
KNN(三)--KD樹詳解及KD樹最近鄰演算法
一般說來,索引結構中相似性查詢有兩種基本的方式:
- 一種是範圍查詢,範圍查詢時給定查詢點和查詢距離閾值,從資料集中查詢所有與查詢點距離小於閾值的資料
- 另一種是K近鄰查詢,就是給定查詢點及正整數K,從資料集中找到距離查詢點最近的K個數據,當K=1時,它就是最近鄰查詢。
同樣,針對特徵點匹配也有兩種方法:
- 最容易的辦法就是線性掃描,也就是我們常說的窮舉搜尋,依次計算樣本集E中每個樣本到輸入例項點的距離,然後抽取出計算出來的最小距離的點即為最近鄰點。此種辦法簡單直白,但當樣本集或訓練集很大時,它的缺點就立馬暴露出來了,舉個例子,在物體識別的問題中,可能有數千個甚至數萬個SIFT特徵點,而去計算這成千上萬的特徵點與輸入例項點的距離,明顯是不足取的。
- 另外一種,就是構建資料索引,因為實際資料一般都會呈現簇狀的聚類形態,因此我們想到建立資料索引,然後再進行快速匹配。索引樹是一種樹結構索引方法,其基本思想是對搜尋空間進行層次劃分。根據劃分的空間是否有混疊可以分為Clipping和Overlapping兩種。前者劃分空間沒有重疊,其代表就是k-d樹;後者劃分空間相互有交疊,其代表為R樹。
1975年,來自斯坦福大學的Jon Louis Bentley在ACM雜誌上發表的一篇論文:Multidimensional Binary Search Trees Used for Associative Searching 中正式提出和闡述的瞭如下圖形式的把空間劃分為多個部分的k-d樹。

2.1、什麼是KD樹
Kd-樹是K-dimension tree的縮寫,是對資料點在k維空間(如二維(x,y),三維(x,y,z),k維(x1,y,z..))中劃分的一種資料結構,主要應用於多維空間關鍵資料的搜尋(如:範圍搜尋和最近鄰搜尋)。本質上說,Kd-樹就是一種平衡二叉樹。
首先必須搞清楚的是,k-d樹是一種空間劃分樹,說白了,就是把整個空間劃分為特定的幾個部分,然後在特定空間的部分內進行相關搜尋操作。想像一個三維(多維有點為難你的想象力了)空間,kd樹按照一定的劃分規則把這個三維空間劃分了多個空間,如下圖所示:

2.2、KD樹的構建
kd樹構建的虛擬碼如下圖所示:

再舉一個簡單直觀的例項來介紹k-d樹構建演算法。假設有6個二維資料點{(2,3),(5,4),(9,6),(4,7),(8,1),(7,2)},資料點位於二維空間內,如下圖所示。為了能有效的找到最近鄰,k-d樹採用分而治之的思想,即將整個空間劃分為幾個小部分,首先,粗黑線將空間一分為二,然後在兩個子空間中,細黑直線又將整個空間劃分為四部分,最後虛黑直線將這四部分進一步劃分。

6個二維資料點{(2,3),(5,4),(9,6),(4,7),(8,1),(7,2)}構建kd樹的具體步驟為:
- 確定:split域=x。具體是:6個數據點在x,y維度上的資料方差分別為39,28.63,所以在x軸上方差更大,故split域值為x;
- 確定:Node-data = (7,2)。具體是:根據x維上的值將資料排序,6個數據的中值(所謂中值,即中間大小的值)為7,所以Node-data域位資料點(7,2)。這樣,該節點的分割超平面就是通過(7,2)並垂直於:split=x軸的直線x=7;
- 確定:左子空間和右子空間。具體是:分割超平面x=7將整個空間分為兩部分:x<=7的部分為左子空間,包含3個節點={(2,3),(5,4),(4,7)};另一部分為右子空間,包含2個節點={(9,6),(8,1)};

