
PHP7雜湊表(陣列)的核心實現
PHP7+內部雜湊表,即PHP強大array結構的核心實現。
雜湊表是PHP內部非常重要的資料結構,除了PHP使用者空間的Array,核心也隨處用到,比如function、class的索引、符號表等等都用到了雜湊表。
關於雜湊結構PHP7+與PHP5+的區別可以翻下[nikic]早些時候寫的一篇文章,這裡不作討論。
資料結構
//zend_types.h
typedef struct _Bucket {
zval val;
zend_ulong h; /* hash value (or numeric index) */ 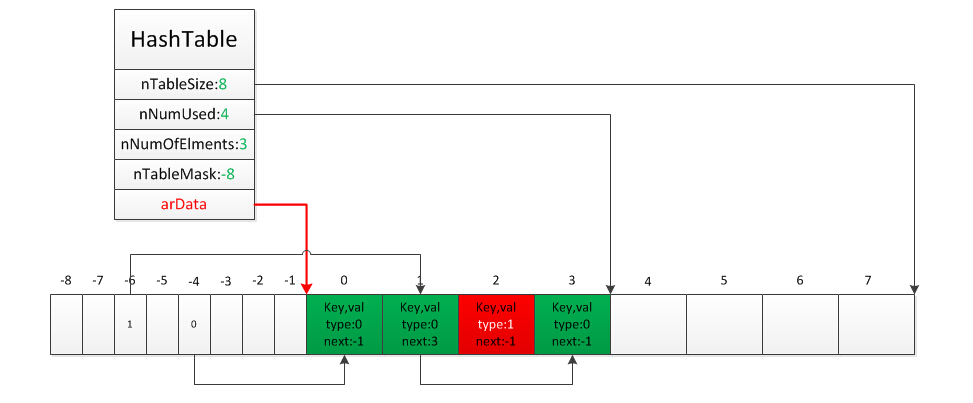
HashTable中有兩個非常相近的值:nNumUsed、nNumOfElements,nNumOfElements表示雜湊表已有元素數,那這個值不跟nNumUsed一樣嗎?為什麼要定義兩個呢?實際上它們有不同的含義,當將一個元素從雜湊表刪除時並不會將對應的Bucket移除,而是將Bucket儲存的zval標示為IS_UNDEF,只有擴容時發現nNumOfElements與nNumUsed相差達到一定數量(這個數量是:ht->nNumUsed - ht->nNumOfElements > (ht->nNumOfElements >> 5))時才會將已刪除的元素全部移除,重新構建雜湊表。所以nNumUsed>=nNumOfElements。
HashTable中另外一個非常重要的值arData,這個值指向儲存元素陣列的第一個Bucket,插入元素時按順序依次插入陣列,比如第一個元素在arData[0]、第二個在arData[1]…arData[nNumUsed]。PHP陣列的有序性正是通過arData保證的。
雜湊表實現的關鍵是有一個數組儲存雜湊值與Bucket的對映,但是HashTable中並沒有這樣一個索引陣列。
實際上這個索引陣列包含在arData中,索引陣列與Bucket列表一起分配,arData指向了Bucket列表的起始位置,而索引陣列可以通過arData指標向前移動訪問到,即arData[-1]、arData[-2]、arData[-3]……索引陣列的結構是uint32_t,它儲存的是Bucket元素在arData中的位置。
所以,整體來看HashTable主要依賴arData實現元素的儲存、索引。插入一個元素時先將元素插入Bucket陣列,位置是idx,再根據key的雜湊值與nTableMask計算出索引陣列的位置,將idx存入這個位置;查詢時先根據key的雜湊值與nTableMask計算出索引陣列的位置,獲得元素在Bucket陣列的位置idx,再從Bucket陣列中取出元素。
索引陣列
索引陣列型別是uint32_t[],儲存的值為元素在Bucket陣列中的位置
索引位置(nIndex)是如何得到的?我們一般根據雜湊值與陣列大小取模得到,即key->h % ht->nTableSize,但是PHP是這麼計算的:
nIndex = key->h | ht->nTableMask;顯然位運算要比取模更快。
nTableMask為nTableSize的負數,即:nTableMask = -nTableSize,因為nTableSize等於2^n,所以nTableMask二進位制位右側全部為0,也就保證了|nIndex| <= nTableSize:
11111111 11111111 11111111 11111000 -8
11111111 11111111 11111111 11110000 -16
11111111 11111111 11111111 11100000 -32
11111111 11111111 11111111 11000000 -64
11111111 11111111 11111111 10000000 -128雜湊碰撞
雜湊碰撞是指不同的key可能計算得到相同的雜湊值(數值索引的雜湊值直接就是數值本身),但是這些值又需要插入同一個雜湊表。一般解決方法是將Bucket串成連結串列,查詢時遍歷連結串列比較key。
PHP的實現也是類似,只是指向衝突元素的指標並沒有直接存在Bucket中,而是存在嵌入的zval中,zval的結構:
struct _zval_struct {
zend_value value; /* value */
union {
struct {
ZEND_ENDIAN_LOHI_4(
zend_uchar type, /* active type */
zend_uchar type_flags,
zend_uchar const_flags,
zend_uchar reserved) /* call info for EX(This) */
} v;
uint32_t type_info;
} u1;
union {
uint32_t var_flags;
uint32_t next; /* hash collision chain */
uint32_t cache_slot; /* literal cache slot */
uint32_t lineno; /* line number (for ast nodes) */
uint32_t num_args; /* arguments number for EX(This) */
uint32_t fe_pos; /* foreach position */
uint32_t fe_iter_idx; /* foreach iterator index */
} u2;
};zval.u2.next存的就是衝突元素在Bucket陣列中的位置,所以查詢過程類似:
zend_ulong h = zend_string_hash_val(key);
uint32_t idx = ht->arHash[h & ht->nTableMask];
while (idx != INVALID_IDX) {
Bucket *b = &ht->arData[idx];
if (b->h == h && zend_string_equals(b->key, key)) {
return b;
}
idx = Z_NEXT(b->val); // b->val.u2.next
}
return NULL;插入、查詢、刪除
這幾個基本操作比較簡單,不再贅述,定位到元素所在Bucket位置後的操作類似單鏈表的插入、刪除、查詢。
擴容
雜湊表的大小為2^n,插入時如果容量不夠則首先檢查已刪除元素所佔比例,如果達到閾值(ht->nNumUsed - ht->nNumOfElements > (ht->nNumOfElements >> 5),則將已刪除元素移除,重建索引,如果未到閾值則進行擴容操作,擴大為當前大小的2倍,將當前Bucket陣列複製到新的空間,然後重建索引。
//zend_hash.c
static void ZEND_FASTCALL zend_hash_do_resize(HashTable *ht)
{
IS_CONSISTENT(ht);
HT_ASSERT(GC_REFCOUNT(ht) == 1);
if (ht->nNumUsed > ht->nNumOfElements + (ht->nNumOfElements >> 5)) { //只有到一定閾值才進行rehash操作
HANDLE_BLOCK_INTERRUPTIONS();
zend_hash_rehash(ht); //重建索引陣列
HANDLE_UNBLOCK_INTERRUPTIONS();
} else if (ht->nTableSize < HT_MAX_SIZE) { //擴大為兩倍
void *new_data, *old_data = HT_GET_DATA_ADDR(ht);
uint32_t nSize = ht->nTableSize + ht->nTableSize;
Bucket *old_buckets = ht->arData;
HANDLE_BLOCK_INTERRUPTIONS();
new_data = pemalloc(HT_SIZE_EX(nSize, -nSize), ht->u.flags & HASH_FLAG_PERSISTENT); //新分配arData空間,大小為:(sizeof(Bucket) + sizeof(uint32_t)) * nSize
