
hbase叢集負載均衡與高效能的關鍵——region分割與合併
HBase通過對錶的Region數量實現簡單的負載均衡,官方認為這種實現是簡潔而高效的,能滿足絕大部分的需求。接下來和大家和分享一下自動的負載均衡和手動控制的負載均衡。如下幾種情況時,當前叢集不會執行負載均衡:
1、master沒有被初始化
2、當前已有負載均衡方法在執行
3、有region處於splitting狀態
4、叢集中有死掉的region server
第一部分、分割(split)
split是切分、切割、分裂的意思,用來描述region的切分行為。
【與region有關的儲存結構介紹】
hbase中的Region是一張表的子集,也就是說把一張表在水平方向上切割成若干個region。一張表一開始的時候只有一個region(區域),隨著資料量的增長,會自動(或手動)切分出來越來越多的region。HBase中針對表採用”Range分割槽”,把rowkey的完整區間切割成一個個的”Key Range” ,每一個”Key Range”稱為一個Region,所以說region其實是按照連續的rowKey儲存的區間。
不同Region分佈到不同Region Server上,region是Hbase叢集分佈資料的最小單位,或者說region是HBase中分散式儲存和負載均衡的最小單元,但不是儲存的最小單元。儲存的最小單元是store file(也叫Hfile)。Store File是存放資料的地方,裡面存的是一個列簇的資料,每一條資料都是key-value,store file的內部是按照rowkey有序排列的,但是store file之間是無序的。
【為什麼要切分region】
更大的Region使得我們叢集上的Region的總數量更少,而數量更少的region能讓叢集執行更順暢。如果region數目太多就會造成讀寫效能下降,也會增加ZooKeeper的負擔。但是region數目太少會妨礙可擴充套件性,降低讀寫併發效能,會導致壓力不夠分散。綜合權衡叢集的負載和效能,需要把過大的region做切分,切成更小的region分散到更多regionServer上去,以緩解region server過大的壓力,從而均衡每一臺region server負載。根據寫請求量的情況,region數量在20~200個之間可以提高叢集穩定性、提升讀寫效能。
【與切分region有關的配置】
對於線上型應用來說,store file(hbase.hregion.max.filesize)的大小一般是線下型應用設定引數的兩倍。
監控Region Server中所有Memstore的大小總和是否達到了上限(hbase.regionserver.global.memstore.upperLimit * hbase_heapsize,預設40%的JVM記憶體使用量),超過會導致不良後果,如伺服器反應遲鈍或compact風暴。
hbase.regionserver.global.memstore.upperLimit 的預設值為0.4,即JVM記憶體的40%.
【region切分策略】
常用的有三種策略:
(1)ConstantSizeRegionSplitPolicy:小於0.94版本的hbase只有這個分裂策略。當region中的一個store(對應的是一個列簇的一個 Hfile )超過了配置引數hbase.hregion.max.filesize 的閾值時拆分成兩個。region拆分線是最大storefile的中間rowkey。
(2)IncreasingToUpperBoundRegionSplitPolicy:這個是0.94~1.x版本預設的分裂策略。按固定長度分割region,固定長度取值優先獲取table的”MAX_FILESIZE” 值,若沒有設定該屬性,則採用在hbase-site.xml中配置的hbase.hregion.max.filesize值,從0.94版本開始,這個值的預設值已經被調整為:10 * 1024 * 1024 * 1024L 也就是10G,網上很多關於 hbase.hregion.max.filesize 預設值 1G的文章應該都是基於0.92的hbase的。採用該策略後,當table的某一region中的某一store大小超過了預定的最大固定長度時,對該region進行split。切割點(splitPoint)演算法的選擇是依據“資料對半”原則找到該region的最大store的中間長度的rowkey進行切割。不論是哪種切分策略,ConstantSizeRegionSplitPolicy、IncreasingToUpperBoundRegionSplitPolicy 或 SteppingSplitPolicy,對切分點的定義都是一致的。但是使用者手動執行切分時是可以指定切分點進行切分的。
(3)SteppingSplitPolicy: 2.x版本的預設切分策略。這種策略的切分閾值發生了變化,相比IncreasingToUpperBoundRegionSplitPolicy簡單了一些,依然和待分裂region所屬表在當前RegionServer上的region個數有關係:如果region個數等於1,切分閾值為flush size * 2,否則為MaxRegionFileSize。這種策略對於大叢集中的大表、小表會比IncreasingToUpperBoundRegionSplitPolicy更加友好,小表不會再產生大量的小region,而是適可而止。
【 拆分region的步驟 】
Region的拆分操作是不可見的,因為Master不會參與其中,REGION SERVER負責拆分。RegionServer拆分region的步驟是:
將待切割的region下線 ==> 拆分成2個子region ==> 將子region加入到hbase:meta中,再將它們加入到原本的RegionServer中 ==> RegionServer將本機最新的region資訊彙報給Master
[官方文件的切分過程描述]
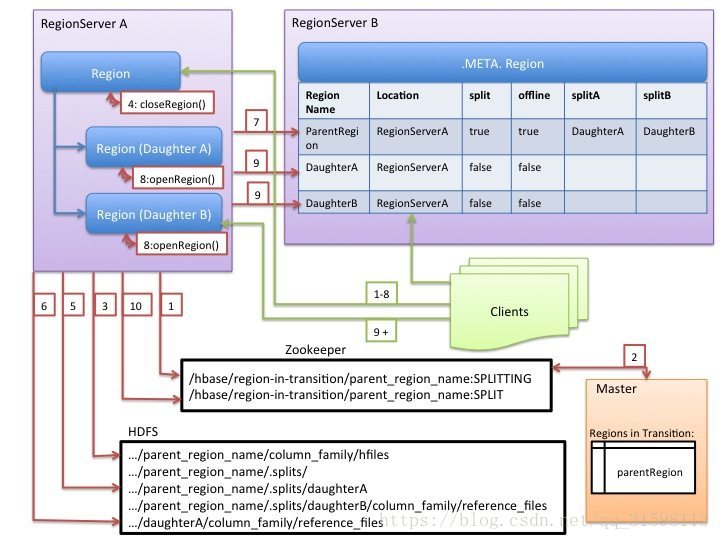
1. RegionServer decides locally to split the region, and prepares the split. As a first step, it creates a znode in zookeeper under /hbase/region-in-transition/region-name in SPLITTING state.