與此同時,經過對上面所示的空間劃分之後,我們可以看出,點(7,2)可以為根結點,從根結點出發的兩條紅粗斜線指向的(5,4)和(9,6)則為根結點的左右子結點,而(2,3),(4,7)則為(5,4)的左右孩子(通過兩條細紅斜線相連),最後,(8,1)為(9,6)的左孩子(通過細紅斜線相連)。如此,便形成了下面這樣一棵k-d樹:
k-d樹的資料結構

針對上表給出的kd樹的資料結構,轉化成具體程式碼如下所示(注,本文以下程式碼分析基於Rob Hess維護的sift庫):
[cpp] view plaincopyprint?- /** a node in a k-d tree */
- struct kd_node
- {
- int ki; /**< partition key index *///關鍵點直方圖方差最大向量系列位置
- double kv; /**< partition key value *///直方圖方差最大向量系列中最中間模值
- int leaf; /**< 1 if node is a leaf, 0 otherwise */
- struct feature* features; /**< features at this node */
- int n; /**< number of features */
- struct kd_node* kd_left; /**< left child */
- struct kd_node* kd_right; /**< right child */
- };
/** a node in a k-d tree */
struct kd_node
{
int ki; /**< partition key index *///關鍵點直方圖方差最大向量系列位置
double kv; /**< partition key value *///直方圖方差最大向量系列中最中間模值
int leaf; /**< 1 if node is a leaf, 0 otherwise */
struct feature* features; /**< features at this node */
int n; /**< number of features */
struct kd_node* kd_left; /**< left child */
struct kd_node* kd_right; /**< right child */
}; 也就是說,如之前所述,kd樹中,kd代表k-dimension,每個節點即為一個k維的點。每個非葉節點可以想象為一個分割超平面,用垂直於座標軸的超平面將空間分為兩個部分,這樣遞迴的從根節點不停的劃分,直到沒有例項為止。經典的構造k-d tree的規則如下:
- 隨著樹的深度增加,迴圈的選取座標軸,作為分割超平面的法向量。對於3-d tree來說,根節點選取x軸,根節點的孩子選取y軸,根節點的孫子選取z軸,根節點的曾孫子選取x軸,這樣迴圈下去。
- 每次均為所有對應例項的中位數的例項作為切分點,切分點作為父節點,左右兩側為劃分的作為左右兩子樹。

