
hadoop資料型別以及序列化和反序列化
序列化和反序列化以及hadoop資料型別
1.什麼是序列化和反序列化
序列化就是把記憶體中的物件,轉換成 位元組序列(或其他資料傳輸協議)以便於儲存(持久化)和網路傳輸。
反序列化就是將收到 位元組序列(或其他資料傳輸協議)或者是硬碟的持久化資料,轉換成 記憶體中的物件。
2.JDK序列化和反序列化
Serialization(序列化)是一種將物件轉換為位元組流;反序列化deserialization是一種將這些位元組流生成一個物件。
a)當你想把的記憶體中的物件儲存到一個檔案中或者資料庫中時候;
b)當你想用套接字在網路上傳送物件的時候;
c)當你想通過RMI傳輸物件的時候;
將需要序列化的類實現Serializable介面就可以了,Serializable介面中沒有任何方法,可以理解為一個標記,即表明這個類可以序列化。
3.Hadoop序列化和反序列化
在hadoop中,hadoop實現了一套自己的序列化框架,hadoop的序列化相對於JDK的序列化來說是比較簡潔而且更節省儲存空間。在叢集中資訊的傳遞主要就是靠這些序列化的位元組序列來傳遞的所以更快速度更小的容量就變得非常地重要了。
4. 同樣的資料在JDK和Hadoop中序列化的位元組數比較
Jdk序列化:
People.java(POJO)
package com.seriable;
import package com.seriable;
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.io.ObjectOutputStream;
public class TestJDKSeriable {
public static void main(String[] args) {
try {
ByteArrayOutputStream baos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(baos);
oos.writeObject(new People(19, "zhangsan"));
System.out.println("位元組大小:"+baos.size());
oos.close();
baos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
//JDK Serialization
//輸出結果:位元組大小:89Hadoop序列化:
PeopleWritable.java(POJO)
package com.seriable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparable;
public class PeopleWritable implements WritableComparable<PeopleWritable> {
private IntWritable age;
private Text name;
public PeopleWritable(){
}
public PeopleWritable(IntWritable age, Text name) {
super();
this.age = age;
this.name = name;
}
public IntWritable getAge() {
return age;
}
public void setAge(IntWritable age) {
this.age = age;
}
public Text getName() {
return name;
}
public void setName(Text name) {
this.name = name;
}
public void write(DataOutput out) throws IOException {
age.write(out);
name.write(out);
}
public void readFields(DataInput in) throws IOException {
age.readFields(in);
name.readFields(in);
}
public int compareTo(PeopleWritable o) {
int cmp = age.compareTo(o.getAge());
if(0 !=cmp)return cmp;
return name.compareTo(o.getName());
}
}package com.seriable;
import java.io.IOException;
import org.apache.hadoop.io.DataOutputBuffer;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
public class TestHadoopSeriable {
public static void main(String[] args) {
try {
DataOutputBuffer dob = new DataOutputBuffer();
PeopleWritable pw = new PeopleWritable(new IntWritable(19), new Text("zhangsan"));
pw.write(dob);
System.out.println("位元組大小:"+dob.getLength());
