
python redis的pipeline來實現批量命令
寫在前面
Redis的pipeline(管道)功能在命令列中沒有,但redis是支援pipeline的,而且在各個語言版的client中都有相應的實現。 由於網路開銷延遲,就算redis server端有很強的處理能力,也會由於收到的client訊息少,而造成吞吐量小。當client 使用pipelining 傳送命令時,redis server必須將部分請求放到佇列中(使用記憶體),執行完畢後一次性發送結果;如果傳送的命令很多的話,建議對返回的結果加標籤,當然這也會增加使用的記憶體;
Pipeline在某些場景下非常有用,比如有多個command需要被“及時的”提交,而且他們對相應結果沒有互相依賴,對結果響應也無需立即獲得,那麼pipeline就可以充當這種“批處理
不過在編碼時請注意,pipeline期間將“獨佔”連結,此期間將不能進行非“管道”型別的其他操作,直到pipeline關閉;如果你的pipeline的指令集很龐大,為了不干擾連結中的其他操作,你可以為pipeline操作新建Client連結,讓pipeline和其他正常操作分離在2個client中。不過pipeline事實上所能容忍的操作個數,和socket-output緩衝區大小/返回結果的資料尺寸都有很大的關係;同時也意味著每個redis-server同時所能支撐的pipeline連結的個數,也是有限的,這將受限於server的實體記憶體或網路介面的緩衝能力。
(一)簡介
Redis使用的是客戶端-伺服器(CS)模型和請求/響應協議的TCP伺服器。這意味著通常情況下一個請求會遵循以下步驟:
- 客戶端向服務端傳送一個查詢請求,並監聽Socket返回,通常是以阻塞模式,等待服務端響應。
- 服務端處理命令,並將結果返回給客戶端。
Redis客戶端與Redis伺服器之間使用TCP協議進行連線,一個客戶端可以通過一個socket連線發起多個請求命令。每個請求命令發出後client通常會阻塞並等待redis伺服器處理,redis處理完請求命令後會將結果通過響應報文返回給client,因此當執行多條命令的時候都需要等待上一條命令執行完畢才能執行。比如:
其執行過程如下圖所示:
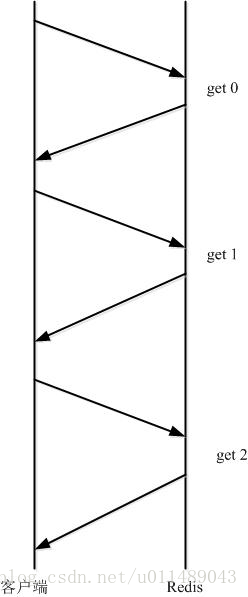
由於通訊會有網路延遲,假如client和server之間的包傳輸時間需要0.125秒。那麼上面的三個命令6個報文至少需要0.75秒才能完成。這樣即使redis每秒能處理100個命令,而我們的client也只能一秒鐘發出四個命令。這顯然沒有充分利用 redis的處理能力。
而管道(pipeline)可以一次性發送多條命令並在執行完後一次性將結果返回,pipeline通過減少客戶端與redis的通訊次數來實現降低往返延時時間,而且Pipeline 實現的原理是佇列,而佇列的原理是時先進先出,這樣就保證資料的順序性。 Pipeline 的預設的同步的個數為53個,也就是說arges中累加到53條資料時會把資料提交。其過程如下圖所示:client可以將三個命令放到一個tcp報文一起傳送,server則可以將三條命令的處理結果放到一個tcp報文返回。
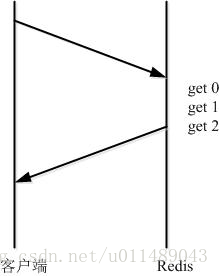
需要注意到是用 pipeline方式打包命令傳送,redis必須在處理完所有命令前先快取起所有命令的處理結果。打包的命令越多,快取消耗記憶體也越多。所以並不是打包的命令越多越好。具體多少合適需要根據具體情況測試。
(二)比較普通模式與PipeLine模式
測試環境:
Windows:Eclipse + jedis2.9.0 + jdk 1.7
Ubuntu:部署在虛擬機器上的伺服器 Redis 3.0.7
/*
* 測試普通模式與PipeLine模式的效率:
* 測試方法:向redis中插入10000組資料
*/
public static void testPipeLineAndNormal(Jedis jedis)
throws InterruptedException {
Logger logger = Logger.getLogger("javasoft");
long start = System.currentTimeMillis();
for (int i = 0; i < 10000; i++) {
jedis.set(String.valueOf(i), String.valueOf(i));
}
long end = System.currentTimeMillis();
logger.info("the jedis total time is:" + (end - start));
Pipeline pipe = jedis.pipelined();// 先建立一個pipeline的連結物件
long start_pipe = System.currentTimeMillis();
for (int i = 0; i < 10000; i++) {
pipe.set(String.valueOf(i), String.valueOf(i));
}
pipe.sync();// 獲取所有的response
long end_pipe = System.currentTimeMillis();
logger.info("the pipe total time is:" + (end_pipe - start_pipe));
BlockingQueue<String> logQueue = new LinkedBlockingQueue<String>();
long begin = System.currentTimeMillis();
for (int i = 0; i < 10000; i++) {
logQueue.put("i=" + i);
}
long stop = System.currentTimeMillis();
logger.info("the BlockingQueue total time is:" + (stop - begin));
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31

從上述程式碼以及結果中可以明顯的看到PipeLine在“批量處理”時的優勢。
(三)適用場景
有些系統可能對可靠性要求很高,每次操作都需要立馬知道這次操作是否成功,是否資料已經寫進redis了,那這種場景就不適合。
還有的系統,可能是批量的將資料寫入redis,允許一定比例的寫入失敗,那麼這種場景就可以使用了,比如10000條一下進入redis,可能失敗了2條無所謂,後期有補償機制就行了,比如簡訊群發這種場景,如果一下群發10000條,按照第一種模式去實現,那這個請求過來,要很久才能給客戶端響應,這個延遲就太長了,如果客戶端請求設定了超時時間5秒,那肯定就丟擲異常了,而且本身群發簡訊要求實時性也沒那麼高,這時候用pipeline最好了。
(四)管道(Pipelining) VS 指令碼(Scripting)
大量 pipeline 應用場景可通過 Redis 指令碼(Redis 版本 >= 2.6)得到更高效的處理,後者在伺服器端執行大量工作。指令碼的一大優勢是可通過最小的延遲讀寫資料,讓讀、計算、寫等操作變得非常快(pipeline 在這種情況下不能使用,因為客戶端在寫命令前需要讀命令返回的結果)。
應用程式有時可能在 pipeline 中傳送 EVAL 或 EVALSHA 命令。Redis 通過 SCRIPT LOAD 命令(保證 EVALSHA 成功被呼叫)明確支援這種情況。