
python網路爬蟲例項:Requests+正則表示式爬取貓眼電影TOP100榜
阿新 • • 發佈:2019-02-16
一、前言
最近在看崔慶才先生編寫的《Python3網路爬蟲開發實戰》這本書,學習了requests庫和正則表示式,爬取貓眼電影top100榜單是這本書的第一個例項,主要目的是要掌握requests庫和正則表示式在實際案例中的使用。
二、開發環境
執行平臺: Windows 10
Python版本: Python3.6
IDE: PyCharm
三、爬取思路
- 抓取單頁內容
- 正則表示式提取有用資訊
- 儲存資訊
- 下載TOP100所有電影資訊
- 多執行緒抓取
爬取單頁內容
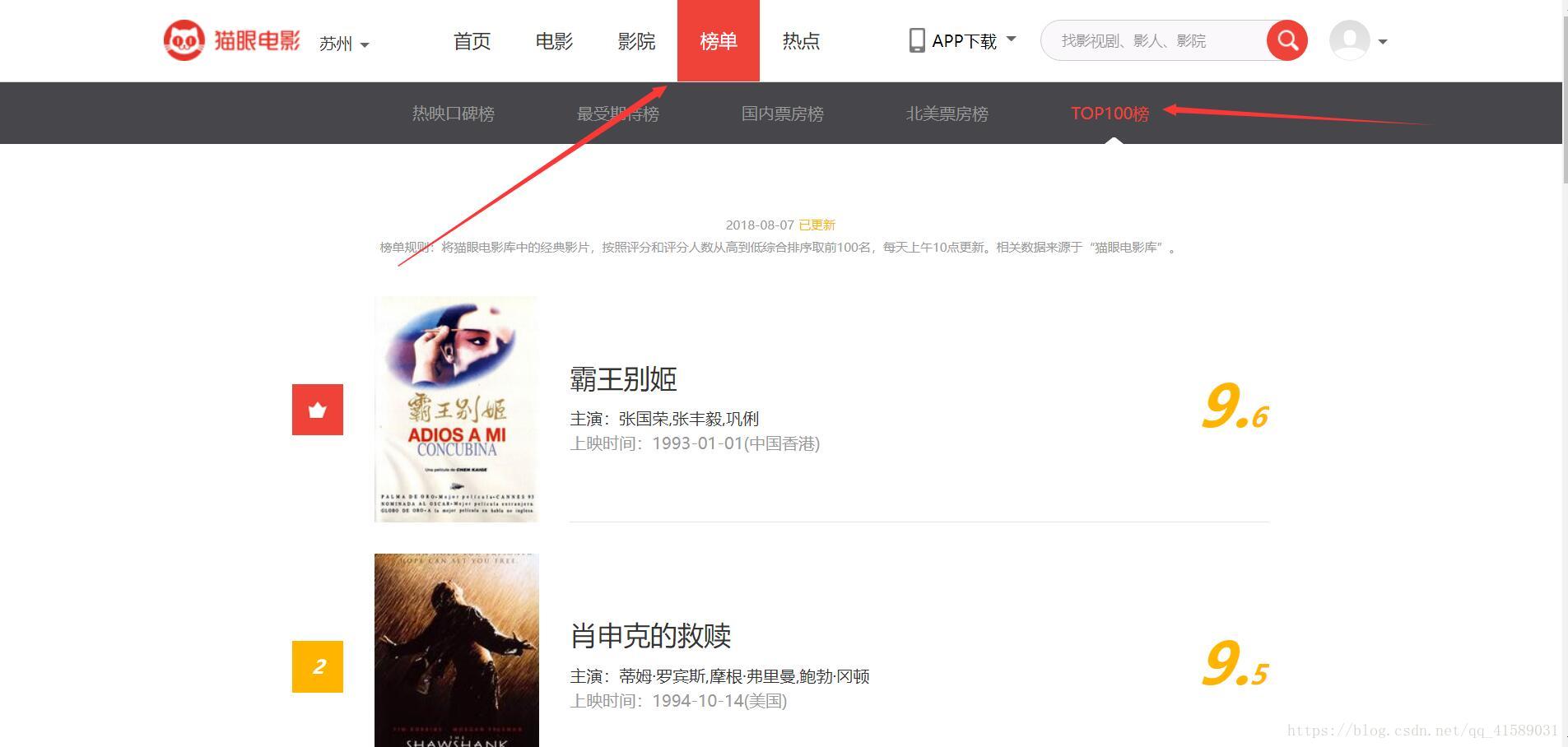
首先開啟Chrome瀏覽器,開啟貓眼電影網站(http://maoyan.com/)然後點選榜單,點選TOP100榜。
然後通過requests庫將整個HTML程式碼獲取下來:
import requests
from requests.exceptions import RequestException #捕捉異常
def get_one_page(url):
'''
獲取網頁html內容並返回
'''
try:
# 獲取網頁html內容
response = requests.get(url)
# 通過狀態碼判斷是否獲取成功
if response.status_code == 200:
return 正則表示式提取有用資訊
然後按F12,檢視網頁的原始碼,然後逐層找到要爬取資訊的所在位置①排名、②電影封面、③電影名稱、④主演、⑤上映時間、⑥評分(整數和小數兩部分)
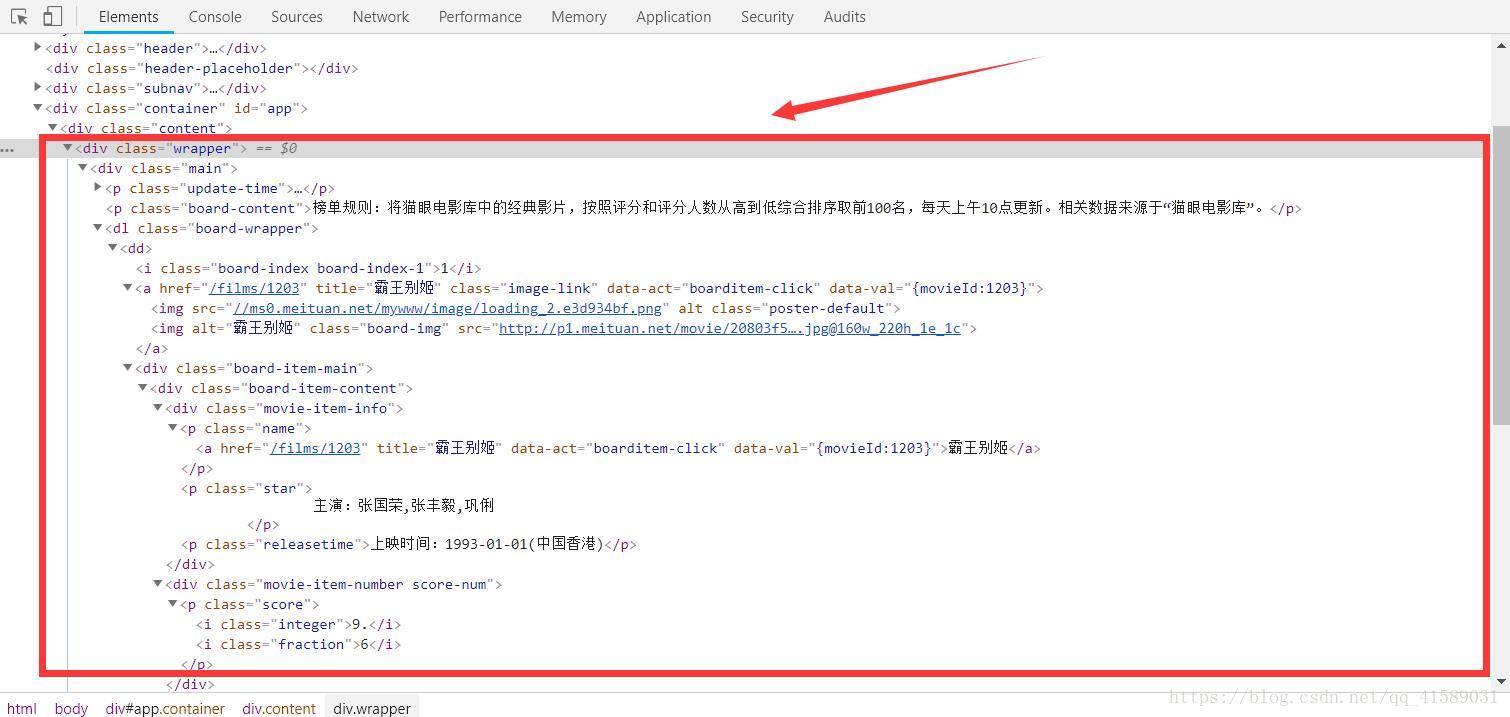
利用正則表示式解析提取出來:
import re
def parse_one_page(html):
'''
解析HTML程式碼,提取有用資訊並返回
'''
