
關於SVM一篇比較全介紹的博文
動筆寫這個支援向量機(support vector machine)是費了不少勁和困難的,原因很簡單,一者這個東西本身就並不好懂,要深入學習和研究下去需花費不少時間和精力,二者這個東西也不好講清楚,儘管網上已經有朋友寫得不錯了(見文末參考連結),但在描述數學公式的時候還是顯得不夠。得益於同學白石的數學證明,我還是想嘗試寫一下,希望本文在兼顧通俗易懂的基礎上,真真正正能足以成為一篇完整概括和介紹支援向量機的導論性的文章。
本文在寫的過程中,參考了不少資料,包括《支援向量機導論》、《統計學習方法》及網友pluskid的支援向量機系列等等,於此,還是一篇學習筆記,只是加入了自己的理解和總結,有任何不妥之處,還望海涵。全文巨集觀上整體認識支援向量機的概念和用處,微觀上深究部分定理的來龍去脈,證明及原理細節,力保邏輯清晰
& 通俗易懂。
同時,閱讀本文時建議大家儘量使用chrome等瀏覽器,如此公式才能更好的顯示,再者,閱讀時可拿張紙和筆出來,把本文所有定理.公式都親自推導一遍或者直接列印下來(可直接列印網頁版或本文文末附的PDF,享受隨時隨地思考、演算的極致快感),在文稿上演算。
Ok,還是那句原話,有任何問題,歡迎任何人隨時不吝指正 & 賜教,感謝。
第一層、瞭解SVM
支援向量機,因其英文名為support vector machine,故一般簡稱SVM,通俗來講,它是一種二類分類模型,其基本模型定義為特徵空間上的間隔最大的線性分類器,其學習策略便是間隔最大化,最終可轉化為一個凸二次規劃問題的求解。
理解SVM,咱們必須先弄清楚一個概念:線性分類器。
給定一些資料點,它們分別屬於兩個不同的類,現在要找到一個線性分類器把這些資料分成兩類。如果用x表示資料點,用y表示類別(y可以取1或者-1,分別代表兩個不同的類),一個線性分類器的學習目標便是要在n維的資料空間中找到一個超平面(hyper plane),這個超平面的方程可以表示為( wT中的T代表轉置):
可能有讀者對類別取1或-1有疑問,事實上,這個1或-1的分類標準起源於logistic迴歸。
Logistic迴歸目的是從特徵學習出一個0/1分類模型,而這個模型是將特性的線性組合作為自變數,由於自變數的取值範圍是負無窮到正無窮。因此,使用logistic函式(或稱作sigmoid函式)將自變數對映到(0,1)上,對映後的值被認為是屬於y=1的概率。
假設函式
其中x是n維特徵向量,函式g就是logistic函式。

