
Wide& Deep
-
排序系統的發展:
-
LR-->GBDT+LR
-
FM-->FFM-->GBDT+FM|FFM
-
FTRL-->GBDT+FTRL
-
Wide&DeepModel
-
Deep Neural Networks for YouTube Recommendations
-
Reinforce Learning
-
Wide and deep 模型是 TensorFlow 在 2016 年 6 月左右釋出的一類用於分類和迴歸的模型,並應用到了 Google Play 的應用推薦中 [1]。wide and deep 模型的核心思想是結合線性模型的記憶能力(memorization)和 DNN 模型的泛化能力(generalization),在訓練過程中同時優化 2 個模型的引數,從而達到整體模型的預測能力最優。論文見 Wide & Deep Learning for Recommender Systems。
-
記憶(memorization) 通過特徵叉乘對原始特徵做非線性變換,輸入為高維度的稀疏向量。通過大量的特徵叉乘產生特徵相互作用的“記憶(Memorization)”,高效且可解釋,但要泛化需要更多的特徵工程。
-
泛化(generalization)只需要少量的特徵工程,深度神經網路通過embedding的方法,使用低維稠密特徵輸入,可以更好地泛化訓練樣本中未出現過的特徵組合。但當user-item互動矩陣稀疏且高階時,容易出現“過泛化(over-generalize)”導致推薦的item相關性差。
-
在推薦場景中是相關性和多樣性的融合。
-
Wide & Deep的模型結構:
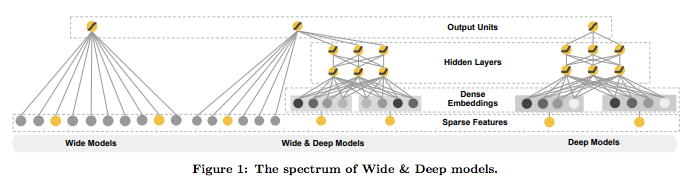
wide and deep模型中使用的特徵包括兩大類: 一類是連續型特徵,主要用於deep模型的訓練,包括real value型別的特徵以及embedding型別的特徵等;一類是離散型特徵,主要用於wide模型的訓練,包括sparse型別的特徵以及cross型別的特徵等。
-
W&D的特徵包括三方面: User-Feature:contry, language, demographics. Contextual-Feature:device, hour of the day, day of the week. Impression-Feature:app age, historical statistics of an app. 2.1)Wide部分的輸入特徵: raw input features and transformed features [手挑的交叉特徵]. notice: W&D這裡的cross-product transformation: 只在離散特徵之間做組合,不管是文字策略型的,還是離散值的;沒有連續值特徵的啥事,至少在W&D的paper裡面是這樣使用的。 2.2)Deep部分的輸入特徵: raw input+embeding處理 對非連續值之外的特徵做embedding處理,這裡都是策略特徵,就是乘以個embedding-matrix。在TensorFlow裡面的介面是:tf.feature_column.embedding_column,預設trainable=True. 對連續值特徵的處理是:將其按照累積分佈函式P(X≤x),壓縮至[0,1]內。 notice1: Wide部分用FTRL+L1來訓練;Deep部分用AdaGrad來訓練。 使用BP演算法採用joint train的方式訓練。
notice2特徵工程部分:1)連續特徵歸一化。2)離散特徵去掉出現次數過少的特徵,減少計算量。
notice3:tf.clip_by_global_norm防止梯度消失和爆炸。 2.3) Wide&Deep在TensorFlow裡面的API介面為:tf.estimator.DNNLinearCombinedClassifier
2.4)FM&DNN vs LR: FM 和 DNN 都算是這樣的模型,可以在很少的特徵工程情況下,通過學習一個低緯度的 embedding vector 來學習訓練集中從未見過的組合特徵。
FM 和 DNN 的缺點在於: 當 query-item 矩陣是稀疏並且是 high-rank 的時候(比如 user 有特殊的愛好,或 item 比較小眾),很難非常效率的學習出低維度的表示。這種情況下,大部分的 query-item 都沒有什麼關係。但是 dense embedding 會導致幾乎所有的 query-item 預測值都是非 0 的,這就導致了推薦過度泛化,會推薦一些不那麼相關的物品。
相反,linear model 卻可以通過 cross-product transformation 來記住這些 exception rules,而且僅僅使用了非常少的引數。
總結一下:
線性模型無法學習到訓練集中未出現的組合特徵;FM 或 DNN 通過學習 embedding vector 雖然可以學習到訓練集中未出現的組合特徵,但是會過度泛化
