一個C型別值(C,V)=>C,
如例3:

 mergeCombiners:合併組合器函式,將C型別值兩兩合併成一個C型別值
如例3:
mergeCombiners:合併組合器函式,將C型別值兩兩合併成一個C型別值
如例3:

 partitioner:使用已有的或自定義的分割槽函式,預設是HashPartitioner
mapSideCombine:是否在map端進行Combine操作,預設為true
注意前三個函式的引數型別要對應;第一次遇到Key時呼叫createCombiner,再次遇到相同的Key時呼叫mergeValue合併值
(例3):統計男性和女生的個數,並以(性別,(名字,名字....),個數)的形式輸出
partitioner:使用已有的或自定義的分割槽函式,預設是HashPartitioner
mapSideCombine:是否在map端進行Combine操作,預設為true
注意前三個函式的引數型別要對應;第一次遇到Key時呼叫createCombiner,再次遇到相同的Key時呼叫mergeValue合併值
(例3):統計男性和女生的個數,並以(性別,(名字,名字....),個數)的形式輸出
1
2
3
4
5
相關推薦Spark常用函式講解之鍵值RDD轉換本節所講函式 1.mapValus(fun):對[K,V]型資料中的V值map操作 (例1):對每個的的年齡加2 1 2 3 4 5 6 7 8 9 Spark常用函式之鍵值RDD轉換+例項RDD:彈性分散式資料集,是一種特殊集合 ‚ 支援多種來源 ‚ 有容錯機制 ‚ 可以被快取 ‚ 支援並行操作,一個RDD代表一個分割槽裡的資料集RDD有兩種操作運算元: Transformatio Spark常用函式講解之Action操作+例項RDD:彈性分散式資料集,是一種特殊集合 ‚ 支援多種來源 ‚ 有容錯機制 ‚ 可以被快取 ‚ 支援並行操作,一個RDD代表一個分割槽裡的資料集RDD有兩種操作運算元: Transformatio Spark運算元:transformation之鍵值轉換groupByKey、reduceByKey、reduceByKeyLocally1、groupByKey 1)def groupByKey(): RDD[(K, Iterable[V])] 2)def groupByKey(numPartitions: Int): RDD[(K, Iterable[V])] 3)def groupByKey(parti Spark運算元:transformation之鍵值轉換combineByKey、foldByKey1、combineByKey 1)def combineByKey[C](createCombiner: (V) => C, mergeValue: (C, V) => C, mergeCombiners: (C, C) => C): RDD[(K, C) Spark運算元:transformation之鍵值轉換join、cogroup1、join 1)def join[W](other: RDD[(K, W)]): RDD[(K, (V, W))] 2)def join[W](other: RDD[(K, W)], numPartitions: Int): RDD[(K, (V, W))] 3)def Spark運算元:transformation之鍵值轉換partitionBy、mapValues、flatMapValues1、partitionBy:def partitionBy(partitioner: Partitioner): RDD[(K, V)] 該函式根據partitioner函式生成新的ShuffleRDD,將原RDD重新分割槽。 scala> var rdd1 = sc.makeRDD( Spark運算元:transformation之鍵值轉換leftOuterJoin、rightOuterJoin、subtractByKey1、leftOuterJoin 1)def leftOuterJoin[W](other: RDD[(K, W)]): RDD[(K, (V, Option[W]))] 2)def leftOuterJoin[W](other: RDD[(K, W)], numPartitions: Int): 6.spark core之鍵值對操作方式 lines () end 結果 字符 額外 creat 很多 鍵值對RDD(pair RDD)是spark中許多操作所需要的常見數據類型,通常用來進行聚合計算。 創建Pair RDD ??spark有多種方式可以創建pair RDD。比如:很多存儲鍵值對的數據格式在讀 Spark之鍵值對操作-Java篇(三)一、簡介 鍵值對 RDD 是 Spark 中許多操作所需要的常見資料型別。本章就來介紹如何操作鍵值對 RDD。鍵值對 RDD 通常用來進行聚合計算。我們一般要先通過一些初始 ETL(抽取、轉 化、裝載)操作來將資料轉化為鍵值對形式。鍵值對 RDD 提供了一些新的操作介面( redis常用命令及高階應用之鍵值的相關命令keys 返回滿足給定pattern的所有key 例如:返回所有鍵 127.0.0.1:6379> keys * 1) "list3" 2) "myset5" 3) "list6" 4) "myset2" 5) "sset2" 6) Spark學習筆記3:鍵值對操作對象 常用 ava java 參數 通過 頁面 ascend 處理過程 鍵值對RDD通常用來進行聚合計算,Spark為包含鍵值對類型的RDD提供了一些專有的操作。這些RDD被稱為pair RDD。pair RDD提供了並行操作各個鍵或跨節點重新進行數據分組的操作接口。 Sp 2.Spark常用運算元講解 (z轉)2.Spark常用運算元講解 2017年03月15日 16:50:45 dream0352 閱讀數:16141 標籤: SparkSpark常用運算元spark運算元Spark運算元講解 更多 個人分類: spark S redis常用操作和操作鍵值string、list常用操作 string資料建立、覆蓋及設定過期時間 127.0.0.1:6379> get key1 檢視原來的key1的值 "b" 127.0.0.1:6379> set key1 123 &nbs Go工作中用到的包和常用函式講解func main() { m := map[string]interface{}{"UserId": "2"} s := CreateToken("8QOihWUl9uD5W4kI", m) fmt.Println(s) token := "eyJh spark 常用函式總結1, textFile() 讀取外部資料來源 2, map() 對每一條資料進行相應的處理 如切分 3, reduceByKey(_+_) 傳入一個函式,將key相同的一類進行聚合計算 如相加 4, mapvalues(_+10) 傳入一個函式,類似於map方法,不過這裡 STL常用函式複習之————list//list雙向連結串列容器 前驅元素指標域+資料域+後繼元素指標域 /*list的頭結點的前驅元素指標域儲存的是連結串列中尾節點的首地址 list的尾節點的後繼元素指標域儲存的是連結串列中頭 spark 常用函式介紹(python)全棧工程師開發手冊 (作者:欒鵬) 獲取SparkContext python語法 1. 獲取sparkSession: se = SparkSession.builder.config(conf = SparkConf()).getOrCreate() spark常用函式:transformation和action1、RDD提供了兩種型別的操作:transformation和action 所有的transformation都是採用的懶策略,如果只是將transformation提交是不會執行計算的,計算只有在action被提交的時候才被觸發。 1)transformation操作:得 pandas資料處理常用函式demo之建立/行列操作/檢視/檔案操作pandas是Python下強大的資料分析工具,這篇文章程式碼主要來自於 10 Minutes to pandas,我將示例程式碼進行了重跑和修改,基本可以滿足所有操作,但是使用更高階的功能可以達到事半功倍的效果:原文如下: http://pandas.py |