2. The Master learns about this znode, since it has a watcher for the parent region-in-transition znode.
3. RegionServer creates a sub-directory named “.splits” under the parent’s region directory in HDFS.
4. RegionServer closes the parent region, forces a flush of the cache and marks the region as offline in its local data structures. At this point, client requests coming to the parent region will throw NotServingRegionException. The client will retry with some backoff.
5. RegionServer create the region directories under .splits directory, for daughter regions A and B, and creates necessary data structures. Then it splits the store files, in the sense that it creates two Reference files per store file in the parent region. Those reference files will point to the parent regions files.
6. RegionServer creates the actual region directory in HDFS, and moves the reference files for each daughter.
7. RegionServer sends a Put request to the .META. table, and sets the parent as offline in the .META. table and adds information about daughter regions. At this point, there won’t be individual entries in .META. for the daughters. Clients will see the parent region is split if they scan .META., but won’t know about the daughters until they appear in .META.. Also, if this Put to .META. succeeds, the parent will be effectively split. If the RegionServer fails before this RPC succeeds, Master and the next region server opening the region will clean dirty state about the region split. After the .META. update, though, the region split will be rolled-forward by Master.
8. RegionServer opens daughters in parallel to accept writes.
9. RegionServer adds the daughters A and B to .META. together with information that it hosts the regions. After this point, clients can discover the new regions, and issue requests to the new region. Clients cache the .META. entries locally, but when they make requests to the region server or .META., their caches will be invalidated, and they will learn about the new regions from .META..
10. RegionServer updates znode /hbase/region-in-transition/region-name in zookeeper to state SPLIT, so that the master can learn about it. The balancer can freely re-assign the daughter regions to other region servers if it chooses so.
11. After the split, meta and HDFS will still contain references to the parent region. Those references will be removed when compactions in daughter regions rewrite the data files. Garbage collection tasks in the master periodically checks whether the daughter regions still refer to parents files. If not, the parent region will be removed.
再附一個國外的大神對region切分的描述——
How Region Split works in HBase. Short Description:
Article explains a region split in HBase through the following sequence of events.
Article
A region is decided to be split when store file size goes above hbase.hregion.max.filesize or according to defined region split policy.
At this point this region is divided into two by region server.
Region server creates two reference files for these two daughter regions.
These reference files are stored in a new directory called splits under parent directory.
Exactly at this point, parent region is marked as closed or offline so no client tries to read or write to it.
Now region server creates two new directories in splits directory for these daughter regions.
If steps till 6 are completed successfully, Region server moves both daughter region directories under table directory.
The META table is now informed of the creation of two new regions, along with an update in the entry of parent region that it has now been split and is offline. (OFFLINE=true , SPLIT=true)
The reference files are very small files containing only the key at which the split happened and also whether it represents top half or bottom half of the parent region.
There is a class called “HalfHFileReader”which then utilizes these two reference files to read the original data file of parent region and also to decide as which half of the file has to be read.
Both regions are now brought online by region server and start serving requests to clients.
As soon as the daughter regions come online, a compaction is scheduled which rewrites the HFile of parent region into two HFiles independent for both daughter regions.
As this process in step 12 completes, both the HFiles cleanly replace their respective reference files. The compaction activity happens under .tmp directory of daughter regions.
With the successful completion till step 13, the parent region is now removed from META and all its files and directories marked for deletion.
Finally Master server is informed by this Region server about two new regions getting born. Master now decides the fate of the two regions as to let them run on same region server or have them travel to another one.
【禁用自動切分region,改用手動切分】
上面說的都是自動切分來實現的負載均衡。建議在生產環境中禁用自動的split(或者將Region設定的大一點),然後手動切割region,可以在晚上或者業務不忙(例如沒有大量寫操作)的時候手動執行split。
執行split操作後,Hbase內部的邏輯是:
第一輪split,遍歷所有region的資訊,如果region size大於某值(比如4G)則split該region;
如果一輪後沒有大於該值的region則結束,如果還有大於該值的region則繼續新一輪split,直到沒有region大於該閾值為止。
如何判斷split已完成:檢查hdfs上老的region目錄是否已被清除來判斷split是否已完成。
【合併region簡介】
既然有切分region的,那麼就有合併region的。
緣由:如果region數目太多了,會導致效能下降,也會增加ZooKeeper的負擔
hbase shell上的reqion合併操作:
hbase> merge_region ‘ENCODED_REGIONNAME’, ‘ENCODED_REGIONNAME’
hbase> merge_region ‘ENCODED_REGIONNAME’, ‘ENCODED_REGIONNAME’, true # 強制合併
# 其中’ENCODED_REGIONNAME’表示region Id中的hashcode,他是全域性唯一的分割槽名,比如本文案例中的 353a385f28af52ed47e675f18242bbf8
# 能合併startkey endkey相鄰的region,不相鄰的只能強制合併(加引數true即可)
【手動切割region案例】
在hbase shell中手動切割region來實現負載均衡。
hbase shell中的split語法:
split ‘tableName’
split ‘namespace:tableName’
split ‘regionName’ # format: ‘tableName,startKey,id’
split ‘tableName’, ‘splitKey’
split ‘regionName’, ‘splitKey’
—— splitKey 表示從哪一行開始切分
下面以 defualt:test_tony 表為例演示手動切分此表。此表在hbase的webUI上面檢視到,有4個region,分別分佈在4個Region Server上。
hbase(main):022:0> list_namespace
NAMESPACE
default
hbase
users
3 row(s) in 0.0100 seconds
hbase(main):023:0> list_namespace_tables ‘hbase’
TABLE
meta
namespace
2 row(s) in 0.0100 seconds
手動切割以前,記錄數有231條。執行手動切割後會有變化,請往下看
hbase(main):024:0> count ‘hbase:meta’, INTERVAL => 23
Current count: 23, row: users:usertb,7FF70F148964809C8475FEE655005CE3,1523397818177.8c487f00838ae5e9e19ffced7f8914e8.
