
利用隨機森林對特徵重要性進行評估
阿新 • • 發佈:2019-02-16
前言
隨機森林是以決策樹為基學習器的整合學習演算法。隨機森林非常簡單,易於實現,計算開銷也很小,更令人驚奇的是它在分類和迴歸上表現出了十分驚人的效能,因此,隨機森林也被譽為“代表整合學習技術水平的方法”。
本文是對隨機森林如何用在特徵選擇上做一個簡單的介紹。
隨機森林(RF)簡介
只要瞭解決策樹的演算法,那麼隨機森林是相當容易理解的。隨機森林的演算法可以用如下幾個步驟概括:
- 用有抽樣放回的方法(bootstrap)從樣本集中選取n個樣本作為一個訓練集
- 用抽樣得到的樣本集生成一棵決策樹。在生成的每一個結點:
- 隨機不重複地選擇d個特徵
- 利用這d個特徵分別對樣本集進行劃分,找到最佳的劃分特徵(可用基尼係數、增益率或者資訊增益判別)
- 重複步驟1到步驟2共k次,k即為隨機森林中決策樹的個數。
- 用訓練得到的隨機森林對測試樣本進行預測,並用票選法決定預測的結果。
下圖比較直觀地展示了隨機森林演算法(圖片出自文獻2):
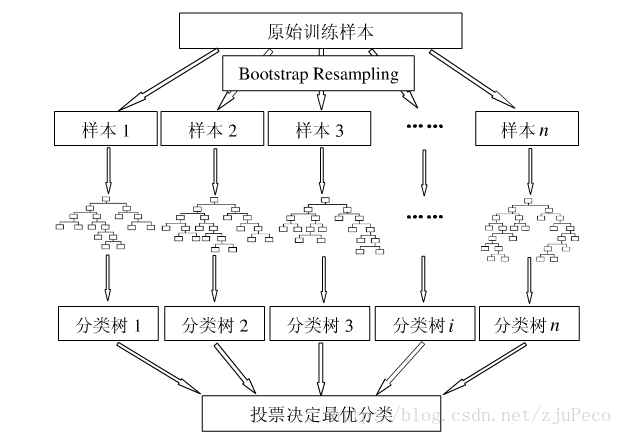
沒錯,就是這個到處都是隨機取值的演算法,在分類和迴歸上有著極佳的效果,是不是覺得強的沒法解釋~
然而本文的重點不是這個,而是接下來的特徵重要性評估。
特徵重要性評估
現實情況下,一個數據集中往往有成百上前個特徵,如何在其中選擇比結果影響最大的那幾個特徵,以此來縮減建立模型時的特徵數是我們比較關心的問題。這樣的方法其實很多,比如主成分分析,lasso等等。不過,這裡我們要介紹的是用隨機森林來對進行特徵篩選。
用隨機森林進行特徵重要性評估的思想其實很簡單,說白了就是看看每個特徵在隨機森林中的每顆樹上做了多大的貢獻,然後取個平均值,最後比一比特徵之間的貢獻大小。
好了,那麼這個貢獻是怎麼一個說法呢?通常可以用基尼指數(Gini index)或者袋外資料(OOB)錯誤率作為評價指標來衡量。
我們這裡只介紹用基尼指數來評價的方法,想了解另一種方法的可以參考文獻2。
我們將變數重要性評分(variable importance measures)用 來表示,將Gini指數用來表示,假設有個特徵,現在要計算出每個特徵的Gini指數評分,亦即第個特徵在RF所有決策樹中節點分裂不純度的平均改變數。
Gini指數的計算公式為
其中,表示有個類別,表示節點中類別所佔的比例。
直觀地說,就是隨便從節點中隨機抽取兩個樣本,其類別標記不一致的概率。
特徵
其中,和分別表示分枝後兩個新節點的指數。
如果,特徵在決策樹中出現的節點在集合中,那麼在第顆樹的重要性為
假設中共有顆樹,那麼