
Python2中文亂碼處理
背景
本文在Window7 & python2.7.13下執行測試。
Python2處理中文字元時經常遇到亂碼問題,根源在於python儲存漢字的兩種表示形式和Window系統編碼之間的矛盾。本文通過實驗,力爭弄清幾者的關係。首先說理論基礎。
理論基礎
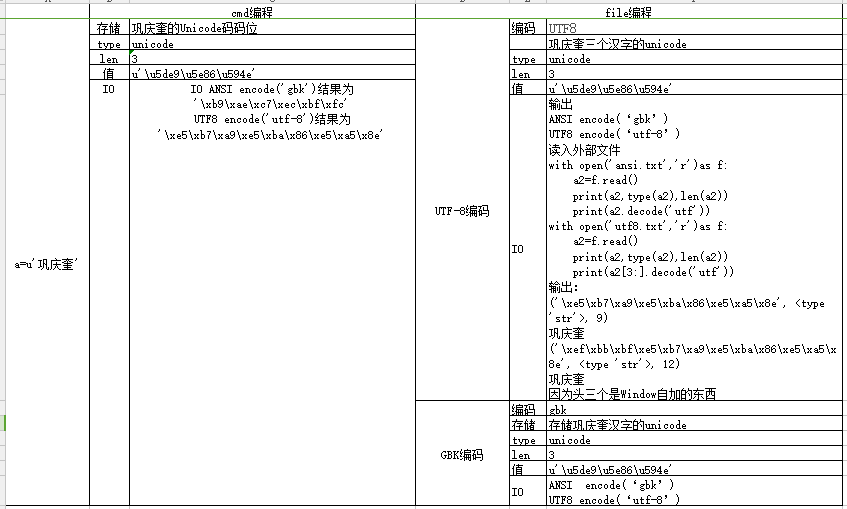
一、Python中文字元有兩種表示形式:一種是如a='鞏慶奎',另一種是b=u'鞏慶奎'。前者表示的是字元的編碼位元組序列,是Str型別,值根據採用的編碼(utf、gbk)不同而不同,如GBK編碼位元組序列為'\xb9\xae\xc7\xec\xbf\xfc',UTF8編碼位元組序列為'\xe5\xb7\xa9\xe5\xba\x86\xe5\xa5\x8e'
二、Window系統編碼。
1. CMD命令提示符介面編碼,這是CMD介面漢字的編碼,CMD輸入chcp顯示當前介面的預設編碼,本例是936/GBK,我們在CMD下輸入漢字,其實是輸入漢字的GBK編碼後的位元組序列。
2. 文字儲存的編碼型別。當我們新建文字文件另存為的時候,編碼檔案格式欄目就是該檔案儲存的編碼格式。預設是ANSI,可以視為GBK。另外還有UTF-8和Unicode等形式。當我們讀寫外部檔案是,這些外部檔案也存在編碼型別區分。
三、Python程式頭部宣告的編碼型別。即
四、Python中type函式返回變數型別,len返回變數長度。另外print函式輸出時,為了優化顯示,程式後臺用sys.stdout.encoding對字元進行了encoding成位元組流,交給終端顯示。
根據以上理論,設計實驗如下:
實驗
命令提示符程式設計
首先檢視CMD介面編碼,cmd介面輸入chcp可見介面編碼為936/GBK,程式設計如下:
>>> a='鞏慶奎'
>>> a,type(a),len(a)
('\xb9\xae\xc7\xec\xbf\xfc', <type 'str'>, 6)
若需要存入ANSI格式檔案則直接寫入,讀取時直接讀出為GBk格式位元組序列:
>>> with open('ansi.txt','w')as f:
... f.write(a)
...
>>> with open('ansi.txt','r')as f:
... a2=f.read()
...
>>> a2
'\xb9\xae\xc7\xec\xbf\xfc'
若存入及讀取UTF8格式檔案則需要:
>>> with open('utf.txt','w')as f:
... f.write(a.decode('gbk').encode('utf'))
...
>>> with open('utf.txt','r')as f:
... a2 = f.read()
...