對於n個例項的k維資料來說,建立kd-tree的時間複雜度為O(k*n*logn)。
構建完kd樹之後,如今進行最近鄰搜尋呢?從下面的動態gif圖中,你是否能看出些許端倪呢?
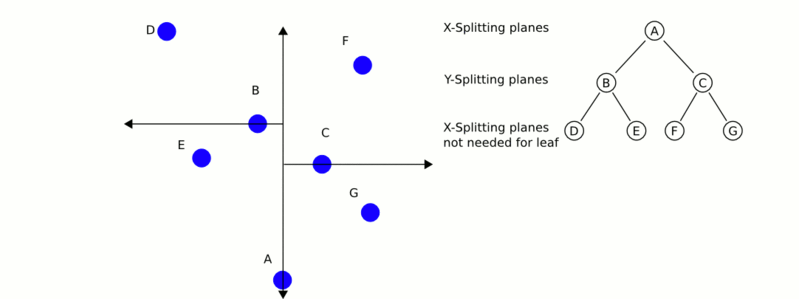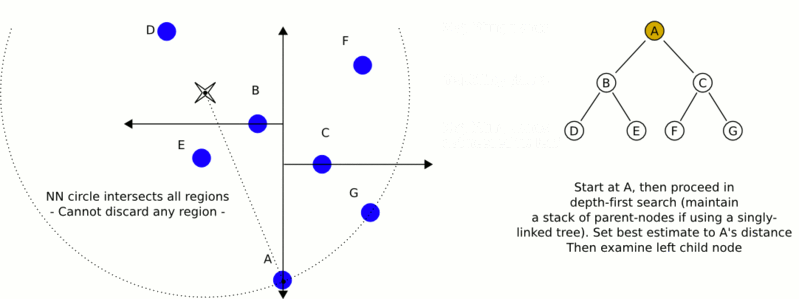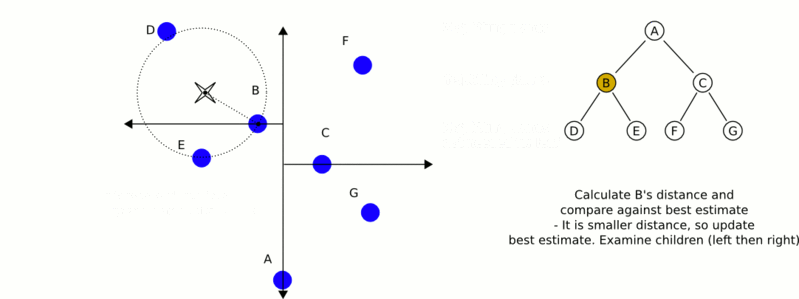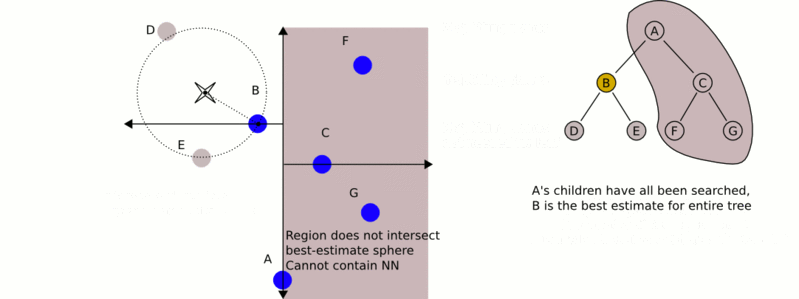
k-d樹演算法可以分為兩大部分,除了上部分有關k-d樹本身這種資料結構建立的演算法,另一部分是在建立的k-d樹上各種諸如插入,刪除,查詢(最鄰近查詢)等操作涉及的演算法。下面,咱們依次來看kd樹的插入、刪除、查詢操作。
2.3、KD樹的插入
元素插入到一個K-D樹的方法和二叉檢索樹類似。本質上,在偶數層比較x座標值,而在奇數層比較y座標值。當我們到達了樹的底部,(也就是當一個空指標出現),我們也就找到了結點將要插入的位置。生成的K-D樹的形狀依賴於結點插入時的順序。給定N個點,其中一個結點插入和檢索的平均代價是O(log2N)。
下面4副圖(來源:中國地質大學電子課件)說明了插入順序為(a) Chicago, (b) Mobile, (c) Toronto, and (d) Buffalo,建立空間K-D樹的示例:




