
個人專案面試題
通常來說,一面考察基礎,二面考察專案。要善於總結自己做過的專案以及實習中學到的東西,這樣才能在面試時過了專案這一關。
1、你能簡單描述一下HBase嗎?能畫出它的架構圖嗎?
HBase是一個面向列的 NoSQL 分散式資料庫,它利用HDFS作為底層儲存系統。那麼,HBase相對於傳統的關係型資料庫有什麼不同呢?
- HBase是schema-free的,它的列是可以動態增加的(僅僅定義列族),並且為空的列不佔物理儲存空間。
- HBase是基於列儲存的,每個列族都由幾個檔案儲存,不同的列族的檔案是分離的。
- HBase自動切分資料,使得資料儲存自動具有很好的橫向擴充套件性。
- HBase沒有任何事務,提供了高併發讀寫操作的支援。
HBase中的Table是一個稀疏的、多維度的、排序的對映表,這張表的索引是[RowKey, ColumnFamily, ColumnQualifier, Timestamp],其中Timestamp表示版本,預設獲取最新版本。HBase是通過RowKey來檢索資料的,RowKey是Table設計的核心,它按照ASCII有序排序,因此應儘量避免順序寫入。RowKey設計應該注意三點:
- 唯一原則:在HBase中rowkey可以看成是表的主鍵,必須保證其唯一性。
- 雜湊原則:由於rowkey是按字典有序的,故應避免rowkey連續有序而導致在某一臺RegionServer上堆積的現象。例如可以拼接隨機數、將時間戳倒序等。
- 長度原則:設計時RowKey要儘量短,這樣可以提高有效資料的比例,節省儲存空間,也可以提高查詢的效能。
下面是HBase的整體架構圖:
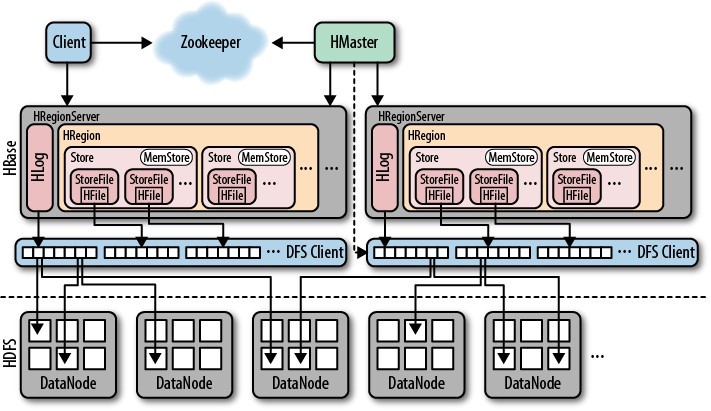
2、你說了解kafka,能簡單描述一下Kafka嗎?能畫出它的架構圖嗎?
Kafka是一個高吞吐、易擴充套件的分散式釋出-訂閱訊息系統,它能夠將訊息持久化到磁碟,用於批量的消費。Kafka中有以下幾個概念:
- Topic:特指Kafka處理的訊息源(feeds of messages)的不同分類。
- Partition:Topic物理上的分組,一個topic可以分為多個partition,每個partition是一個有序的佇列。partition中的每條訊息都會被分配一個有序的id(offset)。
- Broker:Kafa叢集中包含一臺或多臺伺服器,這種伺服器被稱為broker。
- Producer:生產者,向Kafka的一個topic釋出訊息。
- Consumers:消費者,從kafka的某個topic讀取訊息。
Kafka架構圖如下:

3、請介紹你的一個亮點專案?你在其中做了什麼?碰到了什麼技術難點?
【解】介紹專案《九州卡牌》手遊,我在專案中主要負責客戶端邏輯與戰鬥效果的實現,以及網路通訊模組的設計與開發。
首先,對於網路通訊我們選擇使用TCP長連線,因為對於卡牌類手遊可以容忍偶爾地延遲,並且有伺服器主動給客戶端推送訊息的需求。
優點:
- 簡單有效的長連線
- 可靠的資訊傳輸
- 資料包的大小沒有限制
- 伺服器可以主動向客戶端推送訊息(廣播等)
客戶端每隔3s傳送一次心跳包給伺服器,通知伺服器自己仍然線上,並獲取伺服器資料更新 —— 心跳包可以防止TCP的死連線問題,避免出現長時間不線上的死連結仍然出現在服務端的管理任務中。當客戶端長時間切換到後臺時,程序被掛起,連線會斷開。
TCP協議本身就有keep-alive機制,為什麼還要在應用層實現自己的心跳檢測機制呢?