ht->nTableSize = nSize;
ht->nTableMask = -ht->nTableSize; //nTableSize負值
HT_SET_DATA_ADDR(ht, new_data); //將arData指標偏移到Bucket陣列起始位置
memcpy(ht->arData, old_buckets, sizeof(Bucket) * ht->nNumUsed); //將舊的Bucket陣列拷到新空間
pefree(old_data, ht->u.flags & HASH_FLAG_PERSISTENT); //釋放舊空間
zend_hash_rehash(ht); //重建索引陣列
HANDLE_UNBLOCK_INTERRUPTIONS();
} else {
zend_error_noreturn(E_ERROR, "Possible integer overflow in memory allocation (%zu * %zu + %zu)", ht->nTableSize * 2, sizeof(Bucket) + sizeof(uint32_t), sizeof(Bucket));
}
}
#define HT_SET_DATA_ADDR(ht, ptr) do { \
(ht)->arData = (Bucket*)(((char*)(ptr)) + HT_HASH_SIZE((ht)->nTableMask)); \
} while (0)重建索引
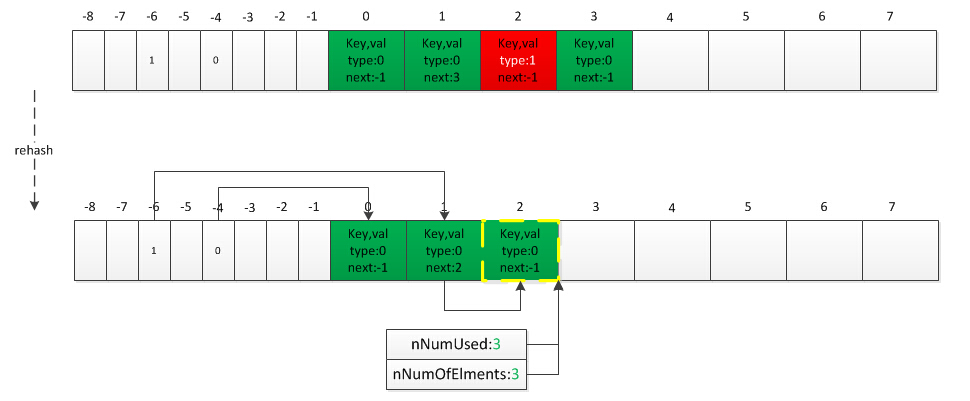
當刪除元素達到一定數量或擴容後都需要進行索引陣列的重建,因為元素所在Bucket位置移動了或雜湊陣列nTableSize變化了導致原雜湊索引變化,已刪除的元素將重新可以分配。
//zend_hash.c
ZEND_API int ZEND_FASTCALL zend_hash_rehash(HashTable *ht)
{
Bucket *p;
uint32_t nIndex, i;
...
i = 0;
p = ht->arData;
if (ht->nNumUsed == ht->nNumOfElements) { //沒有已刪除的直接遍歷Bucket陣列重新插入索引陣列即可
do {
nIndex = p->h | ht->nTableMask;
Z_NEXT(p->val) = HT_HASH(ht, nIndex);
HT_HASH(ht, nIndex) = HT_IDX_TO_HASH(i);
p++;
} while (++i < ht->nNumUsed);
} else {
do {
if (UNEXPECTED(Z_TYPE(p->val) == IS_UNDEF)) {//有已刪除元素需要將其移到後面,壓實Bucket陣列
......
while (++i < ht->nNumUsed) {
p++;
if (EXPECTED(Z_TYPE_INFO(p->val) != IS_UNDEF)) {
ZVAL_COPY_VALUE(&q->val, &p->val);
q->h = p->h;
nIndex = q->h | ht->nTableMask;
q->key = p->key;
Z_NEXT(q->val) = HT_HASH(ht, nIndex);
HT_HASH(ht, nIndex) = HT_IDX_TO_HASH(j);
if (UNEXPECTED(ht->nInternalPointer == i)) {
ht->nInternalPointer = j;
}
q++;
j++;
}
}
......
ht->nNumUsed = j;
break;
}
nIndex = p->h | ht->nTableMask;
Z_NEXT(p->val) = HT_HASH(ht, nIndex);
HT_HASH(ht, nIndex) = HT_IDX_TO_HASH(i);
p++;
}while(++i < ht->nNumUsed);
}
}