應該清楚,這裡描述的插入過程中,每個結點將其所在的平面分割成兩部分。因比,Chicago 將平面上所有結點分成兩部分,一部分所有的結點x座標值小於35,另一部分結點的x座標值大於或等於35。同樣Mobile將所有x座標值大於35的結點以分成兩部分,一部分結點的Y座標值是小於10,另一部分結點的Y座標值大於或等於10。後面的Toronto、Buffalo也按照一分為二的規則繼續劃分。
2.4、KD樹的刪除
KD樹的刪除可以用遞迴程式來實現。我們假設希望從K-D樹中刪除結點(a,b)。如果(a,b)的兩個子樹都為空,則用空樹來代替(a,b)。否則,在(a,b)的子樹中尋找一個合適的結點來代替它,譬如(c,d),則遞迴地從K-D樹中刪除(c,d)。一旦(c,d)已經被刪除,則用(c,d)代替(a,b)。假設(a,b)是一個X識別器,那麼,它得替代節點要麼是(a,b)左子樹中的X座標最大值的結點,要麼是(a,b)右子樹中x座標最小值的結點。 也就是說,跟普通二叉樹(包括如下圖所示的紅黑樹)結點的刪除是同樣的思想:用被刪除節點A的左子樹的最右節點或者A的右子樹的最左節點作為替代A的節點(比如,下圖紅黑樹中,若要刪除根結點26,第一步便是用23或28取代根結點26)。當(a,b)的右子樹為空時,找到(a,b)左子樹中具有x座標最大的結點,譬如(c,d),將(a,b)的左子樹放到(c,d)的右子樹中,且在樹中從它的上一層遞迴地應用刪除過程(也就是(a,b)的左子樹) 。 下面來舉一個實際的例子(來源:中國地質大學電子課件,原課件錯誤已經在下文中訂正),如下圖所示,原始影象及對應的kd樹,現在要刪除圖中的A結點,請看一系列刪除步驟: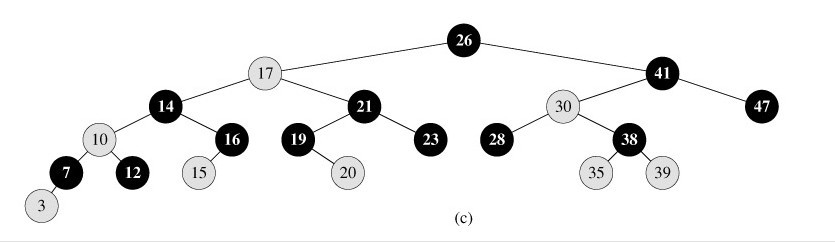
要刪除上圖中結點A,選擇結點A的右子樹中X座標值最小的結點,這裡是C,C成為根,如下圖:
從C的右子樹中找出一個結點代替先前C的位置,
這裡是D,並將D的左子樹轉為它的右子樹,D代替先前C的位置,如下圖:
在D的新右子樹中,找X座標最小的結點,這裡為H,H代替D的位置,
在D的右子樹中找到一個Y座標最小的值,這裡是I,將I代替原先H的位置,從而A結點從圖中順利刪除,如下圖所示:
從一個K-D樹中刪除結點(a,b)的問題變成了在(a,b)的子樹中尋找x座標為最小的結點。不幸的是尋找最小x座標值的結點比二叉檢索樹中解決類似的問題要複雜得多。特別是雖然最小x座標值的結點一定在x識別器的左子樹中,但它同樣可在y識別器的兩個子樹中。因此關係到檢索,且必須注意檢索座標,以使在每個奇數層僅檢索2個子樹中的一個。
從K-D樹中刪除一個結點是代價很高的,很清楚刪除子樹的根受到子樹中結點個數的限制。用TPL(T)表示樹T總的路徑長度。可看出樹中子樹大小的總和為TPL(T)+N。 以隨機方式插入N個點形成樹的TPL是O(N*log2N),這就意味著從一個隨機形成的K-D樹中刪除一個隨機選取的結點平均代價的上界是O(log2N) 。
2.5、KD樹的最近鄰搜尋演算法
現實生活中有許多問題需要在多維資料的快速分析和快速搜尋,對於這個問題最常用的方法是所謂的kd樹。在k-d樹中進行資料的查詢也是特徵匹配的重要環節,其目的是檢索在k-d樹中與查詢點距離最近的資料點。在一個N維的笛卡兒空間在兩個點之間的距離是由下述公式確定:

