
億萬資料量級mongoDB中高效查詢同一欄位的所有不同值集合
阿新 • • 發佈:2019-02-16
公司線上資料用的是mongodb儲存(其實線下一般也用mongodb),最近負責一個專案,需要每天獲得線上資料庫中所有的賣家id和賣家店鋪名稱。其實簡單的將整個資料庫掃一遍,拿出需要的這兩個欄位,再過濾一遍就可以了,但總想試一試更高階點兒的方式,誰叫我懶呢,不想寫太多程式碼,不想做太多維護,還想快速準確拿資料。
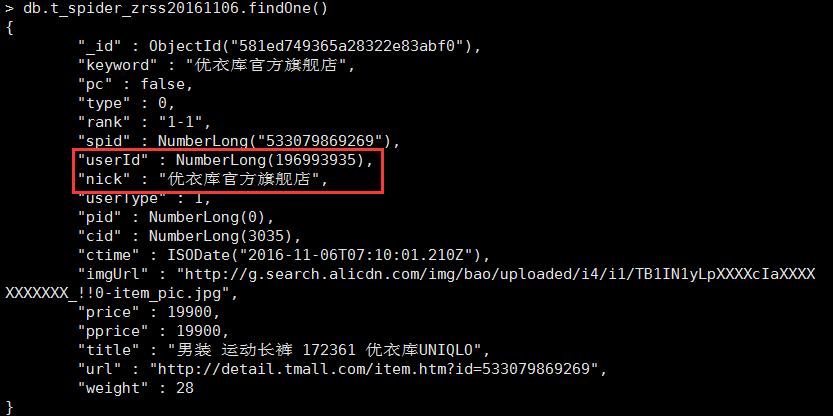
mongodb集合中doc(一個doc表示一個商品資訊)的資料格式如下圖所示,我要做是獲取所有的userId和nick欄位,然後去掉重複的即可。
distinct指令
distinct指令的詳細解釋及用法見官網。億萬級資料量的情況下,distinct指令看看就行了,不然等它執行的時間都夠睡一覺了。
mongoexport工具
通過mongodb自帶的集合匯出工具mongoexport來實現。使用mongoexport匯出集合中需要的欄位到檔案中,然後對檔案進行排序和去重(先排序,後去重,因為uniq只會比較相鄰的兩行並去重)。
momgoexport -c author_name -c collection_name --csv --fields field1 fileld2 -o exported_data.csv
cat exported_data.csv | sort | uniq > unique.txt需要注意的是:匯出的檔案過大的話,同樣會很耗時,甚至導致處理失敗。這個時候就需要將匯出的檔案進行分割成多個小檔案了。
split -d -b 10G exported_data.csv # 將exported_data.csv分割成10G大小的多個小檔案,每個小檔案的結尾以數字結尾切割好了檔案後,再對每個小檔案排序去重即可。
MapReduce
mongodb中可以使用MapReduce很方便的進行分組統計,整個查詢統計過程不牽扯到過多的手工操作,程式碼量也少。
import pymongo
from bson.code import Code
client = pymongo.MongoClient('199.155.122.32:27018')
db = client['products' 我的程式的執行結果如下圖所示:
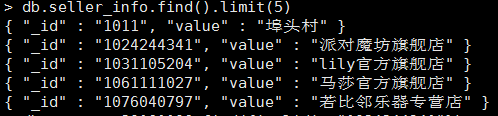
從結果中我們可以看到,ruduce函式中key的值作為了_id欄位的值,返回結果result作為了values欄位的值。