
1-2、Spark的standalone模式安裝
提前安裝好hadoop,
我準備了兩個節點,jdk和hadoop先安裝好。
我用的兩個節點,電腦配置不行,3個節點演示能更好些
1、解壓
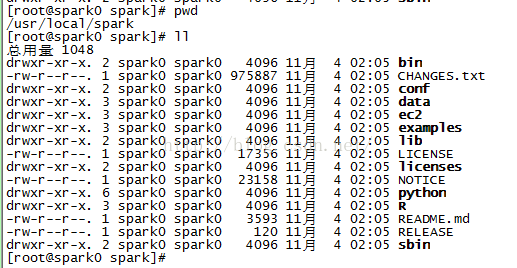
2、編輯檔案:
[[email protected] conf]# cpspark-env.sh.template spark-env.sh
[[email protected] conf]# vim spark-env.sh
SPARK_MASTER_IP=192.168.6.2
[[email protected] conf]# cp slaves.templateslaves
[[email protected] 3、配置好的拷貝到另一個幾點上面去:
[[email protected] local]# scp -r sparkspark1:/usr/local/
4、檢視主節點的程序,除了worker還有master
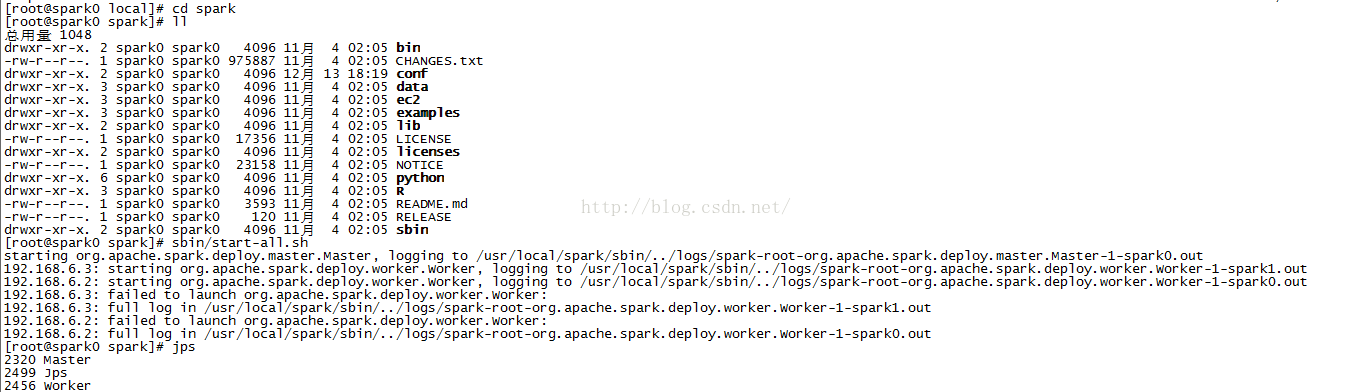
5、檢視另一個節點,除了hadoop程序,只有worker,沒有master程序

6、例子,先在本地設定一個檔案

7、開啟spark-shell,執行一個小例子:
scala> val rdd=sc.textFile("/home/spark0/spark.txt").collect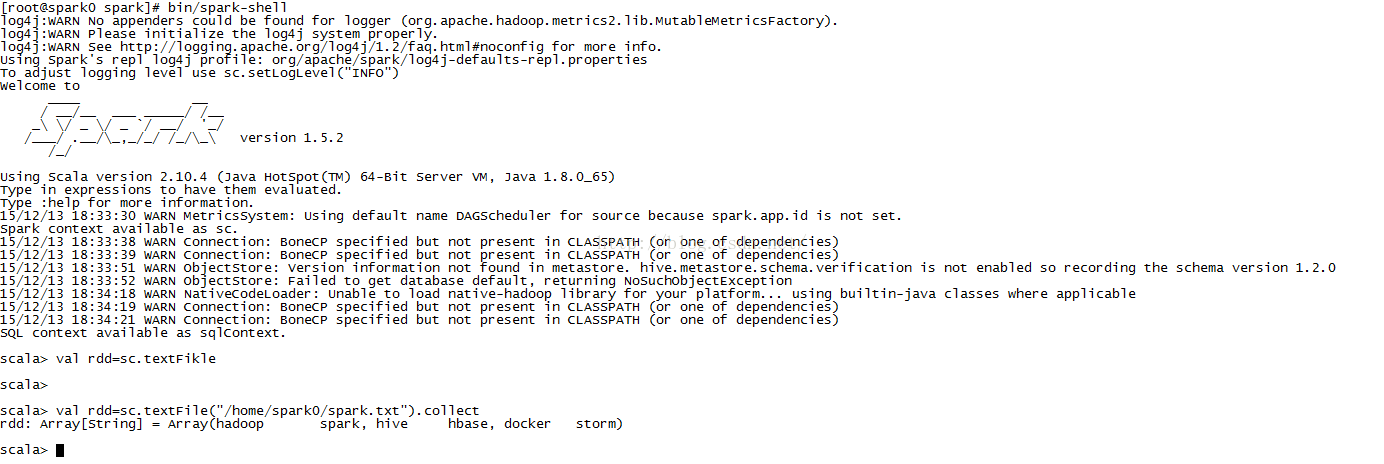
8、關閉,兩個節點的spark叢集:

相關推薦
1.2、CentOS 7 安裝 Docker
Docker 安裝 1、CentOS 7 安裝 Docker CE 官網:https://docs.docker.com/install/linux/docker-ce/centos/ Docker支援以下的CentOS版本: CentOS 7 (64-bit) C
1-2、Spark的standalone模式安裝
提前安裝好hadoop, 我準備了兩個節點,jdk和hadoop先安裝好。 我用的兩個節點,電腦配置不行,3個節點演示能更好些 1、解壓 2、編輯檔案: [[email protected] conf]# cpspark-env.sh.templa
DevExpress14.1.2 xe XE6 高速安裝
ng- -a 壓縮 編譯安裝 沒有 dev 網上 .com -m 之前在在網上下載的DevExpress14.1.2 xe-XE6都是一個個包文件。須要一個個去查找編譯安裝,並且須要有一定的順序要求。 所下面載了好久了都沒有安裝。 近期在網上找了個舊版的安裝方法
1.2、Java“白皮書”的關鍵術語
能夠 頭文件 其中 高性能 交互 容易出錯 接口 多重 編程語言 Java“白皮書”的關鍵術語 1、簡單性 為了便於系統更易於理解,Java在設計的時候盡量可能地接近C++,但是Java提出了C++中許多很少使用、難以理解、易混淆的特性。可以說Java語法是C++語