void innerGetClosest(NODE* pNode, PT point, PT& res, int& nMinDis)
{
if (NULL == pNode)
return;
int nCurDis = abs(point.x - pNode->pt.x) + abs(point.y - pNode->pt.y);
if (nMinDis < 0 || nCurDis < nMinDis)
{
nMinDis = nCurDis;
res = pNode->pt;
}
if (pNode->splitX && point.x <= pNode->pt.x || !pNode->splitX && point.y <= pNode->pt.y)
innerGetClosest(pNode->pLft, point, res, nMinDis);
else
innerGetClosest(pNode->pRgt, point, res, nMinDis);
int rang = pNode->splitX ? abs(point.x - pNode->pt.x) : abs(point.y - pNode->pt.y);
if (rang > nMinDis)
return;
NODE* pGoInto = pNode->pLft;
if (pNode->splitX && point.x > pNode->pt.x || !pNode->splitX && point.y > pNode->pt.y)
pGoInto = pNode->pRgt;
innerGetClosest(pGoInto, point, res, nMinDis);
}下面,以兩個簡單的例項(例子來自影象區域性不變特性特徵與描述一書)來描述最鄰近查詢的基本思路。
2.5.1、舉例:查詢點(2.1,3.1)
星號表示要查詢的點(2.1,3.1)。通過二叉搜尋,順著搜尋路徑很快就能找到最鄰近的近似點,也就是葉子節點(2,3)。而找到的葉子節點並不一定就是最鄰近的,最鄰近肯定距離查詢點更近,應該位於以查詢點為圓心且通過葉子節點的圓域內。為了找到真正的最近鄰,還需要進行相關的‘回溯'操作。也就是說,演算法首先沿搜尋路徑反向查詢是否有距離查詢點更近的資料點。
以查詢(2.1,3.1)為例:
- 二叉樹搜尋:先從(7,2)點開始進行二叉查詢,然後到達(5,4),最後到達(2,3),此時搜尋路徑中的節點為<(7,2),(5,4),(2,3)>,首先以(2,3)作為當前最近鄰點,計算其到查詢點(2.1,3.1)的距離為0.1414,
- 回溯查詢:在得到(2,3)為查詢點的最近點之後,回溯到其父節點(5,4),並判斷在該父節點的其他子節點空間中是否有距離查詢點更近的資料點。以(2.1,3.1)為圓心,以0.1414為半徑畫圓,如下圖所示。發現該圓並不和超平面y = 4交割,因此不用進入(5,4)節點右子空間中(圖中灰色區域)去搜索;
- 最後,再回溯到(7,2),以(2.1,3.1)為圓心,以0.1414為半徑的圓更不會與x = 7超平面交割,因此不用進入(7,2)右子空間進行查詢。至此,搜尋路徑中的節點已經全部回溯完,結束整個搜尋,返回最近鄰點(2,3),最近距離為0.1414。

2.5.2、舉例:查詢點(2,4.5)
一個複雜點了例子如查詢點為(2,4.5),具體步驟依次如下:
- 同樣先進行二叉查詢,先從(7,2)查詢到(5,4)節點,在進行查詢時是由y = 4為分割超平面的,由於查詢點為y值為4.5,因此進入右子空間查詢到(4,7),形成搜尋路徑<(7,2),(5,4),(4,7)>,但(4,7)與目標查詢點的距離為3.202,而(5,4)與查詢點之間的距離為3.041,所以(5,4)為查詢點的最近點;
- 以(2,4.5)為圓心,以3.041為半徑作圓,如下圖所示。可見該圓和y = 4超平面交割,所以需要進入(5,4)左子空間進行查詢,也就是將(2,3)節點加入搜尋路徑中得<(7,2),(2,3)>;於是接著搜尋至(2,3)葉子節點,(2,3)距離(2,4.5)比(5,4)要近,所以最近鄰點更新為(2,3),最近距離更新為1.5;
- 回溯查詢至(5,4),直到最後回溯到根結點(7,2)的時候,以(2,4.5)為圓心1.5為半徑作圓,並不和x = 7分割超平面交割,如下圖所示。至此,搜尋路徑回溯完,返回最近鄰點(2,3),最近距離1.5。

上述兩次例項表明,當查詢點的鄰域與分割超平面兩側空間交割時,需要查詢另一側子空間,導致檢索過程複雜,效率下降。
一般來講,最臨近搜尋只需要檢測幾個葉子結點即可,如下圖所示:但是,如果當例項點的分佈比較糟糕時,幾乎要遍歷所有的結點,如下所示:

