
論文閱讀筆記 | (CVPR 2017 Oral) Look Closer to See Better:RA-CNN
論文來自微軟亞洲研究院,做細粒度分類。
Abstract
識別紋理細密的物體類別(比如鳥類)是很困難的,這是因為判別區域定位(discriminative region localization)和細粒度特徵學習(fine-grained feature learning)是很具有挑戰性的。現有方法主要都是單獨地來解決這些挑戰性問題,然而卻忽略了區域檢測(region detection)和細粒度特徵學習(fine-grained feature learning)之間的相互關聯性,而且它們可以互相強化。
本文中,提出了一個全新的迴圈注意力卷積神經網路(recurrent attention convolutional neural network——RA-CNN
RA-CNN 通過尺度內分類損失(intra-scale classification loss)和尺度間排序損失(inter-scale ranking loss)進行優化,以相互學習精準的區域注意力(region attention)和細粒度表徵(fine-grained representation)。RA-CNN 並不需要邊界框(bounding box)或邊界部分的標註(part annotations),而且可以進行端到端的訓練。
Introduction
識別細粒度物體這一類任務往往是極具挑戰性的,這是因為一些紋理細密的物體種類只能被該領域的專家所識別出來。與一般的識別不同,細粒度影象識別(fine-grained image recognition)是應該能夠進行區域性定位(localizing),並且能在其從屬(subordinate)類別中表徵很小的視覺差異的,從而使各種應用受益,比如專家級的影象識別、影象標註等等。
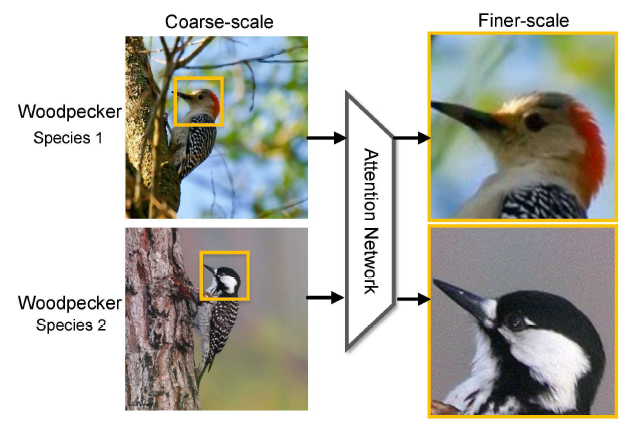
圖 1. 兩種啄木鳥。我們可以從高度區域性區域(highly local regions),比如黃色框裡的頭部,觀察到非常不易察覺的視覺差異,這是難以在原始影象規格中進行學習的。然而,如果我們可以學著去把注意區域放大到一個精細的尺度,差異可能就會更加生動和顯著。
如圖1所示,精確的頭部定位可以促進學習辨別頭部特徵,這進一步幫助精確定位後腦中存在的不同顏色。
提出的RA-CNN是一個疊加網路(stacked network),其輸入為從全影象到多尺度的細粒度區域性區域(fine-grained local regions)。在網路結構設計上主要包含3個scale子網路,每個scale子網路的網路結構都是一樣的,只是網路引數不一樣,在每個scale子網路中包含兩種型別的網路:分類網路和APN網路。因此資料流是這樣的:輸入影象通過分類網路提取特徵並進行分類,然後APN網路基於提取到的特徵進行訓練得到attention region資訊,再將attention region剪裁(crop)出來並放大(zoom in),再作為第二個scale網路的輸入,這樣重複進行3次就能得到3個scale網路的輸出結果,通過融合不同scale網路的結果能達到更好的效果。
Related Work
關於細粒度影象識別的研究沿著兩個維度進行:
1. Discriminative Feature Learning
依賴於強大的卷積深層特徵
2. Sophisticated Part Localization
使用無監督的方法來挖掘注意力區域
放大判別性的區域性區域,以提高細粒度識別效能.