# 正則表示式進行解析
pattern = re.compile('<dd>.*?board-index.*?>(\d+)</i>.*?data-src="(.*?)".*?name">'
+ '<a.*?>(.*?)</a>.*?"star">(.*?)</p>.*?releasetime">(.*?)</p>'
+ '.*?integer">(.*?)</i>.*?fraction">(.*?)</i>.*?</dd>', re.S)
# 匹配所有符合條件的內容
items = re.findall(pattern, html)
for item in items:
yield {
'index': item[0],
'image': item[1],
'title': item[2],
'actor': item[3].strip()[3:],
'time': item[4].strip()[5:],
'score': item[5] + item[6]
}
# 修改main()函式
def main():
url = 'http://maoyan.com/board/4'
html = get_one_page(url)
for item in parse_one_page(html):
print(item)儲存資訊
將爬取的資訊儲存成檔案形式,方便以後檢視
def write_to_file(content): #儲存到檔案中
with open('result.txt','a',encoding='utf-8') as f:
f.write(json.dumps(content,ensure_ascii=False)+'\n') #利用json.dumps將字典轉換成字串的形式
f.close()下載TOP100所有電影資訊
通過點選下面的頁面標籤換頁發現URL中多了offset引數,每次換頁更改的都是offset引數後面的數字,數字更改的規律都是 (頁碼數-1)*10