研究表明N個節點的K維k-d樹搜尋過程時間複雜度為:tworst=O(kN1-1/k)。
同時,以上為了介紹方便,討論的是二維或三維情形。但在實際的應用中,如SIFT特徵向量128維,SURF特徵向量64維,維度都比較大,直接利用k-d樹快速檢索(維數不超過20)的效能急劇下降,幾乎接近貪婪線性掃描。假設資料集的維數為D,一般來說要求資料的規模N滿足N»2D,才能達到高效的搜尋。所以這就引出了一系列對k-d樹演算法的改進:BBF演算法,和一系列M樹、VP樹、MVP樹等高維空間索引樹(下文2.6節kd樹近鄰搜尋演算法的改進:BBF演算法,與2.7節球樹、M樹、VP樹、MVP樹)。
2.6、kd樹近鄰搜尋演算法的改進:BBF演算法
咱們順著上一節的思路,參考統計學習方法一書上的內容,再來總結下kd樹的最近鄰搜尋演算法:
輸入:以構造的kd樹,目標點x;輸出:x 的最近鄰
演算法步驟如下:
- 在kd樹種找出包含目標點x的葉結點:從根結點出發,遞迴地向下搜尋kd樹。若目標點x當前維的座標小於切分點的座標,則移動到左子結點,否則移動到右子結點,直到子結點為葉結點為止。
- 以此葉結點為“當前最近點”。
- 遞迴的向上回溯,在每個結點進行以下操作:
(a)如果該結點儲存的例項點比當前最近點距離目標點更近,則更新“當前最近點”,也就是說以該例項點為“當前最近點”。
(b)當前最近點一定存在於該結點一個子結點對應的區域,檢查子結點的父結點的另一子結點對應的區域是否有更近的點。具體做法是,檢查另一子結點對應的區域是否以目標點位球心,以目標點與“當前最近點”間的距離為半徑的圓或超球體相交:
如果相交,可能在另一個子結點對應的區域記憶體在距目標點更近的點,移動到另一個子結點,接著,繼續遞迴地進行最近鄰搜尋;
如果不相交,向上回溯。 - 當回退到根結點時,搜尋結束,最後的“當前最近點”即為x 的最近鄰點。
如果例項點是隨機分佈的,那麼kd樹搜尋的平均計算複雜度是O(NlogN),這裡的N是訓練例項樹。所以說,kd樹更適用於訓練例項數遠大於空間維數時的k近鄰搜尋,當空間維數接近訓練例項數時,它的效率會迅速下降,一降降到“解放前”:線性掃描的速度。
也正因為上述k最近鄰搜尋演算法的第4個步驟中的所述:“回退到根結點時,搜尋結束”,每個最近鄰點的查詢比較完成過程最終都要回退到根結點而結束,而導致了許多不必要回溯訪問和比較到的結點,這些多餘的損耗在高維度資料查詢的時候,搜尋效率將變得相當之地下,那有什麼辦法可以改進這個原始的kd樹最近鄰搜尋演算法呢?
從上述標準的kd樹查詢過程可以看出其搜尋過程中的“回溯”是由“查詢路徑”決定的,並沒有考慮查詢路徑上一些資料點本身的一些性質。一個簡單的改進思路就是將“查詢路徑”上的結點進行排序,如按各自分割超平面(也稱bin)與查詢點的距離排序,也就是說,回溯檢查總是從優先順序最高(Best Bin)的樹結點開始。
針對此BBF機制,讀者Feng&書童點評道:
- 在某一層,分割面是第ki維,分割值是kv,那麼 abs(q[ki]-kv) 就是沒有選擇的那個分支的優先順序,也就是計算的是那一維上的距離;
- 同時,從優先佇列裡面取節點只在某次搜尋到葉節點後才發生,計算過距離的節點不會出現在佇列的,比如1~10這10個節點,你第一次搜尋到葉節點的路徑是1-5-7,那麼1,5,7是不會出現在優先佇列的。換句話說,優先佇列裡面存的都是查詢路徑上節點對應的相反子節點,比如:搜尋左子樹,就把對應這一層的右節點存進佇列。
如此,就引出了本節要討論的kd樹最近鄰搜尋演算法的改進:BBF(Best-Bin-First)查詢演算法,它是由發明sift演算法的David Lowe在1997的一篇文章中針對高維資料提出的一種近似演算法,此演算法能確保優先檢索包含最近鄰點可能性較高的空間,此外,BBF機制還設定了一個執行超時限定。採用了BBF查詢機制後,kd樹便可以有效的擴充套件到高維資料集上。
虛擬碼如下圖所示(圖取自影象區域性不變特性特徵與描述一書):