dob.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
//Hadoop Serialization
//輸出 位元組大小:13由此可以看出同樣的資料,在Jdk 序列化位元組佔用了89個,而在hadoop序列化中卻只使用了13個位元組。大大節省了空間和叢集傳輸效率。
5. Hadoop序列化框架
主要有4個介面,分別是Comparator(位元組比較器), Comparable(物件比較), Writable(序列化), Configurable(引數配置)。
hadoop的序列化的特點是:
1、節省資源:由於頻寬和儲存是叢集中的最寶貴的資源所以我們必須想法設法縮小傳遞資訊的大小和儲存大小,hadoop的序列化就為了更好地坐到這一點而設計的。
2、物件可重用:JDK的反序列化會不斷地建立物件,這肯定會造成一定的系統開銷,但是在hadoop的反序列化中,能重複的利用一個物件的readField方法來重新產生不同的物件。
3、可擴充套件性:當前hadoop的序列化有多中選擇可以利用實現hadoop的WritableComparable介面。
也可使用開源的序列化框架protocol Buffers,Avro等框架。我們可以注意到的是hadoop2.X之後是實現一個YARN,所有應用(mapreduce,或者其他spark實時或者離線的計算框架都可以執行在YARN上),YARN還負責對資源的排程等等。YARN的序列化就是用Google開發的序列化框架protocol Buffers,proto目前支援支援三種語言C++,java,Python所以RPC這一層我們就可以利用其他語言來做文章,滿足其他語言開發者的需求。
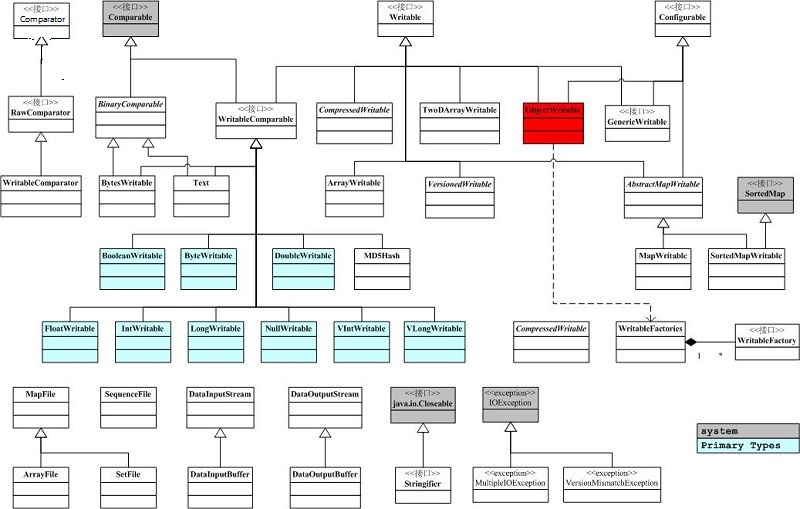
6. Hadoop Writable框架解析
序列化和反序列化只是在物件和位元組轉換的過程中定義了一個數據格式傳輸協議,只要在序列化和反序列化過程中,嚴格遵守這個資料格式傳輸協議就能成功的轉換,當然也可以自行完全實現hadoop序列化框架,像avro框架一樣。
Writable.java
@InterfaceAudience.Public
@InterfaceStability.Stable
public interface Writable {
/**
* 序列化一個物件,將一個物件按照某個資料傳輸格式寫入到out流中
* Serialize the fields of this object to <code>out</code>.
* @throws IOException
*/
void write(DataOutput out) throws IOException;
/**
* 反序列化,從in流中讀入位元組,按照某個資料傳輸格式讀出到一個物件中
* Deserialize the fields of this object from <code>in</code>.
* @throws IOException
*/
void readFields(DataInput in) throws IOException;
}
Comparable.java
public interface Comparable<T> {
/**
* 比較物件,這個在mapreduce中對key的物件進行比較
* Compares this object with the specified object for order. Returns a
* negative integer, zero, or a positive integer as this object is less
* than, equal to, or greater than the specified object.
*/
public int compareTo(T o);
}RawComparator.java
@InterfaceAudience.Public
@InterfaceStability.Stable
public interface RawComparator<T> extends Comparator<T> {
/**
* 在mapreduce,spill過程中,當spill的快取達到一個值時,會將key-value寫入到本地磁碟,並在此過程中sort和patition,如果實現了該介面,就可以直接以序列化的位元組的狀態比較key,而不需要再臨時反序列化成物件再比較,這樣提高了效率節省了時間。
* Compare two objects in binary.
* @param b1 The first byte array.
* @param s1 The position index in b1. The object under comparison's starting index.
* @param l1 The length of the object in b1.
* @param b2 The second byte array.
* @param s2 The position index in b2. The object under comparison's starting index.
* @param l2 The length of the object under comparison in b2.
* @return An integer result of the comparison.