Approach
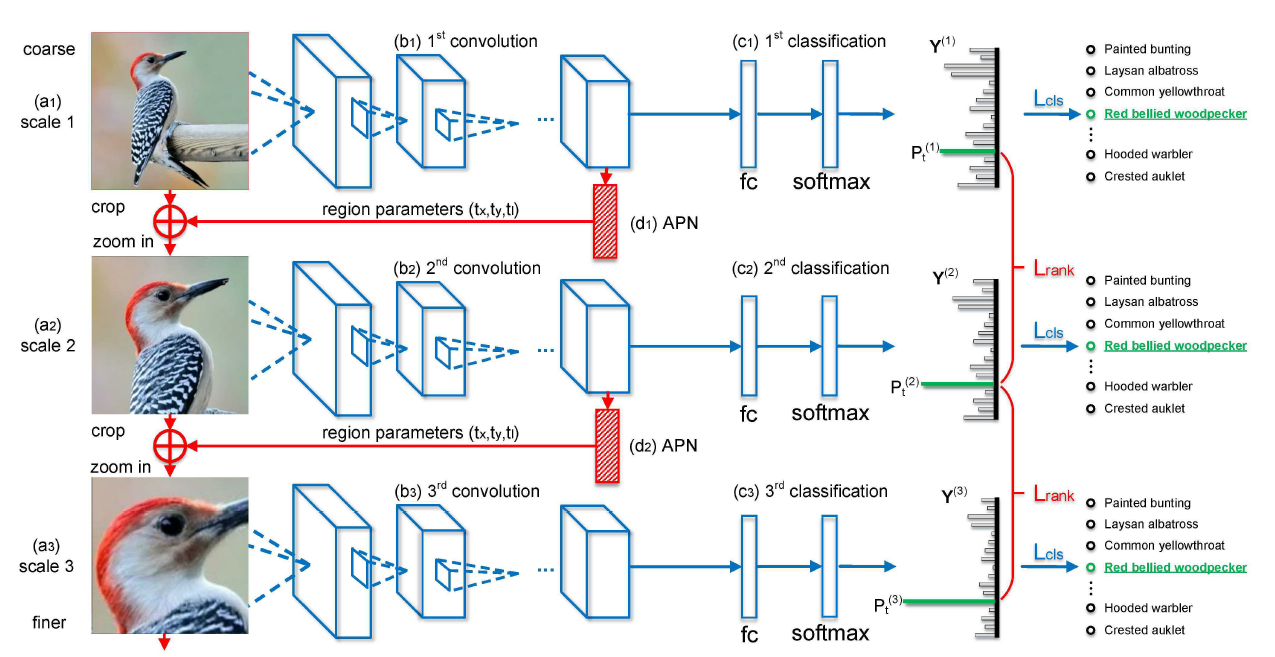
圖 2. RA-CNN框架。
輸入影象從上到下按粗糙的完整大小的影象到精煉後的區域注意力影象排列。不同的網路分類模組(藍色部分)通過同一尺度的標註預測 Y(s) 和真實 Y∗之間的分類損失 Lcl 進行優化,注意力建議(紅色部分)通過相鄰尺度的 p (s) t 和 p (s+1) t 之間的成對排序損失 Lrank(pairwise ranking loss Lrank)進行優化。其中 p (s) t 和 p (s+1) t 表示預測在正確類別的概率,s 代表尺度。APN 是注意力建議網路,fc 代表全連線層,softmax 層通過 fc 層與類別條目(category entry)匹配,然後進行 softmax 操作。+代表「剪裁(crop)」和「放大(zoom in)」。
每個scale網路是有兩個輸出的multi-task結構:
1. 分類
p(X) = f(Wc* X)
Wc: (b1)或(b2)或(b3)網路的引數,也就是一些卷積層、池化層和啟用層的集合,用來從輸入影象中提取特徵.
