
從零開始學Python學習筆記---之--pandas資料框(3)
在pandas資料框(2)我們使用pandas模組實現觀測的篩選、變數的重新命名、資料型別的變換、排序、重複觀測的刪除、和資料集的抽樣,這期我們繼續介紹pandas模組的其他新知識點。包括頻數統計、缺失值處理、資料對映、資料彙總。
一、頻數統計
我們以被調查使用者的收入資料為例,來談談頻數統計函式value_counts
#讀資料 import pandas as pd income = pd.read_excel('income.xlsx') #資料前4行 print(income.head(4))
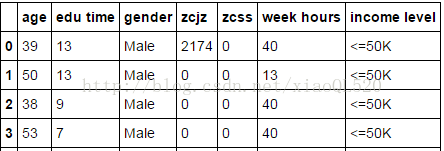
圖片來源:http://mp.weixin.qq.com/s/b8Lce66ViRuvxtAYM8e28Q
頻數統計,顧名思義就是統計某個離散變數各水平的頻次
countedIncome =income.gender.value_counts() print(countedIncome)
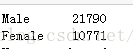
這裡統計的是性別男女的人數,是一個絕對值,如果想進一步檢視男女的百分比例,可以通過下面的方式實現:
percentIncome = income.gender.value_counts()/sum(income.gender.value_counts()) print(percentIncome)
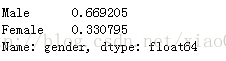
如上是單變數的頻數統計,如果需要統計兩個離散變數的交叉統計表,該如何實現?pandas模組提供了crosstab函式,我們來看看其用法:
result = pd.crosstab(index=income.gender,columns=income['income level']) print(result)

二、缺失值處理
在資料分析或建模過程中,我們希望資料集是乾淨的,沒有缺失、異常之類,但面臨的實際情況確實資料集很髒,例如對於缺失值我們該如何解決?一般情況,缺失值可以通過刪除或替補的方式來處理。首先是要監控每個變數是否存在缺失,缺失的比例如何?這裡我們藉助於pandas模組中的isnull函式、dropna函式和fillna函式
#匯入第三方模組庫import pandas as pd import numpy asnp #手工編造一個含缺失值的資料框:df =pd.DataFrame([[1,2,3,4],[np.NaN,6,7,np.NaN],[11,np.NaN,12,13],[100,200,300,400],[20,40,60,np.NaN]], columns=['x1','x2','x3','x4']) print(df)

使用isnull函式檢查資料集的缺失情況:
#總覽資料集是否存才缺失 print(any(df.isnull),'\n') #每一列是否有缺失值,及缺失比例 is_null = [] null_ratio = [] for col in df.columns: is_null.append(any(pd.isnull(df[col]))) null_ratio.append(float(round(sum(pd.isnull(df[col]))/df.shape[0],2))) print(is_null,'\n',null_ratio,'\n') #每一行是否有缺失 is_null = [] for index in list(df.index): is_null.append(any(pd.isnull(df.iloc[index,:]))) print(is_null,'\n')

對缺失資料進行處理
刪除法
dropna函式,有兩種刪除模式,一種是對含有缺失的行(任意一列)進行刪除,另一種是刪除那些全是缺失(所有列)的行,具體如下:
#對缺失資料進行處理 #刪除法 #刪除任何含有缺失的觀測資料 print(df.dropna())
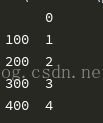
#刪除每行中所有變數都為缺失值的觀測 print(df.dropna(how='all'))
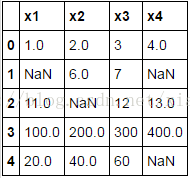
由於df資料集不存在行全為缺失的觀測,故沒有實現刪除
替補法
fillna函式提供前向替補、後向替補和函式替補的幾種方法,具體可參見下面的程式碼示例:
#前向替補print(df.fillna(method='ffill'))

