
大資料的倉庫Hive原理(二)
上次我們說到了大資料應用中的資料倉庫hive,我們知道了利用hive可以更方便的處理資料,而且它的擴充套件性、延展性和容錯性都比較好,但是它是如何利用Hql(類Sql語句)來實現資料處理的呢。
1、架構回顧
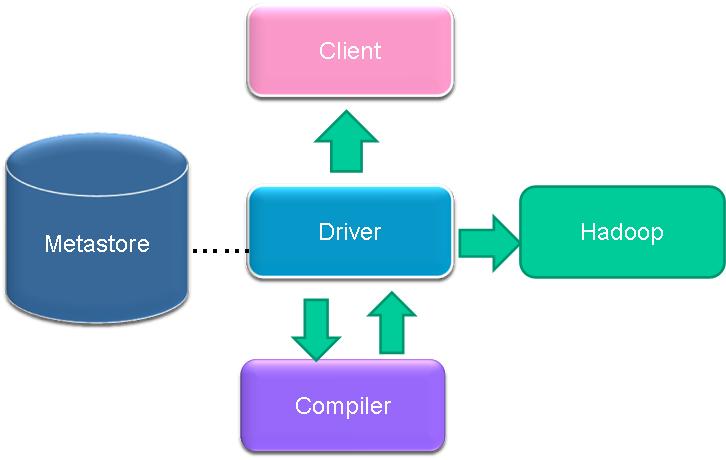
- UI
使用者提交查詢請求與獲得查詢結果。包括三個介面:命令列(CLI)、Web GUI(Hue)和客戶端。
- Driver
接受查詢請求與返回查詢結果。實現了session的概念,以處理和提供基於JDBC/ODBC執行以及頡取的API。
Compiler
編譯器,分析查詢SQL語句,在不同的查詢塊和查詢表示式上進行語義分析,並最終通過從metastore中查詢表與分割槽的元資訊生成執行計劃。
Metastore
元資料儲存,元資料儲存在MySQL或derby等資料庫中。元資料包括Hive各種表與分割槽的結構化資訊,包括列與列型別資訊,序列化器與反序列化器,從而能夠讀寫hdfs中的資料。
- Execution Engine
執行引擎,執行由compiler建立的執行計劃。此計劃是一個關於階段的有向無環圖。執行引擎管理不同階段的依賴關係,通過MapReuce執行這些階段。
2、編譯流程
Parser:分析器,將SQL轉換成抽象語法樹。Semantic Analyzer:語義分析,將抽象語法樹轉換成查詢塊。Logic Plan Generator:邏輯查詢計劃生成器,將查詢塊轉換成邏輯查詢計劃,該計劃是一棵操作符樹。
LogicalOptimizer:重寫邏輯查詢計劃。Physical Plan Generator:物理查詢計劃生產器,將邏輯計劃轉成一些列的M/R jobs。PhysicalOptimizer:選擇最佳Join策略。3、工作流程
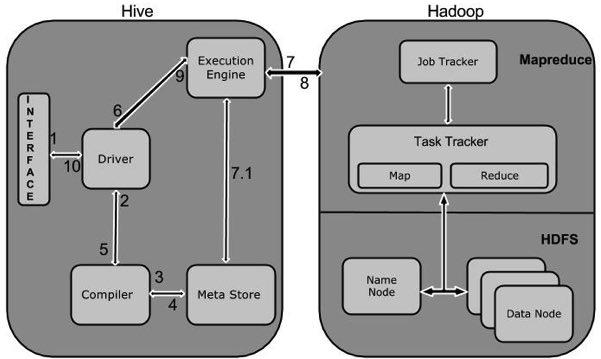
1 Execute QueryHive介面,如命令列或Web UI傳送查詢驅動程式(任何資料庫驅動程式,如JDBC,ODBC等)來執行。
2 Get Plan在驅動程式幫助下查詢編譯器,分析查詢檢查語法和查詢計劃或查詢的要求。
3 Get Metadata編譯器傳送元資料請求到Metastore(任何資料庫)。
4 Send MetadataMetastore傳送元資料,以編譯器的響應。
5 Send Plan編譯器檢查要求,並重新發送計劃給驅動程式。到此為止,查詢解析和編譯完成。
6 Execute Plan驅動程式傳送的執行計劃到執行引擎。
7 Execute Job在內部,執行作業的過程是一個MapReduce工作。執行引擎傳送作業給JobTracker,在名稱節點並把它分配作業到TaskTracker,這是在資料節點。在這裡,查詢執行MapReduce工作。
7.1 Metadata Ops與此同時,在執行時,執行引擎可以通過Metastore執行元資料操作。
8 Fetch Result執行引擎接收來自資料節點的結果。
9 Send Results執行引擎傳送這些結果值給驅動程式。
10 Send Results驅動程式將結果傳送給Hive介面。
總結:
我們從hive的簡單介紹到它優缺點的理解,以及它與傳統關係型資料庫的區別都做了一些學習,今天我們又對它的原理做了一些簡單的認識,下次我們繼續深入解析hive的工作原理。