Current count: 46, row: users:usertb,2FFD4264F7EC7DED66CACB1A2D3AE8EA,1511941432094.8b142ad572b93d65e303a6a5ec5da5a3.
Current count: 69, row: users:usertb,7BF84538F6A96E274651966AF3A6EA87,1515183873848.695d98fb0a9cac2d640c2906444a32e2.
Current count: 92, row: users:usertb,BC0049FADE2ABE2F54CBD8244A861B85,1519967361809.8a7c89d7063118fe9b0e0dd1c9eafd2e.
Current count: 115, row: users:my_table,001|,1511873110944.69e71f4ba7a0f420eb287431b925b377.
Current count: 138, row: users:my_table,0DF7986,1515671013211.2157bae66326fc85b88d2f796f59613a.
Current count: 161, row: users:my_table,59F81618,1515652416016.28d28f08bef06894870ef39ac72482b6.
Current count: 184, row: users:my_table,93FBFF13995C6E8BF2C5ABB244E16B98,1512522023490.9fb718ce9e15a1bf8e4824248b761b45.
Current count: 207, row: users:my_table,E8128B65E40AA34CDC10918689DB0839,1512136535400.74654b61bb4257f7b4fdabc08dceecdd.
Current count: 230, row: test_tony,6E79D9382F405FB9132FA20EDF15CB0B,1524732581444.48f77b080e02cb8e9e652ec7467bfa76.
231 row(s) in 0.0590 seconds
=> 231
在hbase shell上執行手動切割。在本案中,不指定切割哪個region或按照哪個rowkey來做切割點,只是粗粒度地切分表
hbase(main):001:0> split ‘default:test_tony’
0 row(s) in 1.0350 seconds
馬上檢視記錄數
hbase(main):002:0> count ‘hbase:meta’, INTERVAL => 23
Current count: 23, row: users:usertb,7FF70F148964809C8475FEE655005CE3,1523397818177.8c487f00838ae5e9e19ffced7f8914e8.
Current count: 46, row: users:usertb,2FFD4264F7EC7DED66CACB1A2D3AE8EA,1511941432094.8b142ad572b93d65e303a6a5ec5da5a3.
Current count: 69, row: users:usertb,7BF84538F6A96E274651966AF3A6EA87,1515183873848.695d98fb0a9cac2d640c2906444a32e2.
Current count: 92, row: users:usertb,BC0049FADE2ABE2F54CBD8244A861B85,1519967361809.8a7c89d7063118fe9b0e0dd1c9eafd2e.
Current count: 115, row: users:my_table,001|,1511873110944.69e71f4ba7a0f420eb287431b925b377.
Current count: 138, row: users:my_table,0DF7986,1515671013211.2157bae66326fc85b88d2f796f59613a.
Current count: 161, row: users:my_table,59F81618,1515652416016.28d28f08bef06894870ef39ac72482b6.
Current count: 184, row: users:my_table,93FBFF13995C6E8BF2C5ABB244E16B98,1512522023490.9fb718ce9e15a1bf8e4824248b761b45.
Current count: 207, row: users:my_table,E8128B65E40AA34CDC10918689DB0839,1512136535400.74654b61bb4257f7b4fdabc08dceecdd.
Current count: 230, row: test_tony,0E88B0027716FDCB9EBCC25EB7BA81E5,1527665424956.751c339edf3a9e508ed2d607ab6d286e.
239 row(s) in 0.0590 seconds
=> 239
再次檢視記錄數
hbase(main):003:0> count ‘hbase:meta’, INTERVAL => 23
Current count: 23, row: users:usertb,7FF70F148964809C8475FEE655005CE3,1523397818177.8c487f00838ae5e9e19ffced7f8914e8.
Current count: 46, row: users:usertb,2FFD4264F7EC7DED66CACB1A2D3AE8EA,1511941432094.8b142ad572b93d65e303a6a5ec5da5a3.
Current count: 69, row: users:usertb,7BF84538F6A96E274651966AF3A6EA87,1515183873848.695d98fb0a9cac2d640c2906444a32e2.
Current count: 92, row: users:usertb,BC0049FADE2ABE2F54CBD8244A861B85,1519967361809.8a7c89d7063118fe9b0e0dd1c9eafd2e.
Current count: 115, row: users:my_table,001|,1511873110944.69e71f4ba7a0f420eb287431b925b377.
Current count: 138, row: users:my_table,0DF7986,1515671013211.2157bae66326fc85b88d2f796f59613a.
Current count: 161, row: users:my_table,59F81618,1515652416016.28d28f08bef06894870ef39ac72482b6.
