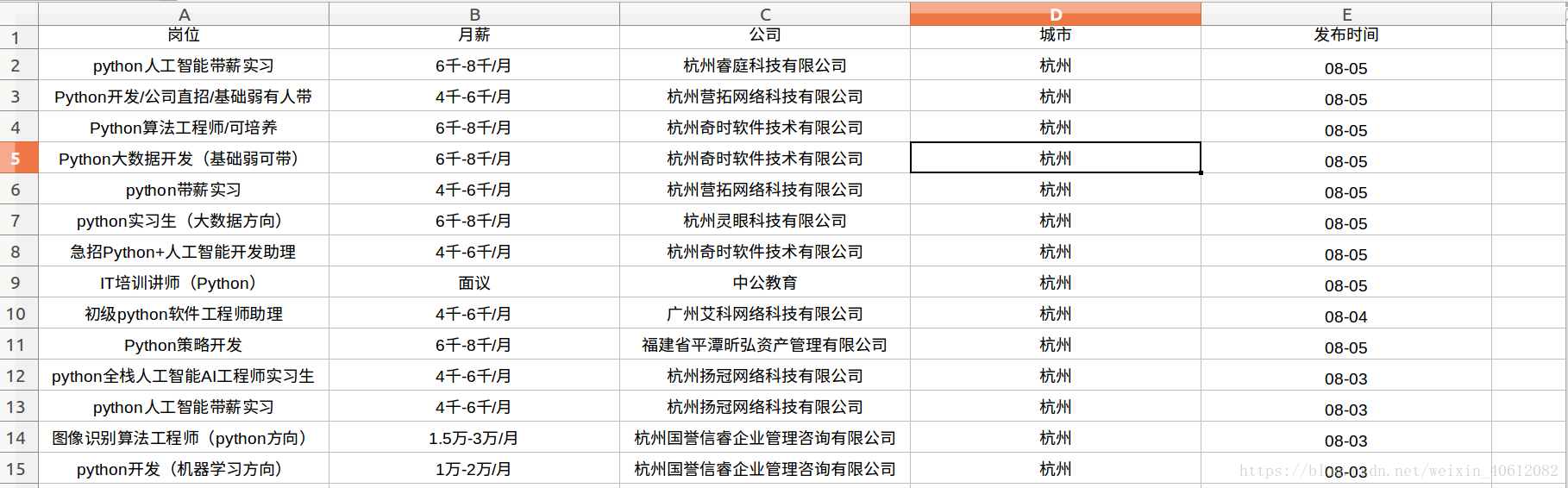
python3 爬蟲 爬取智聯招聘崗位資訊
阿新 • • 發佈:2019-02-16
這套程式基於python3 ,使用requests和re正則表示式,只需要將程式儲存為.py檔案後,即可將抓取到的資料儲存到指定路徑的Excel檔案中。程式在終端中啟動,啟動命令:
#python3 檔名.py 關鍵字 城市
python3 zhilian.py python 杭州
程式碼如下:
# coding:utf-8
import requests
import re
import xlwt
import sys,os
workbook = xlwt.Workbook(encoding='utf-8')
booksheet = workbook.add_sheet('Sheet 1' 爬取結果如下: