
Redis深入淺出—hash、set
一 、Hash
1.1 介紹
Redis中的字典採用雜湊表作為底層實現,一個雜湊表有多個節點,每個節點儲存一個鍵值對。
在Redis原始碼檔案中,字典的實現程式碼在dict.c和dict.h檔案中。
Redis的資料庫就是使用字典作為底層實現的,通過key和value的鍵值對形式,代表了資料庫中全部資料。而且,所有對資料庫的增、刪、查、改的命令,都是建立在對字典的操作上。
同時,字典還是Redis中雜湊鍵的底層實現,當一個雜湊鍵包含的鍵值對比較多,或者鍵值對中的元素都是比較長的字串時,Redis就會使用字典作為雜湊鍵的底層實現。
當 hash 移除了最後一個元素之後,該資料結構自動被刪除,記憶體被回收。
字典又稱為符號表(symbol table)、關聯陣列(associative array)或對映(map),是一種用於儲存鍵值對(key-value pair)的抽象資料結構。
1.2 命令的用法
- hset(key, field, value):向名稱為key的hash中新增元素field<—>value
- hget(key, field):返回名稱為key的hash中field對應的value
- hmget(key, field1, …,field N):返回名稱為key的hash中field i對應的value
- hmset(key, field1, value1,…,field N, value N):向名稱為key的hash中新增元素field i<—>value i
- hincrby(key, field, integer):將名稱為key的hash中field的value增加integer
- hexists(key, field):名稱為key的hash中是否存在鍵為field的域
- hdel(key, field):刪除名稱為key的hash中鍵為field的域
- hlen(key):返回名稱為key的hash中元素個數
- hkeys(key):返回名稱為key的hash中所有鍵
- hvals(key):返回名稱為key的hash中所有鍵對應的value
- hgetall(key):返回名稱為key的hash中所有的鍵(field)及其對應的value
1.3 原始碼分析
hash 結構的資料主要用到的是字典結構。
其實除了hash會使用到字典,整個 Redis 資料庫的所有 key 和 value 也組成了一個全域性字典,還有帶過期時間的 key 集合也是一個字典。
//該結構體在server.h中定義
typedef struct redisDb {
dict *dict; /*整個資料庫的字典 The keyspace for this DB */
dict *expires; /*有過期時間的字典 Timeout of keys with a timeout set */
dict *blocking_keys; /* Keys with clients waiting for data (BLPOP)*/
dict *ready_keys; /* Blocked keys that received a PUSH */
dict *watched_keys; /* WATCHED keys for MULTI/EXEC CAS */
int id; /* Database ID */
long long avg_ttl; /* Average TTL, just for stats */
} redisDb;zset 集合中儲存 value 和 score 值的對映關係也是通過 dict 結構實現的。
//該結構體在server.h中定義
typedef struct zset {
dict *dict;
zskiplist *zsl;
} zset;Redis定義了dictEntry(雜湊表結點),dictType(字典型別函式),dictht(雜湊表)和dict(字典)四個結構體來實現字典結構,下面來分別介紹這四個結構體。
//雜湊表的table指向的陣列存放這dictEntry型別的地址。定義在dict.h/dictEntryt中
typedef struct dictEntry {//字典的節點
void *key;
union {//使用的聯合體
void *val;
uint64_t u64;//這兩個引數很有用
int64_t s64;
} v;
struct dictEntry *next;//指向下一個hash節點,用來解決hash鍵衝突(collision)
} dictEntry;
//dictType型別儲存著 操作字典不同型別key和value的方法 的指標
typedef struct dictType {
unsigned int (*hashFunction)(const void *key); //計算hash值的函式
void *(*keyDup)(void *privdata, const void *key); //複製key的函式
void *(*valDup)(void *privdata, const void *obj); //複製value的函式
int (*keyCompare)(void *privdata, const void *key1, const void *key2); //比較key的函式
void (*keyDestructor)(void *privdata, void *key); //銷燬key的解構函式
void (*valDestructor)(void *privdata, void *obj); //銷燬val的解構函式
} dictType;
//redis中雜湊表定義dict.h/dictht
typedef struct dictht { //雜湊表
dictEntry **table; //存放一個數組的地址,陣列存放著雜湊表節點dictEntry的地址。
unsigned long size; //雜湊表table的大小,初始化大小為4
unsigned long sizemask; //用於將雜湊值對映到table的位置索引。它的值總是等於(size-1)。
unsigned long used; //記錄雜湊表已有的節點(鍵值對)數量。
} dictht;
//字典結構定義在dict.h/dict
typedef struct dict {
dictType *type; //指向dictType結構,dictType結構中包含自定義的函式,這些函式使得key和value能夠儲存任何型別的資料。
void *privdata; //私有資料,儲存著dictType結構中函式的引數。
dictht ht[2]; //兩張雜湊表。
long rehashidx; //rehash的標記,rehashidx==-1,表示沒在進行rehash
int iterators; //正在迭代的迭代器數量
} dict;
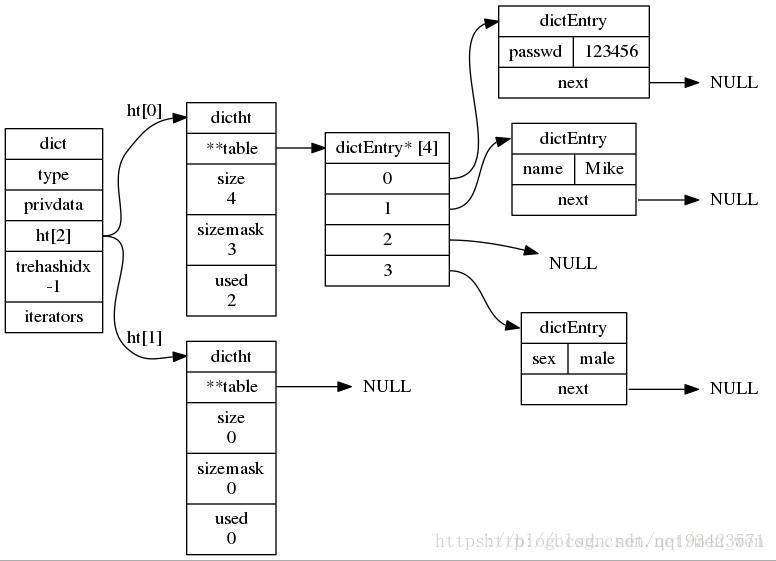
從原始碼中可以看出,dict 結構內部包含兩個 hashtable,通常情況下只有一個 hashtable 是有值的。
但是在 dict 擴容縮容時,需要分配新的 hashtable,然後進行漸進式搬遷,這時候兩個 hashtable 儲存的分別是舊的 hashtable 和新的 hashtable。待搬遷結束後,舊的 hashtable 被刪除,新的 hashtable 取而代之。
字典資料結構的精華就落在了dictht所表示的 hashtable 結構上了。hashtable 的結構和 Java 的 HashMap 幾乎是一樣的,都是通過分桶的方式解決 hash 衝突。第一維是陣列,第二維是連結串列。陣列中儲存的是第二維連結串列的第一個元素的指標。
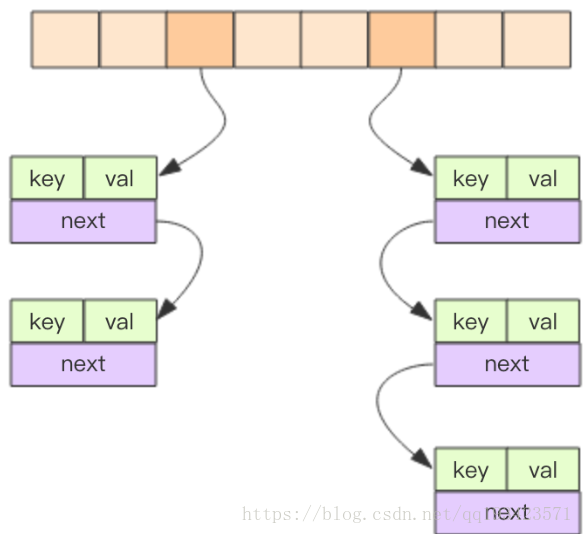
1.4 雜湊演算法
當往字典中新增鍵值對時,需要根據鍵的大小計算出雜湊值和索引值,然後再根據索引值,將包含新鍵值對的雜湊表節點放到雜湊表陣列的指定索引上面。
// 計算雜湊值
h = dictHashKey(d, key);
// 呼叫雜湊演算法計算雜湊值
#define dictHashKey(d, key) (d)->type->hashFunction(key)Redis提供了三種計算雜湊值的函式,其分別是:
- Thomas Wang’s 32 bit Mix函式,對一個整數進行雜湊,該方法在dictIntHashFunction中實現
unsigned int dictIntHashFunction(unsigned int key) //用於計算int整型雜湊值的雜湊函式
{
key += ~(key << 15);
key ^= (key >> 10);
key += (key << 3);
key ^= (key >> 6);
key += ~(key << 11);
key ^= (key >> 16);
return key;
}- 使用MurmurHash2雜湊演算法對字串進行雜湊,該方法在dictGenHashFunction中實現
unsigned int dictGenHashFunction(const void *key, int len) { //用於計算字串的雜湊值的雜湊函式
/* 'm' and 'r' are mixing constants generated offline.
They're not really 'magic', they just happen to work well. */
//m和r這兩個值用於計算雜湊值,只是因為效果好。
uint32_t seed = dict_hash_function_seed;
const uint32_t m = 0x5bd1e995;
const int r = 24;
/* Initialize the hash to a 'random' value */
uint32_t h = seed ^ len; //初始化
/* Mix 4 bytes at a time into the hash */
const unsigned char *data = (const unsigned char *)key;
//將字串key每四個一組看成uint32_t型別,進行運算的到h
while(len >= 4) {
uint32_t k = *(uint32_t*)data;
k *= m;
k ^= k >> r;
k *= m;
h *= m;
h ^= k;
data += 4;
len -= 4;
}
/* Handle the last few bytes of the input array */
switch(len) {
case 3: h ^= data[2] << 16;
case 2: h ^= data[1] << 8;
case 1: h ^= data[0]; h *= m;
};
/* Do a few final mixes of the hash to ensure the last few
* bytes are well-incorporated. */
h ^= h >> 13;
h *= m;
h ^= h >> 15;
return (unsigned int)h;
}- 使用基於djb雜湊的一種簡單的雜湊演算法,該方法在dictGenCaseHashFunction中實現。
unsigned int dictGenCaseHashFunction(const unsigned char *buf, int len) { //用於計算字串的雜湊值的雜湊函式
unsigned int hash = (unsigned int)dict_hash_function_seed;
while (len--)
hash = ((hash << 5) + hash) + (tolower(*buf++)); /* hash * 33 + c */
return hash;
}計算出雜湊值之後,需要計算其索引。Redis採用下列算式來計算索引值。
// 舉例:h為5,雜湊表的大小初始化為4,sizemask則為size-1,
// 於是h&sizemask = 2,
// 所以該鍵值對就存放在索引為2的位置
idx = h & d->ht[table].sizemask;1.4 rehash
當雜湊表的大小不能滿足需求,就可能會有兩個或者以上數量的鍵被分配到了雜湊表陣列上的同一個索引上,於是就發生衝突(collision).
在Redis中解決衝突的辦法是連結法(separate chaining)。但是需要儘可能避免衝突,希望雜湊表的負載因子(load factor),維持在一個合理的範圍之內,就需要對雜湊表進行擴充套件或收縮。
擴容:當 hash 表中元素的個數等於第一維陣列的長度時,就會開始擴容,擴容的新陣列是原陣列大小的 2 倍。不過如果 Redis 正在做 bgsave,為了減少記憶體頁的過多分離 (Copy On Write),Redis 儘量不去擴容 (dict_can_resize),但是如果 hash 表已經非常滿了,元素的個數已經達到了第一維陣列長度的 5 倍 (dict_force_resize_ratio),說明 hash 表已經過於擁擠了,這個時候就會強制擴容。
縮容:當 hash 表因為元素的逐漸刪除變得越來越稀疏時,,Redis 會對 hash 表進行縮容來減少 hash 表的第一維陣列空間佔用。縮容的條件是元素個數低於陣列長度的 10%。縮容不會考慮 Redis 是否正在做 bgsave。
大字典的擴容是比較耗時間的,需要重新申請新的陣列,然後將舊字典所有連結串列中的元素重新掛接到新的陣列下面,這是一個O(n)級別的操作.