Current count: 184, row: users:my_table,93FBFF13995C6E8BF2C5ABB244E16B98,1512522023490.9fb718ce9e15a1bf8e4824248b761b45.
Current count: 207, row: users:my_table,E8128B65E40AA34CDC10918689DB0839,1512136535400.74654b61bb4257f7b4fdabc08dceecdd.
Current count: 230, row: test_tony,0E88B0027716FDCB9EBCC25EB7BA81E5,1527665424956.751c339edf3a9e508ed2d607ab6d286e.
243 row(s) in 0.4780 seconds
=> 243
檢視webUI的此表的情況:表的compaction狀態值、region數量
Table test_tony
Table Attributes
Attribute Name Value Description
Enabled true Is the table enabled
Compaction MINOR Is the table compacting
可以看出compaction狀態值為MONIOR,此次split觸發了小型合併(minor compaction),
原因:被切割的region對應的HFile產生2個更小的 Hfile(倆hfile也對應著2個新的子region),
導致該region中的某一個HStore中的store file數量超過了 hbase.hstore.blockingStoreFiles的值(可配置),
一旦超過這個值,就會觸發minor compaction,更詳細原因請看第二部分的“【延伸】compaction有關的引數介紹 ”
在手動執行split之前是4個region,在hdfs上也能查到有4個region
[[email protected] ~]# hdfs dfs -ls /apps/hbase/data/data/default/test_tony
drwxr-xr-x - hbase hdfs 0 2018-04-26 16:12 /apps/hbase/data/data/default/test_tony/.tabledesc
drwxr-xr-x - hbase hdfs 0 2018-04-26 16:12 /apps/hbase/data/data/default/test_tony/.tmp
drwxr-xr-x - hbase hdfs 0 2018-05-07 09:32 /apps/hbase/data/data/default/test_tony/2b470c5b3b37105443d50b2300711a46
drwxr-xr-x - hbase hdfs 0 2018-05-07 09:09 /apps/hbase/data/data/default/test_tony/48f77b080e02cb8e9e652ec7467bfa76
drwxr-xr-x - hbase hdfs 0 2018-05-07 09:32 /apps/hbase/data/data/default/test_tony/d80b7f116883a820608e7c63880a4c20
drwxr-xr-x - hbase hdfs 0 2018-05-07 09:32 /apps/hbase/data/data/default/test_tony/ef52212a815676f394278729e47748fc
結果是region數量增多了,執行split成功完成以後變成10個
[[email protected] ~]# hdfs dfs -ls /apps/hbase/data/data/default/test_tony
Found 12 items
drwxr-xr-x - hbase hdfs 0 2018-04-26 16:12 /apps/hbase/data/data/default/test_tony/.tabledesc
drwxr-xr-x - hbase hdfs 0 2018-04-26 16:12 /apps/hbase/data/data/default/test_tony/.tmp
drwxr-xr-x - hbase hdfs 0 2018-05-30 15:31 /apps/hbase/data/data/default/test_tony/20f73f44db08fd7279515c8f89a99a35
drwxr-xr-x - hbase hdfs 0 2018-05-30 15:31 /apps/hbase/data/data/default/test_tony/41b72f8f61c425072cd75f988f865f54
drwxr-xr-x - hbase hdfs 0 2018-05-30 15:31 /apps/hbase/data/data/default/test_tony/5d830c556ffb9a36bd80e7a5e80c3c02
drwxr-xr-x - hbase hdfs 0 2018-05-30 15:30 /apps/hbase/data/data/default/test_tony/751c339edf3a9e508ed2d607ab6d286e
drwxr-xr-x - hbase hdfs 0 2018-05-30 15:31 /apps/hbase/data/data/default/test_tony/c76afae02e1978cae057402a6dbc2948
drwxr-xr-x - hbase hdfs 0 2018-05-30 15:31 /apps/hbase/data/data/default/test_tony/cf3fcc71b31cfafb59d902ed84713bea
drwxr-xr-x - hbase hdfs 0 2018-05-30 15:31 /apps/hbase/data/data/default/test_tony/e34634b07b5d37a7adc867b0c36151b4
drwxr-xr-x - hbase hdfs 0 2018-05-30 15:30 /apps/hbase/data/data/default/test_tony/e94599b92dee9874d9dd76dbdbc2aee3
drwxr-xr-x - hbase hdfs 0 2018-05-30 15:31 /apps/hbase/data/data/default/test_tony/fb40ea9d9d0f08a2c880fa6eadeb4814
drwxr-xr-x - hbase hdfs 0 2018-05-30 15:30 /apps/hbase/data/data/default/test_tony/fbc22fc4b6b7f4ca348623468303ae28
順便檢視webUI頁面的Regions by Region Server一欄,發現原先的4個regionServer(RS)中的每個RS分配一個region,切割後hmaster給每個RS分配了2~3個region
Region Server Region Count
tony-host-001.ksc.com:16020 3
tony-host-003.ksc.com:16020 2
tony-host-005.ksc.com:16020 3
tony-host-006.ksc.com:16020 2
到hbase shell檢視hbase:meta表的相關region資訊,可查到10條 info:regioninfo 記錄
hbase(main):011:0> scan ‘hbase:meta’, {STARTROW => ‘test_tony’,COLUMN => ‘info:regioninfo’ ,LIMIT => 20}
ROW COLUMN+CELL
test_tony,,1527665424956.e94599b92dee9874d9dd76dbdbc2aee3. column=info:regioninfo, timestamp=1527665426209, value={ENCODED => e94599b92dee9874d9dd76dbdbc2aee3, NAME => ‘test_tony,,1527665424956.e94599b92dee9874d9dd76dbdbc2aee3.’, START
KEY => ”, ENDKEY => ‘0E88B0027716FDCB9EBCC25EB7BA81E5’}
test_tony,0E88B0027716FDCB9EBCC25EB7BA81E5,1527665424956.7 column=info:regioninfo, timestamp=1527665426209, value={ENCODED => 751c339edf3a9e508ed2d607ab6d286e, NAME => ‘test_tony,0E88B0027716FDCB9EBCC25EB7BA81E5,1527665424956.751c339
51c339edf3a9e508ed2d607ab6d286e. edf3a9e508ed2d607ab6d286e.’, STARTKEY => ‘0E88B0027716FDCB9EBCC25EB7BA81E5’, ENDKEY => ‘23FBF01’}
test_tony,23FBF01,1527665425124.e34634b07b5d37a7adc867b0c3 column=info:regioninfo, timestamp=1527665426209, value={ENCODED => e34634b07b5d37a7adc867b0c36151b4, NAME => ‘test_tony,23FBF01,1527665425124.e34634b07b5d37a7adc867b0c36151b4
6151b4. .’, STARTKEY => ‘23FBF01’, ENDKEY => ‘493C2C’}
test_tony,493C2C,1527665467717.5d830c556ffb9a36bd80e7a5e80 column=info:regioninfo, timestamp=1527665468342, value={ENCODED => 5d830c556ffb9a36bd80e7a5e80c3c02, NAME => ‘test_tony,493C2C,1527665467717.5d830c556ffb9a36bd80e7a5e80c3c02.