還是以上面的查詢(2,4.5)為例,搜尋的演算法流程為:
- 將(7,2)壓人優先佇列中;
- 提取優先佇列中的(7,2),由於(2,4.5)位於(7,2)分割超平面的左側,所以檢索其左子結點(5,4)。同時,根據BBF機制”搜尋左/右子樹,就把對應這一層的兄弟結點即右/左結點存進佇列”,將其(5,4)對應的兄弟結點即右子結點(9,6)壓人優先佇列中,此時優先佇列為{(9,6)},最佳點為(7,2);然後一直檢索到葉子結點(4,7),此時優先佇列為{(2,3),(9,6)},“最佳點”則為(5,4);
- 提取優先順序最高的結點(2,3),重複步驟2,直到優先佇列為空。


2.7、球樹、M樹、VP樹、MVP樹
2.7.1、球樹
咱們來針對上文內容總結回顧下,針對下面這樣一棵kd樹:

現要找它的最近鄰。
通過上文2.5節,總結來說,我們已經知道:
1、為了找到一個給定目標點的最近鄰,需要從樹的根結點開始向下沿樹找出目標點所在的區域,如下圖所示,給定目標點,用星號標示,我們似乎一眼看出,有一個點離目標點最近,因為它落在以目標點為圓心以較小長度為半徑的虛線圓內,但為了確定是否可能還村莊一個最近的近鄰,我們會先檢查葉節點的同胞結點,然葉節點的同胞結點在圖中所示的陰影部分,虛線圓並不與之相交,所以確定同胞葉結點不可能包含更近的近鄰。

2、於是我們回溯到父節點,並檢查父節點的同胞結點,父節點的同胞結點覆蓋了圖中所有橫線X軸上的區域。因為虛線圓與右上方的矩形(KD樹把二維平面劃分成一個一個矩形)相交...
如上,我們看到,KD樹是可用於有效尋找最近鄰的一個樹結構,但這個樹結構其實並不完美,當處理不均勻分佈的資料集時便會呈現出一個基本衝突:既邀請樹有完美的平衡結構,又要求待查詢的區域近似方形,但不管是近似方形,還是矩形,甚至正方形,都不是最好的使用形狀,因為他們都有角。

什麼意思呢?就是說,在上圖中,如果黑色的例項點離目標點星點再遠一點,那麼勢必那個虛線圓會如紅線所示那樣擴大,以致與左上方矩形的右下角相交,既然相交了,那麼勢必又必須檢查這個左上方矩形,而實際上,最近的點離星點的距離很近,檢查左上方矩形區域已是多餘。於此我們看見,KD樹把二維平面劃分成一個一個矩形,但矩形區域的角卻是個難以處理的問題。
解決的方案就是使用如下圖所示的球樹:

先從球中選擇一個離球的中心最遠的點,然後選擇第二個點離第一個點最遠,將球中所有的點分配到離這兩個聚類中心最近的一個上,然後計算每個聚類的中心,以及聚類能夠包含它所有資料點所需的最小半徑。這種方法的優點是分裂一個包含n個殊絕點的球的成本只是隨n呈線性增加。

使用球樹找出給定目標點的最近鄰方法是,首先自上而下貫穿整棵樹找出包含目標點所在的葉子,並在這個球裡找出與目標點最靠近的點,這將確定出目標點距離它的最近鄰點的一個上限值,然後跟KD樹查詢一樣,檢查同胞結點,如果目標點到同胞結點中心的距離超過同胞結點的半徑與當前的上限值之和,那麼同胞結點裡不可能存在一個更近的點;否則的話,必須進一步檢查位於同胞結點以下的子樹。
如下圖,目標點還是用一個星表示,黑色點是當前已知的的目標點的最近鄰,灰色球裡的所有內容將被排除,因為灰色球的中心點離的太遠,所以它不可能包含一個更近的點,像這樣,遞迴的向樹的根結點進行回溯處理,檢查所有可能包含一個更近於當前上限值的點的球。