擴容操作具體原始碼:
static int _dictExpandIfNeeded(dict *d) //擴充套件d字典,並初始化
{
if (dictIsRehashing(d)) return DICT_OK; //正在進行rehash,直接返回
if (d->ht[0].size == 0) return dictExpand(d, DICT_HT_INITIAL_SIZE); //如果字典(的 0 號雜湊表)為空,那麼建立並返回初始化大小的 0 號雜湊表
//1. 字典的總元素個數和字典的陣列大小之間的比率接近 1:1
//2. 能夠擴充套件的標誌為真
//3. 已使用節點數和字典大小之間的比率超過 dict_force_resize_ratio
if (d->ht[0].used >= d->ht[0].size && (dict_can_resize ||
d->ht[0].used/d->ht[0].size > dict_force_resize_ratio))
{
return dictExpand(d, d->ht[0].used*2); //擴充套件為節點個數的2倍
}
return DICT_OK;
}收縮操作具體原始碼:
int dictResize(dict *d) //縮小字典d
{
int minimal;
//如果dict_can_resize被設定成0,表示不能進行rehash,或正在進行rehash,返回出錯標誌DICT_ERR
if (!dict_can_resize || dictIsRehashing(d)) return DICT_ERR;
minimal = d->ht[0].used; //獲得已經有的節點數量作為最小限度minimal
if (minimal < DICT_HT_INITIAL_SIZE)//但是minimal不能小於最低值DICT_HT_INITIAL_SIZE(4)
minimal = DICT_HT_INITIAL_SIZE;
return dictExpand(d, minimal); //用minimal調整字典d的大小
}擴充套件和收縮操作都呼叫了dictExpand()函式,該函式通過計算傳入的第二個大小引數進行計算,算出一個最接近2n的realsize,然後進行擴充套件或收縮,dictExpand()函式原始碼如下:
int dictExpand(dict *d, unsigned long size) //根據size調整或建立字典d的雜湊表
{
dictht n;
unsigned long realsize = _dictNextPower(size); //獲得一個最接近2^n的realsize
if (dictIsRehashing(d) || d->ht[0].used > size) //正在rehash或size不夠大返回出錯標誌
return DICT_ERR;
if (realsize == d->ht[0].size) return DICT_ERR; //如果新的realsize和原本的size一樣則返回出錯標誌
/* Allocate the new hash table and initialize all pointers to NULL */
//初始化新的雜湊表的成員
n.size = realsize;
n.sizemask = realsize-1;
n.table = zcalloc(realsize*sizeof(dictEntry*));
n.used = 0;
/* Is this the first initialization? If so it's not really a rehashing
* we just set the first hash table so that it can accept keys. */
if (d->ht[0].table == NULL) { //如果ht[0]雜湊表為空,則將新的雜湊表n設定為ht[0]
d->ht[0] = n;
return DICT_OK;
}
d->ht[1] = n; //如果ht[0]非空,則需要rehash
d->rehashidx = 0; //設定rehash標誌位為0,開始漸進式rehash(incremental rehashing)
return DICT_OK;
}收縮或者擴充套件雜湊表需要將ht[0]表中的所有鍵全部rehash到ht[1]中,但是rehash操作不是一次性、集中式完成的,而是分多次,漸進式,斷續進行的,這樣才不會對伺服器效能造成影響。
1.5 漸進式rehash(incremental rehashing)
漸進式rehash的關鍵:
- 字典結構dict中的一個成員rehashidx,當rehashidx為-1時表示不進行rehash,當rehashidx值為0時,表示開始進行rehash。
- 在rehash期間,每次對字典的新增、刪除、查詢、或更新操作時,都會判斷是否正在進行rehash操作,如果是,則順帶進行單步rehash,並將rehashidx+1。
- 當rehash時進行完成時,將rehashidx置為-1,表示完成rehash。
dictEntry *dictAddRaw(dict *d, void *key, dictEntry **existing) {
long index;
dictEntry *entry;
dictht *ht;
// 這裡進行小步搬遷
if (dictIsRehashing(d)) _dictRehashStep(d);
if ((index = _dictKeyIndex(d, key, dictHashKey(d,key), existing)) == -1) return NULL; // 如果字典處於搬遷過程中,要將新的元素掛接到新的陣列下面
ht = dictIsRehashing(d) ? &d->ht[1] : &d->ht[0];
entry = zmalloc(sizeof(*entry));
entry->next = ht->table[index];
ht->table[index] = entry;
ht->used++;
dictSetKey(d, entry, key);
return entry;
}搬遷操作埋伏在當前字典的後續指令中(來自客戶端的hset/hdel指令等),但是有可能客戶端閒下來了,沒有了後續指令來觸發這個搬遷,那麼Redis還會在定時任務中對字典進行主動搬遷。
// 伺服器定時任務
void databaseCron() {
...