c3c02. ‘, STARTKEY => ‘493C2C’, ENDKEY => ‘5BDAEA91’}
test_tony,5BDAEA91,1527665467717.41b72f8f61c425072cd75f988 column=info:regioninfo, timestamp=1527665468342, value={ENCODED => 41b72f8f61c425072cd75f988f865f54, NAME => ‘test_tony,5BDAEA91,1527665467717.41b72f8f61c425072cd75f988f865f5
f865f54. 4.’, STARTKEY => ‘5BDAEA91’, ENDKEY => ‘6E79D9382F405FB9132FA20EDF15CB0B’}
test_tony,6E79D9382F405FB9132FA20EDF15CB0B,1527665425251.c column=info:regioninfo, timestamp=1527665426209, value={ENCODED => cf3fcc71b31cfafb59d902ed84713bea, NAME => ‘test_tony,6E79D9382F405FB9132FA20EDF15CB0B,1527665425251.cf3fcc7
f3fcc71b31cfafb59d902ed84713bea. 1b31cfafb59d902ed84713bea.’, STARTKEY => ‘6E79D9382F405FB9132FA20EDF15CB0B’, ENDKEY => ‘944CAF’}
test_tony,944CAF,1527665467939.fb40ea9d9d0f08a2c880fa6eade column=info:regioninfo, timestamp=1527665468183, value={ENCODED => fb40ea9d9d0f08a2c880fa6eadeb4814, NAME => ‘test_tony,944CAF,1527665467939.fb40ea9d9d0f08a2c880fa6eadeb4814.
b4814. ‘, STARTKEY => ‘944CAF’, ENDKEY => ‘A6AD2E4’}
test_tony,A6AD2E4,1527665467939.c76afae02e1978cae057402a6d column=info:regioninfo, timestamp=1527665468183, value={ENCODED => c76afae02e1978cae057402a6dbc2948, NAME => ‘test_tony,A6AD2E4,1527665467939.c76afae02e1978cae057402a6dbc2948
bc2948. .’, STARTKEY => ‘A6AD2E4’, ENDKEY => ‘B914483’}
test_tony,B914483,1527665425463.20f73f44db08fd7279515c8f89 column=info:regioninfo, timestamp=1527665426209, value={ENCODED => 20f73f44db08fd7279515c8f89a99a35, NAME => ‘test_tony,B914483,1527665425463.20f73f44db08fd7279515c8f89a99a35
a99a35. .’, STARTKEY => ‘B914483’, ENDKEY => ‘DCEF239’}
test_tony,DCEF239,1527665425463.fbc22fc4b6b7f4ca3486234683 column=info:regioninfo, timestamp=1527665426209, value={ENCODED => fbc22fc4b6b7f4ca348623468303ae28, NAME => ‘test_tony,DCEF239,1527665425463.fbc22fc4b6b7f4ca348623468303ae28
03ae28. .’, STARTKEY => ‘DCEF239’, ENDKEY => ”}
10 row(s) in 0.0520 seconds
成功切分後檢視’hbase:meta’表的記錄數,發現由切割前的231條增加到切割後的237條(增加了6條),與切割前的4個region變成切割後的10個region(增加了6個)相吻合。
hbase(main):004:0> count ‘hbase:meta’, INTERVAL => 23
Current count: 23, row: users:usertb,7FF70F148964809C8475FEE655005CE3,1523397818177.8c487f00838ae5e9e19ffced7f8914e8.
Current count: 46, row: users:usertb,2FFD4264F7EC7DED66CACB1A2D3AE8EA,1511941432094.8b142ad572b93d65e303a6a5ec5da5a3.
Current count: 69, row: users:usertb,7BF84538F6A96E274651966AF3A6EA87,1515183873848.695d98fb0a9cac2d640c2906444a32e2.
Current count: 92, row: users:usertb,BC0049FADE2ABE2F54CBD8244A861B85,1519967361809.8a7c89d7063118fe9b0e0dd1c9eafd2e.
Current count: 115, row: users:my_table,001|,1511873110944.69e71f4ba7a0f420eb287431b925b377.
Current count: 138, row: users:my_table,0DF7986,1515671013211.2157bae66326fc85b88d2f796f59613a.