-
W&D的模型的訓練:
模型訓練採用的是聯合訓練(joint training),模型的訓練誤差會同時反饋到線性模型和DNN模型中進行引數更新。相比於ensemble learning中單個模型進行獨立訓練,模型的融合僅在最終做預測階段進行,joint training中模型的融合是在訓練階段進行的,單個模型的權重更新會受到wide端和deep端對模型訓練誤差的共同影響。因此在模型的特徵設計階段,wide端模型和deep端模型只需要分別專注於擅長的方面,wide端模型通過離散特徵的交叉組合進行memorization,deep端模型通過特徵的embedding進行generalization,這樣單個模型的大小和複雜度也能得到控制,而整體模型的效能仍能得到提高。
-
Joint Training vs Ensemble
-
Joint Training 同時訓練 wide & deep 模型,優化的引數包括兩個模型各自的引數以及 weights of sum
-
Ensemble 中的模型是分別獨立訓練的,互不干擾,只有在預測時才會聯絡在一起
-
-
問題思考:目前的CTR預估模型,實質上都是在“利用模型”進行特徵工程上狠下功夫。為什麼線性模型有記憶能力,而DNN模型有泛化能力?文章指出,wide端模型通過離散特徵的交叉組合進行memorization, deep端模型通過特徵的embedding進行generalization. 同時wide and deep模型中使用的特徵包括兩大類:一類是連續型特徵,主要用於deep模型的訓練,包括real value 型別的特徵及embedding型別的特徵等;一類是離散型特徵,主要用於wide模型的訓練,包括sparse型別的特徵以及cross型別的特徵等。所有特徵的彙總圖如下:
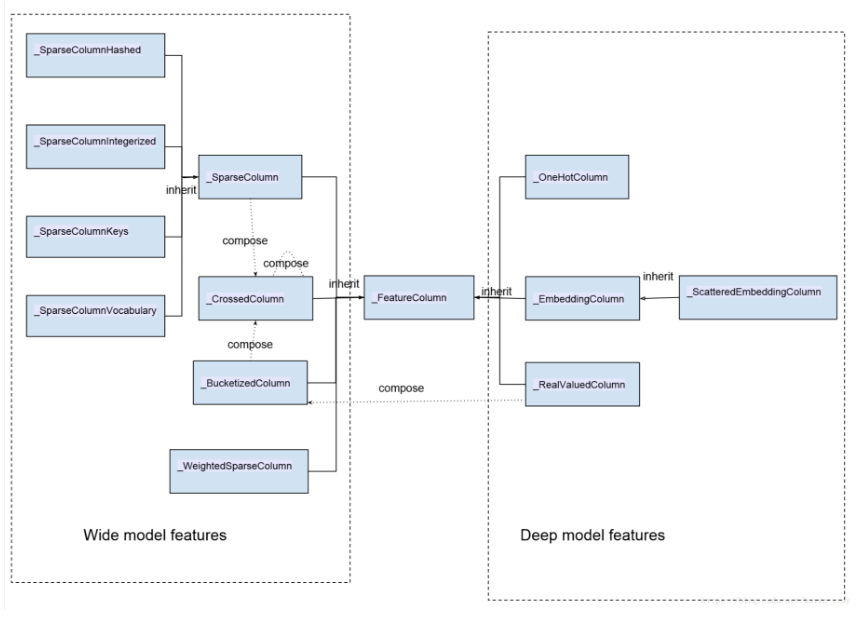
圖中類與類的關係除了 inherit(繼承)之外,同時我們也標出了特徵類之間的構成關係:_BucketizedColumn 由_RealValueColumn 通過對連續值域進行分桶構成,_CrossedColumn 由若干_SparseColumn 或者_BucketizedColumn 或者_CrossedColumn 經過交叉組合構成。圖中左邊部分特徵屬於離散型特徵,右邊部分特徵屬於連續型特徵。
tf.contrib.layers.feature_column進行特徵處理介面:
(1)sparse column from keys
(2) sparse column from vocabulary file
(3) sparse column with hash bucket
(4) crossed column (笛卡爾積)
(5)我們在實際使用的時候,通常情況下是呼叫 TensorFlow 提供的介面來構建特徵的。以下是構建各類特徵的介面:
sparse_column_with_integerized_feature() --> _SparseColumnIntegerized
sparse_column_with_hash_bucket() --> _SparseColumnHashed
sparse_column_with_keys() --> _SparseColumnKeys
sparse_column_with_vocabulary_file() --> _SparseColumnVocabulary
weighted_sparse_column() --> _WeightedSparseColumn
one_hot_column() --> _OneHotColumn
embedding_column() --> _EmbeddingColumn
shared_embedding_columns() --> List[_EmbeddingColumn]
scattered_embedding_column() --> _ScatteredEmbeddingColumn
real_valued_column() --> _RealValuedColumn
bucketized_column() -->_BucketizedColumn
crossed_column() --> _CrossedColumn
-
優缺點
缺點:Wide 部分還是需要人為的特徵工程。優點:實現了對 memorization 和 generalization 的統一建模
-
ref:
-
模型程式碼講解:https://blog.csdn.net/heyc861221/article/details/80131369
-
模型程式碼及特徵工程詳解2:https://blog.csdn.net/kwame211/article/details/78015498
-
官方程式碼:https://github.com/tensorflow/models/tree/master/official/wide_deep
-