- TCP的keep-alive機制可能在短暫的網路異常中,將一個良好的連線給斷開;
- keep-alive設計初衷是清除和回收死亡時間長的連線,不適合實時性高的場合,而且它會先要求連線一定時間內沒有活動,週期長,這樣其實已經斷開很長一段時間,沒有及時性;
- keep-alive不能主動通知應用層;
- 另外,想要通過心跳包來獲取伺服器的資料更新,所以選擇自己在應用層實現;
還有一個問題就是一臺機器的連線數有限制,可以通過滾服或者分散式來解決。
- 滾服:指老的伺服器連線數達到上限了,就開新的服務區,不同服務區的使用者不能互動。
- 分散式:長連線不分服的話,可以多個cluster節點連線同樣的CACHE資料來源,只是跨節點進行通訊比較麻煩一點(如使用者A連線到節點1,使用者B連線到節點2,使用者A向節點1發起TCP請求處理業務需要再通知到節點2的使用者B)。一般來說有2種解決方案:
- ①是建立場景伺服器,即專門用一個socket server來保持所有玩家的連線,然後它只處理資料推送,不做業務,可以達到10-20W承載;
- ②是採用釋出訂閱方式實現節點間的實時通訊。
我在Linux下寫了一個Socket心跳包示例程式,見文《TCP socket心跳包示例程式》。
4、請介紹一下MapReduce的工作原理。
【解】MapReduce是一個分散式計算框架,用於大規模資料集的並行運算。簡單地說,MapReduce就是”任務的分解與結果的彙總”:將一個大的資料處理任務劃分成許多個子任務,並將這些子任務分配給各個節點並行處理,然後通過整合各個節點的中間結果,得到最終結果。
MapReduce是主從架構,在master上跑的是JobTracker/ResourceManager,負責資源分配與任務排程;而各個slave上跑的是TaskTracker/NodeManager,負責執行任務,並定期向master彙報最新狀態與執行進度。
對於一個MR任務,它的輸入、輸出以及中間結果都是<key, value>鍵值對:
- Map:
<k1, v1>——>list(<k2, v2>) - Reduce:
<k2, list(v2)>——>list(<k3, v3>)
MR程式的執行過程主要分為三步:Map階段、Shuffle階段、Reduce階段,如下圖:
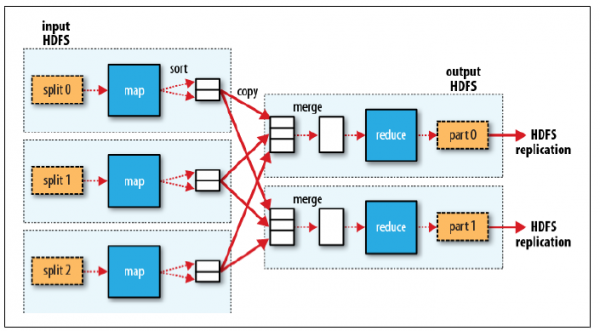
Map階段
分片(Split):map階段的輸入通常是HDFS上檔案,在執行Mapper前,FileInputFormat會將輸入檔案分割成多個split ——1個split至少包含1個HDFS的Block(預設為64M);然後每一個分片執行一個map進行處理。
執行(Map):對輸入分片中的每個鍵值對呼叫
map()函式進行運算,然後輸出一個結果鍵值對。- Partitioner:對 map 函式的輸出進行partition,即根據key或value及reduce的數量來決定當前的這對鍵值對最終應該交由哪個reduce處理。預設是對key雜湊後再以reduce task數量取模,預設的取模方式只是為了避免資料傾斜。然後該key/value對以及partitionIdx的結果都會被寫入環形緩衝區。
溢寫(Spill):map輸出寫在記憶體中的環形緩衝區,預設當緩衝區滿80%,啟動溢寫執行緒,將緩衝的資料寫出到磁碟。
- Sort:在溢寫到磁碟之前,使用快排對緩衝區資料按照partitionIdx, key排序。(每個partitionIdx表示一個分割槽,一個分割槽對應一個reduce)
- Combiner:如果設定了Combiner,那麼在Sort之後,還會對具有相同key的鍵值對進行合併,減少溢寫到磁碟的資料量。
合併(Merge):溢寫可能會生成多個檔案,這時需要將多個檔案合併成一個檔案。合併的過程中會不斷地進行 sort & combine 操作,最後合併成了一個已分割槽且已排序的檔案。
Shuffle階段:廣義上Shuffle階段橫跨Map端和Reduce端,在Map端包括Spill過程,在Reduce端包括copy和merge/sort過程。通常認為Shuffle階段就是將map的輸出作為reduce的輸入的過程
Copy過程:Reduce端啟動一些copy執行緒,通過HTTP方式將map端輸出檔案中屬於自己的部分拉取到本地。Reduce會從多個map端拉取資料,並且每個map的資料都是有序的。
Merge過程:Copy過來的資料會先放入記憶體緩衝區中,這裡的緩衝區比較大;當緩衝區資料量達到一定閾值時,將資料溢寫到磁碟(與map端類似,溢寫過程會執行 sort & combine)。如果生成了多個溢寫檔案,它們會被merge成一個有序的最終檔案。這個過程也會不停地執行 sort & combine 操作。
Reduce階段:Shuffle階段最終生成了一個有序的檔案作為Reduce的輸入,對於該檔案中的每一個鍵值對呼叫
reduce()方法,並將結果寫到HDFS。