14.2、centos系統安裝
boot lin inux 安裝過程 窗口 res naconda 一個 linu 1、anaconda(安裝linux的工具) anaconda的界面: tui:基於cureses的文本配置窗口 gui:圖形界面2、centos的安裝過程啟動流程介紹:
搭建LAMP架構— 2、手工編譯安裝MySQL
Linux MySQL 數據庫 Redhat 在上一篇文檔中,我們介紹了手工編譯安裝APache,本次,讓我們繼續完成MySQL的手工編譯安裝。 MySQL數據庫是C/S架構的,既有客戶端又有服務器端,MySQL客戶端的安裝非常簡單,上一篇文檔中已經向大家分享了LAMP架構的所有軟件包,我們只
2、ubuntu16.06安裝Hi3518EV200 SDK
5.0 x86 sdk linux工具 glib 解決 是我 4.4 util HI3518EV200 SDK安裝並編譯osdr。 1、開發環境 windows10電腦 + 虛擬機14 Pro + Ubuntu16.0.4 2、拷貝並解壓。將 Hi3518E_SDK_V
2、Docker 基礎安裝和基礎使用
tab ant 如果 eve creat nes earch mage containe 基礎環境 本次環境使用Centos 7.x版本系統,最小化安裝,系統基礎優化配置請查看 Centos 7.x 系統基礎優化 安裝 使用命令:yum install docker-io
2、CentOS6.5 安裝Open×××使用easy-rsa3.0.3
心跳 重新啟動 config 8.0 def 互訪 tap tables issue 1、安裝eple源yum install -y epel-releasesed -i ‘s/mirrorlist=https/mirrorlist=http/g‘ /etc/yum.rep
[Python3網絡爬蟲開發實戰] 1.2.4-GeckoDriver的安裝
直接 pre wid selenium 都沒有 arm The file 驅動 上一節中,我們了解了ChromeDriver的配置方法,配置完成之後便可以用Selenium驅動Chrome瀏覽器來做相應網頁的抓取。 那麽對於Firefox來說,也可以使用同樣的方式完成Sel
[Python3網絡爬蟲開發實戰] 1.2.3-ChromeDriver的安裝
strip data- exe mona them 版本不兼容 .profile title 範圍 前面我們成功安裝好了Selenium庫,但是它是一個自動化測試工具,需要瀏覽器來配合使用,本節中我們就介紹一下Chrome瀏覽器及ChromeDriver驅動的配置。 首先,
libusb-win32-bin-1.2.6.0驅動安裝方法
本驅動是Windows系統下(包含主流的Windows XP, Windows7)下的驅動,官方網址為,http://sourceforge.net/apps/trac/libusb-win32/wiki,裡面可以找到libusb-win32的介紹,在該網頁找到download,進入http://s