Wc* X: 就是最後提取到的特徵.
f()函式: 就是fully-connected層和softmax層,用來將學習到的特徵對映成類別概率,也就是p(X).
2. 區域檢測
[tx, ty, tl] = g(Wc* X)
這裡假設檢測出來的區域都是正方形,即tx和ty表示區域的中心點座標,tl表示正方形區域邊長的一半.
g()函式: 也就是APN網路,可以用兩個fully-connected層實現,其中最後一個fully-connected層的輸出channel是3,分別對應tx、ty、tl。
Loss:
a. intra-scale classification loss
b. inter-scale pairwise ranking loss
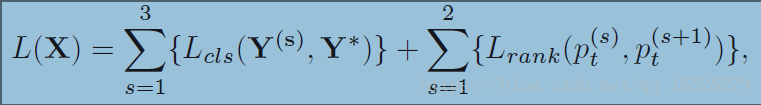
一部分是Lcls,也就是classification loss.
Y(s)表示預測的類別概率,Y*表示真實類別.
pairwise ranking loss:
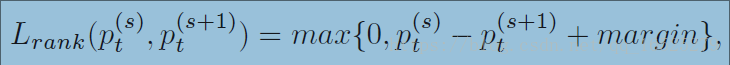
pt(s): prediction probability on the correct category labels t.
從Lrank損失函式可以看出,當更後面的scale網路的pt大於相鄰的前面的scale網路的pt時,損失較小.
通俗講模型的訓練目標是希望更後面的scale網路的預測更準.
於是這樣的網路就可以得到輸入影象X的不同scale特徵,用{F1, F2, ... FN}表示.
N: scale的數量
Fi: 第i個scale的分類子網路全連線層輸出,文中稱Fi為descriptor.
融合不同scale網路的輸出結果:
把每個分類子網路的最後的全連線層堆疊起來,然後將它們連線到一個全連線層,隨後通過softmax層,進行分類.
Training strategy:
a. 初始化分類子網路: 用預訓練的VGG-Net初始化分類子網路中卷積層和全連線層的引數;
b. 初始化APN: 查詢分類子網路的最後一層卷積層(conv5_4 in VGG-19)具有最高響應值(highest response)的區域,用該區域的中心點座標和原圖邊長的一半來初始化(tx,ty,tl);
c. 固定APN的引數,訓練分類子網路直至Lcls收斂; 隨後固定分類子網路的引數,訓練APN網路直至Lrank收斂.這個訓練過程是迭代交替進行的,直到兩個網路的損失收斂.
Experiments
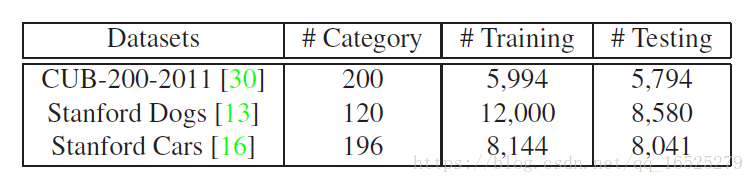
Datasets:
Caltech-UCSD Birds (CUB-200-2011)
Stanford Dogs
Stanford Cars
Baselines:
採用bounding box/part annotation標註的監督式訓練和不採用bounding box標註的無監督式訓練這兩種不同的attention localization演算法。
輸入影象尺寸方面:
Input images (at scale 1) and attended regions (at scale 2,3) are resized to 448×448 and 224×224 pixels respectively in training, due to the smaller object size in the coarse scale.
Conclusion
Propose a recurrent attention convolutional neural network(RA-CNN) for fine-grained recognition, which recursively learns discriminative region attention and region-based feature representation at multiple scales.
RA-CNN does not need bounding box/part annotations for training and can be trained end-to-end.
In the future:
1. How to simultaneously preserve global image structure and model local visual cues, to keep improving the performance at finer scales;
2. How to integrate multiple region attention to model more complex fine-grained categories.