Current count: 161, row: users:my_table,59F81618,1515652416016.28d28f08bef06894870ef39ac72482b6.
Current count: 184, row: users:my_table,93FBFF13995C6E8BF2C5ABB244E16B98,1512522023490.9fb718ce9e15a1bf8e4824248b761b45.
Current count: 207, row: users:my_table,E8128B65E40AA34CDC10918689DB0839,1512136535400.74654b61bb4257f7b4fdabc08dceecdd.
Current count: 230, row: test_tony,23FBF01,1527665425124.e34634b07b5d37a7adc867b0c36151b4.
237 row(s) in 0.0770 seconds
=> 237
第二部分、合併(compaction)
【HFile在hdfs上的位置】
以表users:my_table 為例說明,它有2個列簇,分別是action和basic_info,可以在hdfs上看到他們各自列蔟下面分別有唯一的 HFile :
4a8c4ae1868d4a4bb98590c78ce388f9 和 cfa59c72c8b44790870345e53169760d
[[email protected] ~]# hdfs dfs -ls -h /apps/hbase/data/data/users/my_table/c8faec091a4b87a6b1c7270840fd3b5f/action
Found 1 items
-rw-r–r– 3 hbase hdfs 4.2 G 2018-04-27 16:55 /apps/hbase/data/data/users/my_table/c8faec091a4b87a6b1c7270840fd3b5f/action/4a8c4ae1868d4a4bb98590c78ce388f9
[[email protected] ~]# hdfs dfs -ls -h /apps/hbase/data/data/users/my_table/c8faec091a4b87a6b1c7270840fd3b5f/basic_info/
Found 1 items
-rw-r–r– 3 hbase hdfs 5.0 G 2018-04-27 17:01 /apps/hbase/data/data/users/my_table/c8faec091a4b87a6b1c7270840fd3b5f/basic_info/cfa59c72c8b44790870345e53169760d
hbase的HFile在hdfs上的路徑釋義:{hbase.rootdir}/名稱空間/表名/region/列簇名/hfile
【客戶端從Hbase查詢(GET)資料的流程】
1. 客戶端連線zookeeper,查詢元資料表hbase:meta的位置
2. 查詢元資料表 hbase:meta,根據要get的rowkey去對比每個region的start key和end key,找到特定的region,再獲取該region所在的region server.
3. 到所在的region server找到該region,再由該region server向客戶端返回查到的資料。
4. 若在Memstore中沒有查到匹配的資料,接下來會讀已持久化的StoreFile檔案中的資料。StoreFile也是按key排序的樹形結構的檔案——並且是專門為範圍查詢或block查詢優化過的;HBase讀取磁碟檔案是按其基本I/O單元(即HBase Block)讀資料的。具體就是過程就是:
如果在BlockCache中能查到要造的資料則這屆返回結果,否則就讀去相應的StoreFile檔案中讀取一block的資料,如果還沒有讀到要查的 資料,就將該資料block放到HRegion Server的blockcache中,然後接著讀下一個block塊兒的資料,這樣迴圈讀block資料直到找到要get的資料並返回結果;如果在該Region中的資料都沒有查到,最後直接返回null表示沒有找到匹配資料。那麼blockcache會在其size大於某個閥值(heapsize * hfile.block.cache.size * 0.85)後啟動基於LRU演算法的淘汰機制,將最老最不常用的block刪除。
5. hbase:meta表中的資訊會被快取起來,以便下次查詢。
【每臺regionServer的記憶體結構】
每臺regionServer中的記憶體由BlockCache和MemStore組成。每臺region server只有一個blockCache,可以有多個memStore。
客戶端查詢資料的順序是 memStore –> blockCache –> HFile,先在metStore找,找不到就到blockCache,再找不到就讀取HFile檔案到記憶體中。從HFile中讀到的資料儲存在blockCache,每個列族都有自己的blockCache(block是建立索引的最小資料單元,block大小可調整,預設64kb)。
【為什麼要合併(compaction)】
由於一整行的資訊可能存放在多個HFile中,為了讀出完整行,Hbase可能需要讀取包含該行資訊的所有HFile,所以需要compaction來減少讀取HFile數量,從而提高查詢效率。
每個region由1個或多個HStore組成。
每個列簇對應一個 HStore ,每1個 HStore = 1個memStore + 0到多個StoreFile
【為什麼能提高讀效能】
不論是小型的還是大型的合併操作,都會對HBase的資料做多次重新讀寫,整個過程會產生大量I/O,
直接的結果是減少了store file的數量,從而讓讀請求需要的磁碟I/O頻次、網路I/O頻次更少,也就是說客戶端只需訪問更少的檔案就能獲取資料了。
【compaction的作用】
1,清除已標記為刪除的記錄、過期的記錄、多餘版本的記錄。
2,合併小的store file檔案成為更大的store file檔案,減少store file的數量,顯著提升叢集的效能,吞吐量。
【compact操作的型別】
(1)小型操作(minor compaction)(2)大型操作(major_compaction).
(1)Minor Compaction
它會把讀取後寫成一個新的更大的檔案。
小合併是將相鄰的幾個Store File小的HFile檔案內容讀取出來合併生成一個更大的HFile, 把新檔案設定成啟用狀態,然後刪除小的HFile。
我們通過hbase shell或者客戶端的delete操作來刪除一條記錄,就會在該記錄上打上標記,被打上標記的記錄就成了墓碑記錄,該記錄使用get和scan查詢不到,但還是在HFile中。
minor compaction會清理掉minVersion=0以及設定了TTL的過期資料,但是不會做任何刪除資料,也不會清理多版本資料(major_compact可以)。
(2)Major Compaction
通常管理技術是手動管理主合併(major compactions), 而不是讓HBase 來做。 可通過設定HConstants.MAJOR_COMPACTION_PERIOD 的值為0來關閉自動主合併。
合併一個Region中每一個列族的所有HFile寫到一個HFile中,此操作會刪除掉那些標記為刪除和過期的cells。
具體操作的話,在hbase shell中的命令是major_compact,它會對region下的每個 HStore 裡面的所有StoreFile執行合併,最終的結果每個HStore只有一個HFile.