#後向替補print(df.fillna(method='bfill'))
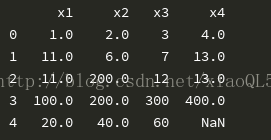
#不同的列用不同的函式替補data =df.fillna(value={'x1':df.x1.mean(), 'x2':df.x2.median(), 'x4':df.x4.max()}) print(data)

三、資料對映
大家都知道,Python在做迴圈時,效率還是很低的,如何避開迴圈達到相同的效果呢?這就是接下來我們要研究的對映函式apply。該函式的目的就是將使用者指定的函式運用到資料集的縱軸即各個變數或橫軸即各個行。
例如以上面的統計資料集df各行和各列是否存在缺失為例,原先是這樣的:
#總覽資料集是否存才缺失print(any(df.isnull()),'\n') #每一列是否有缺失值,及缺失比例is_null = [] null_ratio = [] for col in df.columns: is_null.append(any(pd.isnull(df[col]))) null_ratio.append(float(round(sum(pd.isnull(df[col]))/df.shape[0],2))) print(is_null,'\n',null_ratio,'\n') #每一行是否有缺失is_null = [] for index in list(df.index): is_null.append(any(pd.isnull(df.iloc[index,:]))) print(is_null,'\n')

現在通過對映函式可以這樣簡介而快速的實現:
#檢視各列各行是否有缺失 #建立一個判斷物件是否含缺失的匿名函式 isNull = lambda x :any(pd.isnull(x)) #使用apply對映函式#axis=0表示將isNull函式對映到各列 data = df.apply(func=isNull,axis=0) print(data)
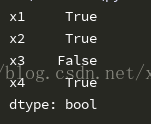
#axis=1表示將isNull函式對映到各行 data = df.apply(func=isNull,axis=1) print(data)

再如,需要計算每個學生的總成績,或各科的平均分,也可以用apply函式實現:
#讀取資料 score = pd.read_csv('test.csv') print(score.head(3))
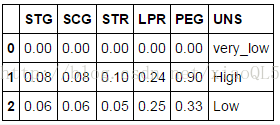
#讀取資料score = pd.read_csv('test.csv') print(score.head(3)) #每個學生的平均成績score['tot'] =score.iloc[:,0:5].apply(func = np.sum,axis =1)
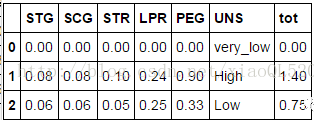
圖片來源:http://mp.weixin.qq.com/s/b8Lce66ViRuvxtAYM8e28Q
#每門學科的平均分數score.iloc[:,0:5].apply(func = np.mean,axis =0)

四、資料彙總
如果你想要做類似SQL中的聚合操作,pandas也提供了實現該功能的函式,即groupby函式與aggregate函式的搭配使用,我們以上面的收入資料集為例作為演示:
print(income.head(2))
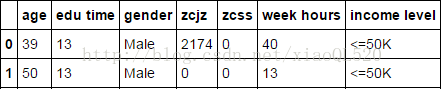
#對性別gender做分組統計 groupby_gender = income.groupby(['gender']) groupby_gender.aggregate(np.mean)
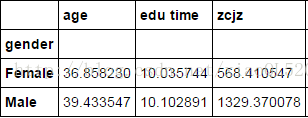
以上結果,預設會對所有數值型變數作性別的均值統計。
#對性別gender和收入水平兩個變數做分組統計 grouped = income.groupby(['gender','income level']) grouped.aggregate(np.mean)

#對性別和收入水平兩個變數做分組統計,但不同的變數做不同的聚合 grouped = income.groupby(['gender','income level']) #例如,對年齡算平均值,對教育時長算中位數 grouped.aggregate({'age':np.mean,'edu time':np.median})

學習地址:http://mp.weixin.qq.com/s/b8Lce66ViRuvxtAYM8e28Q