球樹是自上而下的建立,和KD樹一樣,根本問題就是要找到一個好的方法將包含資料點集的球分裂成兩個,在實踐中,不必等到葉子結點只有兩個胡資料點時才停止,可以採用和KD樹一樣的方法,一旦結點上的資料點打到預先設定的最小數量時,便可提前停止建樹過程。
也就是上面所述,先從球中選擇一個離球的中心最遠的點,然後選擇第二個點離第一個點最遠,將球中所有的點分配到離這兩個聚類中心最近的一個上,然後計算每個聚類的中心,以及聚類能夠包含它所有資料點所需的最小半徑。這種方法的優點是分裂一個包含n個殊絕點的球的成本只是隨n呈線性增加(注:本小節內容主要來自參考條目19:資料探勘實用機器學習技術,[紐西蘭]Ian H.Witten 著,第4章4.7節)。
2.7.2、VP樹與MVP樹簡介
高維特徵向量的距離索引問題是基於內容的影象檢索的一項關鍵技術,目前經常採用的解決辦法是首先對高維特徵空間做降維處理,然後採用包括四叉樹、kd樹、R樹族等在內的主流多維索引結構,這種方法的出發點是:目前的主流多維索引結構在處理維數較低的情況時具有比較好的效率,但對於維數很高的情況則顯得力不從心(即所謂的維數危機) 。
實驗結果表明當特徵空間的維數超過20 的時候,效率明顯降低,而視覺化特徵往往採用高維向量描述,一般情況下可以達到10^2的量級,甚至更高。在表示影象視覺化特徵的高維向量中各維資訊的重要程度是不同的,通過降維技術去除屬於次要資訊的特徵向量以及相關性較強的特徵向量,從而降低特徵空間的維數,這種方法已經得到了一些實際應用。
然而這種方法存在不足之處採用降維技術可能會導致有效資訊的損失,尤其不適合於處理特徵空間中的特徵向量相關性很小的情況。另外主流的多維索引結構大都針對歐氏空間,設計需要利用到歐氏空間的幾何性質,而影象的相似性計算很可能不限於基於歐氏距離。這種情況下人們越來越關注基於距離的度量空間高維索引結構可以直接應用於高維向量相似性查詢問題。
度量空間中物件之間的距離度量只能利用三角不等式性質,而不能利用其他幾何性質。向量空間可以看作由實數座標串組成的特殊度量空間,目前針對度量空間的高維索引問題提出的索引結構有很多種大致可以作如下分類,如下圖所示:
其中,VP樹和MVP樹中特徵向量的舉例表示為:


讀者點評:
- UESTC_HN_AY_GUOBO:現在主要是在kdtree的基礎上有了mtree或者mvptree,其實關鍵還是pivot的選擇,以及度量空間中演算法怎麼減少距離計算;
- mandycool:mvp-tree,是利用三角形不等式來縮小搜尋區域的,不過mvp-tree的目標稍有不同,查詢的是到query點的距離小於某個值r的點;另外作者test的資料集只有20維,不知道上百維以後效果如何,而減少距離計算的一個思路是做embedding,通過不等式排除掉一部分點。
更多內容請參見論文1:DIST ANCE-BASED INDEXING FOR HIGH-DIMENSIONAL METRIC SP ACES,作者:Tolga Bozkaya & Meral Ozsoyoglu,及論文2:基於度量空間高維索引結構VP-tree及MVP-tree的影象檢索,王志強,甘國輝,程起敏。
當然,如果你覺得上述論文還不夠滿足你胃口的話,這裡有一大堆nearest neighbor algorithms相關的論文可供你看::Spill-Trees,An investigation of practical approximate nearest neighbor algorithms)。