(當一個Region內的所有儲存檔案中最大的那個HFile大於hbase.hregion.max.filesize所設定的大小觸發split region, 即1個region ==> 2個新的region)
業務上的做法是通過設定引數hbase.hregion.majorcompaction=0來關閉自動major comapction,在業務不忙的時候手動進行major_compact
常用的major_compact操作示例:
Compact某一個表的所有region:
hbase> major_compact ‘table_name’
hbase> major_compact ‘namespace:table_name’
Compact一整個region:
hbase> major_compact ‘region_name’
Compact一個region中的某一個列簇:
hbase> major_compact ‘region_name’, ‘cf_name’
Compact一個表中的某一個列簇:
hbase> major_compact ‘table_name’, ‘cf_name’
【hbase的合併compaction到底做了什麼】
只有進行大合併(major_compact)的時候才會刪除HFile中的墓碑記錄。major_compact是針對region的一個列簇的所有HFile做合併,大合併完成後,這個列簇的所有HFile檔案合併成一個HFile檔案。
大合併可以在hbase shell中手動觸發,但此操作很耗資源,建議在hbase叢集不忙的情況下(例如凌晨)用指令碼執行。
【延伸】compaction有關的引數介紹
hbase.hstore.compaction.max:預設值為10
// minor_compact級別的合併,一次最多合併幾個storefile,避免OOM
hbase.hstore.blockingStoreFiles :預設為7
// 如果region中的任何一個Hstore(非.META.表裡的store)裡面的StoreFile檔案數量大於該值(7),則在flush memstore前必須先進行 split(或者compaction),即阻塞memStore的資料flush到磁碟中,
同時把該region新增到flushQueue,延時重新整理(flush),這期間會阻塞寫操作直到compact(或者split region)完成,或者超過hbase.hstore.blockingWaitTime(預設90s)配置的時間,可以設定為30,避免memstore不及時flush。
當regionserver執行日誌中出現大量的“Region has too many store files; delaying flush up to 90000ms”時,說明這個值需要調整了。
// 也就是說,如果region中的任意一個HStore中的StoreFile數量超過hbase.hstore.blockingStoreFiles的值(7),
則會阻塞從memStore flush到StoreFile的操作,為什麼阻塞呢——因為sotre file太多了,會降低讀效能(因為資料在store file中,store file位於HDFS(磁碟)中而不是記憶體中的blockCache或memStore)。
阻塞時長為hbase.hstore.blockingWaitTime,在這段時間內如果compact storeFile或者split region操作使得HStore檔案數下降到回這個值(7),則停止阻塞。
阻塞超出時長後,會恢復執行flush操作。這樣做就可以有效地控制大量寫請求的速度,但同時這也是影響寫請求速度的主要原因之一。
好了就寫到這裡,看官們覺得漲知識了,請在文章左側點個贊 ^_^
相關推薦
hbase叢集負載均衡與高效能的關鍵——region分割與合併
HBase通過對錶的Region數量實現簡單的負載均衡,官方認為這種實現是簡潔而高效的,能滿足絕大部分的需求。接下來和大家和分享一下自動的負載均衡和手動控制的負載均衡。如下幾種情況時,當前叢集不會執行負載均衡: 1、master沒有被初始化 2、當前已有負載
SQL SERVER 2016 AlwaysOn 無域叢集+負載均衡搭建與簡測
之前和很多群友聊天發現對2016的無域和負載均衡滿心期待,畢竟可以簡單搭建而且可以不適用第三方負載均衡器,SQL自己可以負載了。windows2016已經可以下載使用了,那麼這回終於可以揭開令人憧憬嚮往的AlwaysOn2016 負載均衡叢集的神祕面紗了。 本篇主要描述個人叢集搭建中遇到的坑和一些注
【負載均衡】F5的激活與基本網絡配置
負載均衡 f5 big 一、F5管理IP配置將F5虛擬機打開,F5CLI下面默認賬號為root密碼為default。利用root賬戶登陸後,輸入config命令輸入config命令後會出現如下提示,回車就行選擇yes,修改網絡配置配置IP地址,輸入你要配置的ip,按yes就OK了配置子網掩碼配置網
伺服器叢集負載均衡(F5,LVS,DNS,CDN)區別以及選型
http://www.taocms.org/922.html 下面是“黑夜路人”的《大型網站架構優化(PHP)與相關開源軟體使用建議》 ======================================= F5全稱: F5-BIG-IP-GTM 全球流量管理器. 是
伺服器叢集負載均衡(F5、Array、Nginx、LVS、HAProxy)區別以及選型
PS:Nginx/LVS/HAProxy是目前使用最廣泛的三種負載均衡軟體,本人都在多個專案中實施過,參考了一些資料,結合自己的一些使用經驗,總結一下。 一般對負載均衡的使用是隨著網站規模的提升根據不同的階段來使用不同的技術。具體的應用需求還得具體分析,如果是中小型的Web應用,比如日P
haproxy實現mysql叢集負載均衡
開始使用 Ubuntu 下載安裝 apt-get install haproxy 配置 global log /dev/log local0 log /dev/log local1 notice chr
SpringCloud系列——Zuul 動態路由 SpringCloud系列——Ribbon 負載均衡 SpringCloud系列——Eureka 服務註冊與發現 SpringCloud系列——Ribbon 負載均衡
前言 Zuul 是在Spring Cloud Netflix平臺上提供動態路由,監控,彈性,安全等邊緣服務的框架,是Netflix基於jvm的路由器和伺服器端負載均衡器,相當於是裝置和 Netflix 流應用的 Web 網站後端所有請求的前門。本文基於上篇(SpringCloud系列——Ribbon
負載均衡之TCP連線複用與緩衝
轉自:此處 負載均衡技術通過設定虛擬伺服器IP(VIP),將後端多臺真實伺服器的應用資源虛擬成一臺高效能的應用伺服器,通過負載均衡演算法,將大量來自客戶端的應用請求分配到後端的伺服器進行處理。負載均衡裝置持續的對伺服器上的應用狀態進行檢查,並自動對無效的應用伺服
Redis快取叢集及叢集負載均衡方案設計
快取模組設計 採用分散式快取: 說明: (1)Web伺服器端只負責呼叫介面獲取/更新資料,不必關心業務資料處理; (2)介面負責具體的資料處理,包括快取資料的寫入/更新; (3)快取叢集用於快取伺服器宕機後,資料仍然高可用。 快取寫入規則
windows下通過nginx實現tomcat叢集負載均衡(入門)
一、目標 Windows下,下載安裝nginx Nginx常用命令 Nginx負載均衡兩個tomcat Nginx配置多個負載均衡服務 二、下載安裝nginx 下載地址http://nginx.org/en/download.html 版本nginx-1.
