
SVM多核學習方法簡介
作者:Walker
SVM是機器學習有監督學習的一種方法,常用於解決分類問題,其基本原理是:在特徵空間裡尋找一個超平面,以最小的錯分率把正負樣本分開。因為SVM既能達到工業界的要求,機器學習研究者又能知道其背後的原理,所以SVM有著舉足輕重的地位。
但是我們之前接觸過的SVM都是單核的,即它是基於單個特徵空間的。在實際應用中往往需要根據我們的經驗來選擇不同的核函式(如:高斯核函式、多項式核函式等)、指定不同的引數,這樣不僅不方便而且當資料集的特徵是異構時,效果也沒有那麼好。正是基於SVM單核學習存在的上述問題,同時利用多個核函式進行對映的多核學習模型(MKL)應用而生。
多核模型比單個核函式具有更高的靈活性。在多核對映的背景下,高維空間成為由多個特徵空間組合而成的組合空間。由於組合空間充分發揮了各個基本核的不同特徵對映能力,能夠將異構資料的不同特徵分量分別通過相應的核函式得到解決。目前主流的多核學習方法主要包括合成核方法、多尺度核方法和無限核方法。其具體流程如圖1所示:
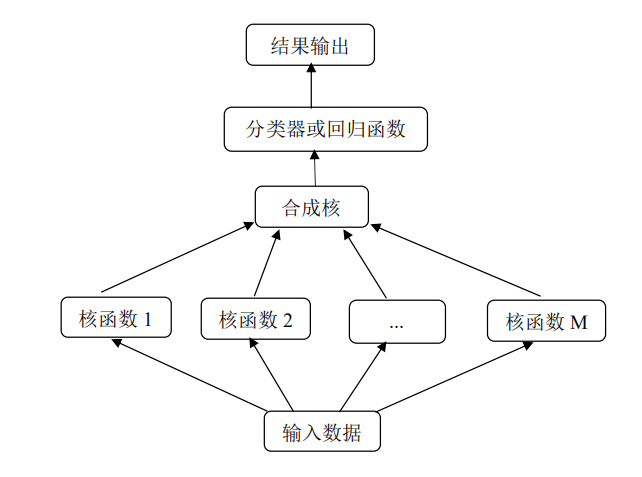
圖1 多核學習流程圖
接下來我們以二分類問題為例,為大家簡單介紹多核學習方法。令訓練資料集為X={(x1,y1),(x2,y2),(x3,y3)…(xn,yn)},其中Xi是輸入特徵,且Xi∈Rd,i= 1,2, …, N,Yi∈{+1, −1}是類標籤。SVM 演算法目標在於最大化間隔,其模型的原始問題可以表示為:
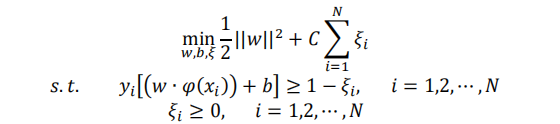
其中,w是待求的權重向量,ζi與C分別是鬆弛變數和懲罰係數。根據拉格朗日對偶性以及 KKT 條件,引入核函式K( Xi , Xj): Rn×Rn → R,原始問題也可以轉換成如下最優化的形式:
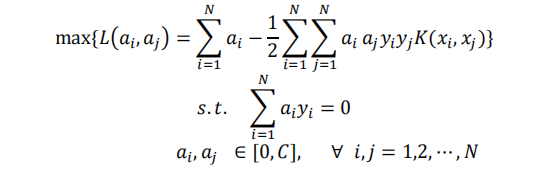
其中,ai與aj為拉格朗日乘子,核函式K( Xi, Xj)=φ(xi) xφ(xj)。核方法的思想就是,在學習與預測中不顯示地定義對映函式φ(xi) ,只定義核函式K( Xi, Xj),直接在原低維空間中計算高維空間中的向量內積,既實現低維樣本空間到高維特徵空間的對映,又不增加計算複雜量。
多核學習方法是單核 SVM 的拓展,其目標是確定 M 個個核函式的最優組合,使得間距最大,可以用如下優化問題表示:
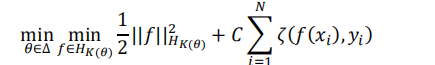
其中∆= {θ∈ ℝ+|θTeM=1},表示 M 個核函式的凸組合的係數,eM是一個向量,M個元素全是 1,K(θ)=∑Mj=1θjkj(∙,∙)代表最終的核函式,其中kj(∙,∙)是第j個核函式。與單核 SVM 一樣,可以將上式如下轉化:
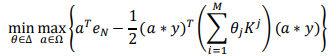
其中Kj∈ RNxN,Ω={a|a∈[0,C]N},“∗”被定義為向量的點積,即(1,0)∗(2,3) = (1 ×2 ,0×3)=(2,0)。通過對比 MKL 與單核 SVM 所對應的優化問題形式,求解多核學習問題的計算複雜度與難度會遠大於單核 SVM,所以研究出一種高效且穩定的演算法來解決傳統多核學習中的優化難題,仍然很具有挑戰性。
綜上所示,儘管多核學習在解決一些異構資料集問題上表現出了非常優秀的效能,但不得不說效率是多核學習發展的最大瓶頸。首先,空間方面,多核學習演算法由於需要計算各個核矩陣對應的核組合係數,需要多個核矩陣共同參加運算。也就是說,多個核矩陣需要同時儲存在記憶體中,如果樣本的個數過多,那麼核矩陣的維數也會非常大,如果核的個數也很多,這無疑會佔用很大的記憶體空間。其次,時間方面,傳統的求解核組合引數的方法即是轉化為SDP優化問題求解,而求解SDP問題需要使用內點法,非常耗費時間,儘管後續的一些改進演算法能在耗費的時間上有所減少,但依然不能有效的降低時間複雜度。高耗的時間和空間複雜度是導致多核學習演算法不能廣泛應用的一個重要原因。
下篇預告:不同核學習方法的研究。
參考文獻:Research on Multiple Kernel Boosting Learning Algorithm
Fast Multiple Kernel Learning for Classification and Application
Research on Multiple Kernel Learning Algorithms and Their Applications