if (server.activerehashing) {
for (j = 0; j < dbs_per_call; j++) {
int work_done = incrementallyRehash(rehash_db);
if (work_done) {
break;
} else {
rehash_db++;
rehash_db %= server.dbnum;
}
}
}
}static void _dictRehashStep(dict *d) { //單步rehash
if (d->iterators == 0) dictRehash(d,1); //當迭代器數量不為0,才能進行1步rehash
}
int dictRehash(dict *d, int n) { //n步進行rehash
int empty_visits = n*10; /* Max number of empty buckets to visit. */
if (!dictIsRehashing(d)) return 0; //只有rehashidx不等於-1時,才表示正在進行rehash,否則返回0
while(n-- && d->ht[0].used != 0) { //分n步,而且ht[0]上還有沒有移動的節點
dictEntry *de, *nextde;
/* Note that rehashidx can't overflow as we are sure there are more
* elements because ht[0].used != 0 */
//確保rehashidx沒有越界,因為rehashidx是從-1開始,0表示已經移動1個節點,它總是小於hash表的size的
assert(d->ht[0].size > (unsigned long)d->rehashidx);
//第一個迴圈用來更新 rehashidx 的值,因為有些桶為空,所以 rehashidx並非每次都比原來前進一個位置,而是有可能前進幾個位置,但最多不超過 10。
//將rehashidx移動到ht[0]有節點的下標,也就是table[d->rehashidx]非空
while(d->ht[0].table[d->rehashidx] == NULL) {
d->rehashidx++;
if (--empty_visits == 0) return 1;
}
de = d->ht[0].table[d->rehashidx]; //ht[0]下標為rehashidx有節點,得到該節點的地址
/* Move all the keys in this bucket from the old to the new hash HT */
//第二個迴圈用來將ht[0]表中每次找到的非空桶中的連結串列(或者就是單個節點)拷貝到ht[1]中
while(de) {
unsigned int h;
nextde = de->next; //備份下一個節點的地址
/* Get the index in the new hash table */
h = dictHashKey(d, de->key) & d->ht[1].sizemask; //獲得計算雜湊值並得到雜湊表中的下標h
//將該節點插入到下標為h的位置
de->next = d->ht[1].table[h];
d->ht[1].table[h] = de;
//更新兩個表節點數目計數器
d->ht[0].used--;
d->ht[1].used++;
//將de指向以一個處理的節點
de = nextde;
}
d->ht[0].table[d->rehashidx] = NULL; //遷移過後將該下標的指標置為空
d->rehashidx++; //更新rehashidx
}
/* Check if we already rehashed the whole table... */
if (d->ht[0].used == 0) { //ht[0]上已經沒有節點了,說明已經遷移完成
zfree(d->ht[0].table); //釋放hash表記憶體
d->ht[0] = d->ht[1]; //將遷移過的1號雜湊表設定為0號雜湊表
_dictReset(&d->ht[1]); //重置ht[1]雜湊表
d->rehashidx = -1; //rehash標誌關閉
return 0; //表示前已完成
}
/* More to rehash... */
return 1; //表示還有節點等待遷移
}1.6 hash總結
- 結構:一個字典物件代表了一個dict的例項,一個dict中包含了兩個dictht組成的雜湊表素組和一個指向dicType的指標。定義兩個dictht的作用主要是為了擴容過程中,能夠保證讀取資料的一致性,dicType中定於了一系列的函式指標。每個dictht中,存在一個dicEntry變數,可以看做是字典陣列,也就是俗稱中的bucket桶,存放資料的主要容器。每個dictEntry中,除了包括key和value的鍵值對以外,還包括指向下一個dictEntry物件的指標。
- 雜湊演算法:redis主要提供了三種Hash演算法
- rehash:rehash發生在擴容或縮容階段,擴容是發生在元素的個數等於雜湊表陣列的長度時,進行2倍的擴容;縮容發生在當元素個數為陣列長度的10%時,進行縮容。
- 漸進式rehash:
二 、set
2.1 介紹
Redis 的set集合類似於 Java 語言裡面的 HashSet,它內部的鍵值對是無序的唯一的。它的內部實現相當於一個特殊的字典,字典中所有的 value 都是一個值NULL。
當集合中最後一個元素移除之後,資料結構自動刪除,記憶體被回收。
set結構是字典的衍生結構,而且它具有去重的功能,能夠保證每個key只出現一次。
2.2 使用
- sadd(key, member):向名稱為key的set中添 加元素member
- srem(key, member) :刪除名稱為key的set中的元素member
- spop(key) :隨機返回並刪除名稱為key的set中一個元素
- smove(srckey, dstkey, member) :將member元素從名稱為srckey的集合移到名稱為dstkey的集合
- scard(key) :返回名稱為key的set的基數
sismember(key, member) :測試member是否是名稱為key的set的元素 - sinter(key1, key2,…key N) :求交集
- sinterstore(dstkey, key1, key2,…key N) :求交集並將交集儲存到dstkey的集合
- sunion(key1, key2,…key N) :求並集
- sunionstore(dstkey, key1, key2,…key N) :求並集並將並集儲存到dstkey的集合
- sdiff(key1, key2,…key N) :求差集
- sdiffstore(dstkey, key1, key2,…key N) :求差集並將差集儲存到dstkey的集合
- smembers(key) :返回名稱為key的set的所有元素
- srandmember(key) :隨機返回名稱為key的set的一個元素
hash和set的基本介紹就到此就告一段落了。