*/
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2);
}各個資料型別的資料序列化格式
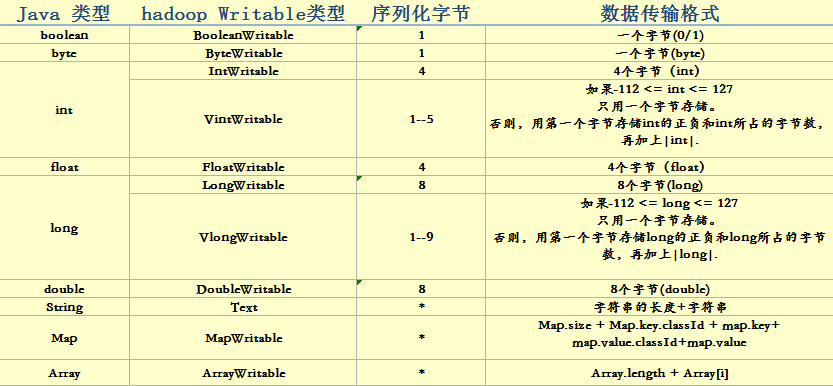
6. 利用hadoop資料傳輸格式序列化自定義物件
People.java
package com.test;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.classification.InterfaceAudience;
import org.apache.hadoop.classification.InterfaceStability;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
import org.apache.hadoop.io.WritableUtils;
@InterfaceAudience.Public
@InterfaceStability.Stable
public class People implements WritableComparable<People> {
private String name;
private int age;
private int deptId;
public People() {
}
public People(String name, int age, int deptId) {
super();
this.name = name;
this.age = age;
this.deptId = deptId;
}
public void write(DataOutput out) throws IOException {
WritableUtils.writeVInt(out, this.name.length());
out.write(this.name.getBytes(), 0, this.name.length());
// out.writeUTF(name);
out.writeInt(age);
out.writeInt(deptId);;
}
public void readFields(DataInput in) throws IOException {
int newLength = WritableUtils.readVInt(in);
byte[] bytes = new byte[newLength];
in.readFully(bytes, 0, newLength);
this.name = new String(bytes, "UTF-8");
this.age = in.readInt();
this.deptId = in.readInt();
}
public int compareTo(People o) {
int cmp = this.name.compareTo(o.getName());
if(cmp !=0)return cmp;
cmp = this.age - o.getAge();
if(cmp !=0)return cmp;
return this.deptId - o.getDeptId();
}
@Override
public boolean equals(Object obj) {
if(obj instanceof People){
People people = (People)obj;
return (this.getName().equals(people.getName()) && this.getAge()==people.getAge()&&this.getDeptId() == people.getDeptId());
}
return false;
}
@Override
public String toString() {
return "People [name=" + name + ", age=" + age +"deptid"+deptId+"]";
}
@Override
public int hashCode() {
return this.name.hashCode() *163 + this.age+this.deptId;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public void setDeptId(int deptId) {
this.deptId = deptId;
}
public int getDeptId() {
return deptId;
}
public static class Comparator extends WritableComparator{
@Override
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) {
int firstL1=0 ,firstL2 = 0;
System.out.println("len:"+b1.length);
int n1 = WritableUtils.decodeVIntSize(b1[s1]); //Vint所佔位元組數
int n2 = WritableUtils.decodeVIntSize(b2[s2]); //vint所佔位元組數
try {
firstL1 = WritableComparator.readVInt(b1, s1); //字串長度
firstL2 = WritableComparator.readVInt(b2, s2); //字串長度
} catch (IOException e) {
e.printStackTrace();
}
int cmp = WritableComparator.compareBytes(b1, s1+n1, firstL1,b2, s2+n2, firstL2);
if(0 != cmp)return cmp;
int thisValue = readInt(b1, firstL1+n1);
int thatValue = readInt(b2, firstL2+n2);
System.out.println("value:"+thisValue);
cmp = thisValue - thatValue;
if(0!=cmp)return cmp;
thisValue = readInt(b1, firstL1+n1+4);
thatValue = readInt(b2, firstL2+n2+4);
System.out.println("value:"+thisValue);
return thisValue - thatValue;
}
}
static{
WritableComparator.define(People.class, new Comparator());
}
}MainDept.java 統計部門員工數
package com.test;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class MainDept {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, People>{
private Text outKey = null;
private People people = null;
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
String[] splits = value.toString().split(" ");
System.out.println("每次map:"+splits.length);
people = new People(splits[0],Integer.valueOf(splits[1]),Integer.valueOf(splits[2]));
outKey = new Text(String.valueOf(people.getDeptId()));
context.write(outKey, people);
// context.write(word, one);
}
}
public static class IntSumReducer
extends Reducer<Text, People,Text,Text> {
// private Text outKey = new Text();
private Text result = null;
public void reduce(Text key, Iterable<People> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (People val : values) {
System.out.println(val.getName());
sum ++;
}
result = new Text();
// outKey.set(String.valueOf(key)+"部門的人數:");
result.set(String.valueOf(sum));
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
}
Job job = Job.getInstance(conf);
job.setJarByClass(MainDept.class);
job.setMapperClass(TokenizerMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(People.class);
//job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
for (int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job,
new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}