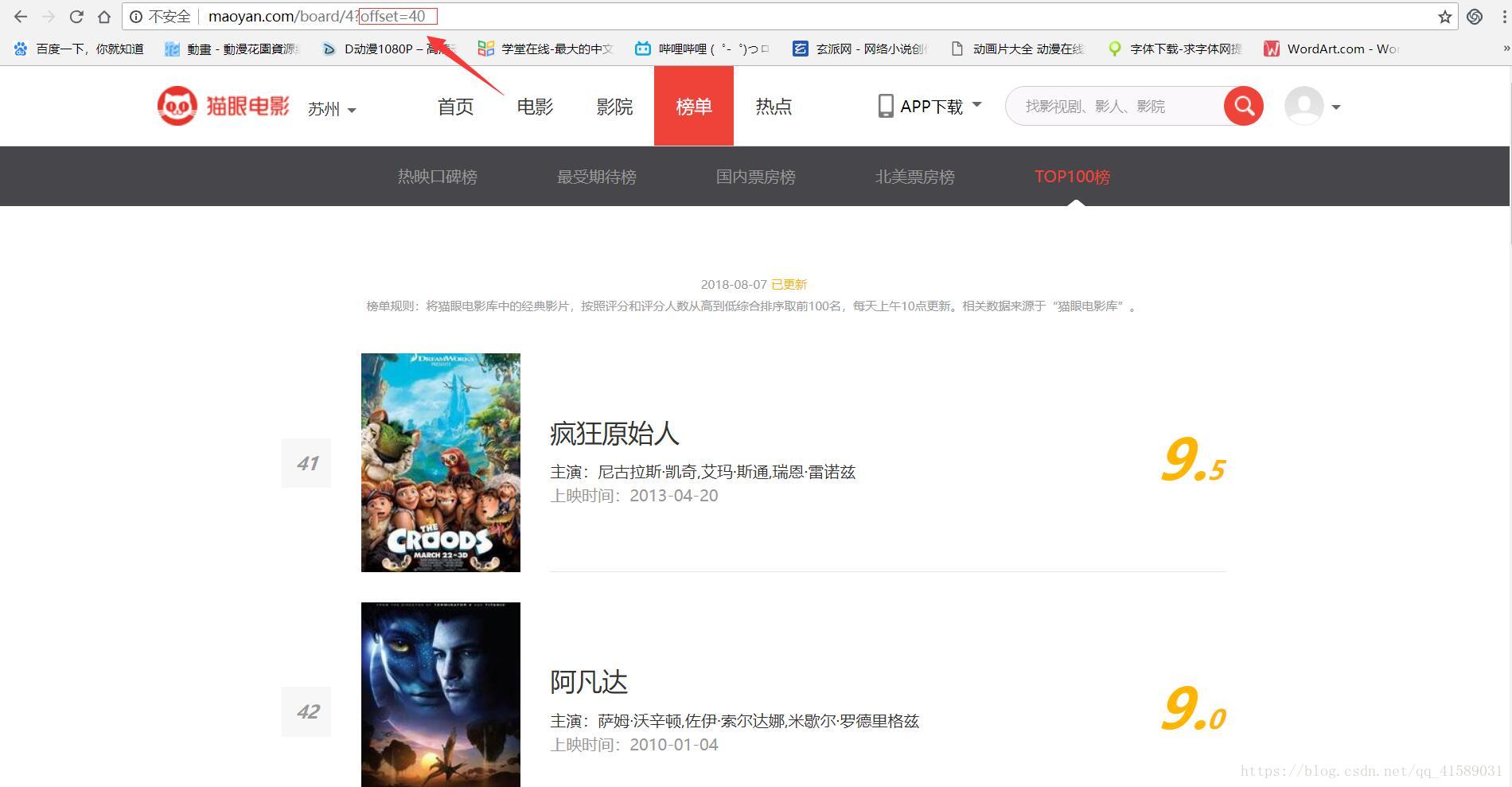
所以只需要更改main函式動態改變URL即可完成:
def main(offset):
url = 'http://maoyan.com/board/4?offset=' + str(offset)
html = get_one_page(url)
for item in parse_one_page(html):
print(item)
write_to_file(item)
if __name__ == '__main__':
for i in rang(10):
main(i * 10)多執行緒爬取
此次爬取的資料不太多,引入多執行緒是為了以後爬取更多的資料做準備的,多執行緒爬取資料能讓爬取的速度更加的迅速,節省爬取時間
from multiprocessing import Pool
if __name__ == '__main__':
pool=Pool()
pool.map(main,[i*10 for i in range(10)])四、完整程式碼
#匯入需要使用的模組
import requests
from multiprocessing import Pool
from requests.exceptions import RequestException
import re
import json
#嘗試連接獲取頁面
def get_one_page(url):
try:
response=requests.get(url)
if response.status_code==200:
return response.text
return None
except RequestException:
return None
#正則匹配需要的內容
def parse_one_page(html):
pattern=re.compile('<dd>.*?board-index.*?>(\d+)</i>.*?data-src="(.*?)".*?name"><a'
+'.*?>(.*?)</a>.*?star">(.*?)</p>.*?releasetime">(.*?)</p>'
+'.*?integer">(.*?)</i>.*?fraction">(.*?)</i>.*?</dd>',re.S)
#用迭代進行非同步操作
items=re.findall(pattern,html)
for item in items:
yield {
'index':item[0],
'image':item[1],
'title':item[2],
'ator':item[3].strip()[3:],
'time':item[4].strip()[5:],
'score':item[5]+item[6]
}
#儲存到檔案中
def write_to_file(content):
with open('result.txt','a',encoding='utf-8') as f:
f.write(json.dumps(content,ensure_ascii=False)+'\n') #利用json.dumps將字典轉換成字串的形式
f.close()
#配置啟動函式
def main(offset):
url='http://maoyan.com/board/4?offset='+str(offset)
html=get_one_page(url)
for item in parse_one_page(html):
print(item)
write_to_file(item)
#使用多程序加速一秒完成
if __name__ == '__main__':
pool=Pool()
pool.map(main,[i*10 for i in range(10)])五、總結
熟練使用requests庫和正則表示式是網路爬蟲的基礎,大多數的網站都可以利用requests庫+正則表示式將需要資訊爬取下來