2、oracle的安裝
學習目標: 1、掌握在window環境下Oracle資料庫軟體的安裝 2、掌握Oracle的客戶端連結工具的使用 學習過程: 要學習Oracle資料庫,那麼我們還是先在系統上安裝了Oralce。我們可以免費下載進行學習。 一、下載安裝檔案 到oracle的官方網站下載即可:h
qwt 6.1.2的編譯與安裝
一、前提 已經安裝了Qt,並已配置好其環境變數;筆者安裝的Qt版本為Qt-4.8.6。 二、下載原始碼 地址:http://sourceforge.net/projects/qwt/files/qwt/6.1.2/ 對於windows環境下的安裝,下載zip檔案,解壓到自定義
珠峰js筆記1.2(原型鏈模式)
{ 單例模式 物件資料型別的作用: 把描述同一個事物的屬性和方法放在一個記憶體空間下,起到了分組的作用,這樣不同事物之間的屬性即使屬性名相同,相互也不會發生衝突 -> 我們把這種分組編寫程式碼的模式叫做 “單例模式” -> 在單例模式中我們把 person1 叫做 “名稱空間
Atitit 檔案上傳功能的實現 圖片 視訊 目錄 1. 上傳原理 1 1.1. http post編碼 multipart / form-data 1 1.2. 臨時檔案模式 最簡單 2 1.3
Atitit 檔案上傳功能的實現 圖片 視訊 目錄 1. 上傳原理 1 1.1. http post編碼 multipart / form-data 1 1.2. 臨時檔案模式 最簡單 2 1.3. 位元組陣列模式 簡單 2
2、阿里雲安裝mysql過程
阿里雲centos7安裝mysql,廢話不多說直接擼程式碼: 一、安裝mysql 1、下載RPM wget https://repo.mysql.com//mysql80-community-release-el7-1.noarch.rpm 2、安裝RPM包 rpm -iv
2、Ubuntu下安裝nginx
一、系統環境安裝 1.1、 gcc 安裝 安裝 nginx 需要先將官網下載的原始碼進行編譯,編譯依賴 gcc 環境,如果沒有 gcc 環境,則需要安裝: sudo apt-get install build-essential
Windows安裝教程(Microsoft官方工具安裝+PE安裝教程,以及GPT分割槽、UEFI模式安裝win7教程)
本文主要介紹兩種Windows安裝方法、以及如何在GPT分割槽、UEFI模式中安裝win7 兩種方法各有優缺點。 第一種方便,PE裡面很多功能,你的電腦出了什麼毛病基本上都能通過PE解決。而且能安裝各個版本的windows。但是過程繁瑣,而且動手能力強。不適
基礎教程:2、Linux伺服器安裝圖解
2.1 Linux發行版選擇 Linux是一類開放原始碼和自由的類似Unix的作業系統,有眾多發行版本。在伺服器市場,Linux作業系統佔有絕對的優勢。Linux作業系統大致可以分為Redhat系列和Debian系列。 Redhat系列中典型代表是RHEL(Redhat