>>> a2
'\xe5\xb7\xa9\xe5\xba\x86\xe5\xa5\x8e'
結果為UTF編碼字串。可見a='鞏慶奎',儲存的是根據GBK編碼的位元組序列,型別為Str,長度為6,儲存文字時需要根據目標格式進行編碼成Str型別。那為什麼在UTF格式儲存時需要decode(‘gbk’)呢,這就是下一個關鍵點:Unicode字元。實驗
>>> b=u'鞏慶奎'
>>> b
u'\u5de9\u5e86\u594e'
>>> b,type(b),len(b)
(u'\u5de9\u5e86\u594e', <type 'unicode'>, 3)
若需要存入ANSI格式檔案以及讀取:
>>> with open('ansi.txt','w')as f:
... f.write(b.encode('gbk'))
...
>>> with open('ansi.txt','r')as f:
... b2=f.read()
...
>>> b2
'\xb9\xae\xc7\xec\xbf\xfc'
>>> b2.decode('gbk')
u'\u5de9\u5e86\u594e'
若存入及讀取UTF8格式檔案則需要:
>>> with open('utf.txt','w')as f:
... f.write(b.encode('utf'))
...
>>> with open('utf.txt','r')as f:
... b2=f.read()
...
>>> b2
'\xe5\xb7\xa9\xe5\xba\x86\xe5\xa5\x8e'
>>> b2.decode('utf')
u'\u5de9\u5e86\u594e'
Unicode字串b=u’鞏慶奎’,這是鞏慶奎三個漢字的Unicode碼碼位,是Unicode型別,儲存的是漢字在Unicode表中的位置,len(a)=3。Unicode是Python2的中間轉換碼,編碼和解碼都要藉助這個中間媒介。看實驗:
位元組序列根據自身編碼解碼成unicode字元,我們驗證:
>>> a='鞏慶奎'
>>> b=u'鞏慶奎'
>>> a.decode('gbk')==b
True
Unicode字元編碼成位元組序列,驗證:
>>> b.encode('gbk')==a
True
可知,Unicode是中間碼,是漢字標準位置值。這樣就能解釋當gbk位元組序列儲存到UTF8檔案格式時,需要首先decode(‘gbk’)的問題啦,這是先轉成unicode,然後再encode成UTF8編碼。
Python檔案程式設計
1. 首先保證文字儲存編碼和檔案頭部宣告編碼一致。
2. 假設不宣告而不另存為修改格式的話,則為ANSI格式檔案視為GBK編碼,這種情況類似命令提示符編碼為GBK下程式設計。
3. 若宣告為UTF-8型別檔案,且檔案另存為UTF-8型別,則檔案中常量是UTF-8編碼的。
a='鞏慶奎'
其實a是鞏慶奎這三個漢字的UTF8編碼後的str型別。儲存的是UTF8編碼值,type(a)為str型別,長度len(a)為6。若需要存入ANSI格式檔案需要decode(‘utf-8’).encode(‘gbk’),若存入UTF8格式檔案則直接寫入。
b=u'鞏慶奎'
這是鞏慶奎三個漢字的Unicode碼碼位,是Unicode型別,儲存的是漢字在Unicode表中的位置,len(a)=3。若需要存入ANSI格式檔案則f.write(a.encode(‘gbk’)),若存入UTF8格式檔案則需要f.write(a.encode(‘utf-8’))。根據以上實驗,總結表如下
實驗結果

結論
1. Python中處理漢字有兩種形式,一種是根據漢字編碼方案具體編碼的位元組序列Str型別,另一種是根據漢字在Unicode表中固定位置的Unicode型別。(特指2.*版本,3.0以上版本換用另外的處理方式)
2. Window系統下命令提示符介面、文字檔案各有編碼格式。
3. Str型別是二進位制編碼的漢字,比較複雜多變,若需要可以根據自身編碼decode成Unicode碼位。Unicode型別是漢字的Unicode固定值,可以作為encode和decode的中間媒介,Unicode是碼位,不是編碼,需要encode成另外的編碼來儲存顯示,unicode也只支援encode方法。Str變unicode為decode,unicode變str為encode。
4. 讀寫檔案需要str型別,故若字串不是str,需根據目標檔案格式encode。若程式設計檔案格式與目標檔案格式不一致,還需要先將其根據程式設計檔案格式decode成unicode然後再encode成目標檔案格式。
5. 介面顯示需要unicode型別,故若字串不是unicode,需根據目標平臺編碼來decode。
6.Unicode儲存為檔案時,只需要根據目標檔案編碼encode成位元組序列即可。讀入檔案取unicode值時,只需要根據目標檔案編碼decode取得的位元組序列即可。