windows系統下實現nlb叢集負載均衡
滑鼠點選 “Edit (編輯) ” ,進入 “Add/Edit Port Rule (新增 / 編輯埠規則) ” 介面,對預設規則進行修 改設定。 Cluster IP address (群集 IP 地址) ” :此設定項是用來指定達到哪個群集 IP 的接受處理方式將按照以 下設定進行。因我們沒有在
Windows下Nginx+tomcat配置叢集負載均衡
Nginx 介紹 Nginx (發音同 engine x)是一款輕量級的Web 伺服器/反向代理伺服器及電子郵件(IMAP/POP3)代理伺服器,並在一個BSD-like 協議下發行。 其特點是佔有記憶體少,併發能力強,事實上nginx的併發能力確實在同類
圖文解說:Nginx+tomcat配置叢集負載均衡
開發的應用採用F5負載均衡交換機,F5將請求轉發給5臺hp unix伺服器,每臺伺服器有多個webserver例項,對外提供web服務和socket等介面服務。之初,曾有個小小的疑問為何不採用開源的apache、Nginx軟體負載,F5裝置動輒幾十萬,價格昂貴?自己一個比較幼稚的問題,後續明白
使用 Nginx + Tomcat 搭建叢集負載均衡
負載均衡 建立在現有網路結構之上,它提供了一種廉價有效透明的方法擴充套件網路裝置和伺服器的頻寬、增加吞吐量、加強網路資料處理能力、提高網路的靈活性和可用性。 負載均衡,英文名稱為Load Balance,其意思就是分攤到多個操作單元上進行執行,例如Web伺服器、FTP伺服器、企業關鍵應用伺服器和
【整理】Nginx+Tomcat+Memcached實現伺服器叢集負載均衡
一. 準備工作1.1 建立使用者及工作目root使用者登入後執行 useradd csdn -------建立使用者csdnpasswd csdn -------給已建立的使用者csdn設定密碼說明:新建立的使用者會在/home下建立一個使用者目錄csdn
(hadoop運維 三) hadoop叢集負載均衡
當hadoop叢集中增加節點、刪除節點或者某個節點磁碟佔用率比較高的情況下,節點之間的儲存就會不均衡,此時就需要對叢集進行重新的負載均衡,在做負載均衡之前,首先要調整dfs.balance.bandwidthPerSec引數,該引數表示叢集負載均衡的頻寬,我的CDH叢集中預
伺服器叢集負載均衡技術
負載均衡 (Load Balancing) 負載均衡建立在現有網路結構之上,它提供了一種廉價有效透明的方法擴充套件網路裝置和伺服器的頻寬、增加吞吐量、加強網路資料處理能力、提高網路的靈活性和可用性。 CDN負載均衡(Load Balance)[1]由於現有網路的各個核心部分
使用Nginx負載均衡搭建高效能.NETweb應用程式一
五、Ngnix如何處理一個請求? 當Nginx啟動時,先會解析我們配置的檔案,得到監聽的埠和Ip地址,master程序就會初始化這個建庫的socket通訊,然後再fork,master呼叫fork函式建立一個新的程序,由fork建立的新程序被稱為子程序,然後這些worker會競爭去接受的新的連線,此
apache Web伺服器叢集負載均衡技術 (轉)
[size=medium]Internet 的快速增長,特別是電子商務應用的發展,使Web應用成為目前最重要最廣泛的應用,Web伺服器動態內容越來越流行。目前,網上資訊交換量幾乎呈指數增長,需要更高效能的Web伺服器提供更多使用者的Web服務,因此,Web伺服器面臨著訪問量急
Apache2+Tomcat7+mod_jk2.2.3叢集負載均衡配置(目前最強悍)
前言 目前公司專案升級,一方面對程式碼進行重構,另外一方面優化伺服器效能。下面就著重分享下Apache的叢集和負載均衡配置。雖然網上相關的文章數不勝數,不過感覺寫的都不是很到位。我這篇文章主要是根據我在實際專案配置的過程中一點點的記錄下來的,希望能夠幫到需要的