而

可以看到,將無窮對映到了(0,1)。
而假設函式就是特徵屬於y=1的概率。

從而,當我們要判別一個新來的特徵屬於哪個類時,只需求![]() 即可,若
即可,若![]() 大於0.5就是y=1的類,反之屬於y=0類。
大於0.5就是y=1的類,反之屬於y=0類。
此外,![]() 只和
只和![]() 有關,
有關,![]() >0,那麼
>0,那麼![]() ,而g(z)只是用來對映,真實的類別決定權還是在於
,而g(z)只是用來對映,真實的類別決定權還是在於![]() 。再者,當
。再者,當![]() 時,
時,![]() =1,反之
=1,反之![]() =0。如果我們只從
=0。如果我們只從![]() 出發,希望模型達到的目標就是讓訓練資料中y=1的特徵
出發,希望模型達到的目標就是讓訓練資料中y=1的特徵![]() ,而是y=0的特徵
,而是y=0的特徵![]() 。Logistic迴歸就是要學習得到
。Logistic迴歸就是要學習得到![]() ,使得正例的特徵遠大於0,負例的特徵遠小於0,而且要在全部訓練例項上達到這個目標。
,使得正例的特徵遠大於0,負例的特徵遠小於0,而且要在全部訓練例項上達到這個目標。
接下來,嘗試把logistic迴歸做個變形。首先,將使用的結果標籤y = 0和y = 1替換為y = -1,y = 1,然後將![]() (
(![]() )中的
)中的替換為b,最後將後面的
![]() 替換為
替換為![]() (即
(即![]() )。如此,則有了
)。如此,則有了![]() 。也就是說除了y由y=0變為y=-1外,線性分類函式跟logistic迴歸的形式化表示
。也就是說除了y由y=0變為y=-1外,線性分類函式跟logistic迴歸的形式化表示![]() 沒區別。
沒區別。
進一步,可以將假設函式![]() 中的g(z)做一個簡化,將其簡單對映到y=-1和y=1上。對映關係如下:
中的g(z)做一個簡化,將其簡單對映到y=-1和y=1上。對映關係如下:
1.2、線性分類的一個例子
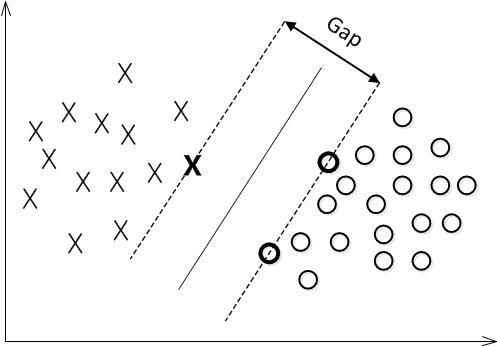
下面舉個簡單的例子,如下圖所示,現在有一個二維平面,平面上有兩種不同的資料,分別用圈和叉表示。由於這些資料是線性可分的,所以可以用一條直線將這兩類資料分開,這條直線就相當於一個超平面,超平面一邊的資料點所對應的y全是 -1 ,另一邊所對應的y全是1。
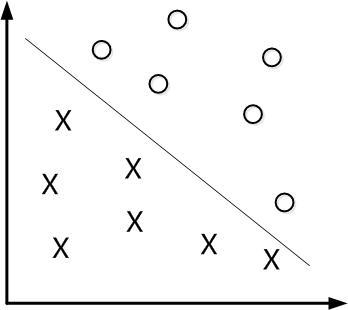
這個超平面可以用分類函式表示,當f(x)
等於0的時候,x便是位於超平面上的點,而f(x)大於0的點對應 y=1 的資料點,f(x)小於0的點對應y=-1的點,如下圖所示:
注:有的資料上定義特徵到結果的輸出函式
(有一朋友飛狗來自Mare_Desiderii,看了上面的定義之後,問道:請教一下SVM functional margin 為=y(wTx+b)=yf(x)中的Y是隻取1和-1
嗎?y的唯一作用就是確保functional margin的非負性?真是這樣的麼?當然不是,詳情請見本文評論下第43樓)
換言之,在進行分類的時候,遇到一個新的資料點x,將x代入f(x) 中,如果f(x)小於0則將x的類別賦為-1,如果f(x)大於0則將x的類別賦為1。
接下來的問題是,如何確定這個超平面呢?從直觀上而言,這個超平面應該是最適合分開兩類資料的直線。而判定“最適合”的標準就是這條直線離直線兩邊的資料的間隔最大。所以,得尋找有著最大間隔的超平面。
1.3、函式間隔Functional margin與幾何間隔Geometrical margin在超平面w*x+b=0確定的情況下,|w*x+b|能夠表示點x到距離超平面的遠近,而通過觀察w*x+b的符號與類標記y的符號是否一致可判斷分類是否正確,所以,可以用(y*(w*x+b))的正負性來判定或表示分類的正確性。於此,我們便引出了函式間隔(functional margin)的概念。
定義函式間隔(用表示)為:
而超平面(w,b)關於T中所有樣本點(xi,yi)的函式間隔最小值(其中,x是特徵,y是結果標籤,i表示第i個樣本),便為超平面(w, b)關於訓練資料集T的函式間隔:
= min
但這樣定義的函式間隔有問題,即如果成比例的改變w和b(如將它們改成2w和2b),則函式間隔的值f(x)卻變成了原來的2倍(雖然此時超平面沒有改變),所以只有函式間隔還遠遠不夠。
事實上,我們可以對法向量w加些約束條件,從而引出真正定義點到超平面的距離--幾何間隔(geometrical margin)的概念。
假定對於一個點 x ,令其垂直投影到超平面上的對應點為 x0 ,w 是垂直於超平面的一個向量,為樣本x到分類間隔的距離,如下圖所示:

有,其中||w||表示的是範數。
又由於 x0 是超平面上的點,滿足 f(x0)=0 ,代入超平面的方程即可算出:
γ
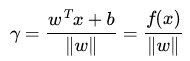
(有的書上會寫成把||w|| 分開相除的形式,如本文參考文獻及推薦閱讀條目11,其中,||w||為w的二階泛數)
為了得到的絕對值,令
乘上對應的類別
y,即可得出幾何間隔(用
表示)的定義:
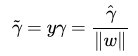
從上述函式間隔和幾何間隔的定義可以看出:幾何間隔就是函式間隔除以||w||,而且函式間隔y*(wx+b) = y*f(x)實際上就是|f(x)|,只是人為定義的一個間隔度量,而幾何間隔|f(x)|/||w||才是直觀上的點到超平面的距離。
1.4、最大間隔分類器Maximum Margin Classifier的定義
對一個數據點進行分類,當超平面離資料點的“間隔”越大,分類的確信度(confidence)也越大。所以,為了使得分類的確信度儘量高,需要讓所選擇的超平面能夠最大化這個“間隔”值。這個間隔如下圖中的gap / 2所示。
通過由前面的分析可知:函式間隔不適合用來最大化間隔值,因為在超平面固定以後,可以等比例地縮放w的長度和b的值,這樣可以使得的值任意大,亦即函式間隔
可以在超平面保持不變的情況下被取得任意大。但幾何間隔因為除上了
,使得在縮放w和b的時候幾何間隔
的值是不會改變的,它只隨著超平面的變動而變動,因此,這是更加合適的一個間隔。所以,這裡要找的最大間隔分類超平面中的“間隔”指的是幾何間隔。
於是最大間隔分類器(maximum margin classifier)的目標函式可以定義為:
同時需滿足一些條件,根據間隔的定義,有
其中,s.t.,即subject to的意思,它匯出的是約束條件。
回顧下幾何間隔的定義可知:如果令函式間隔
等於1(之所以令
等於1,是為了方便推導和優化,且這樣做對目標函式的優化沒有影響,至於為什麼,請見本文評論下第42樓回覆),則有
=
1 / ||w||且
,從而上述目標函式轉化成了

這個目標函式便是在相應的約束條件下,最大化這個1/||w||值,而1/||w||便是幾何間隔
。
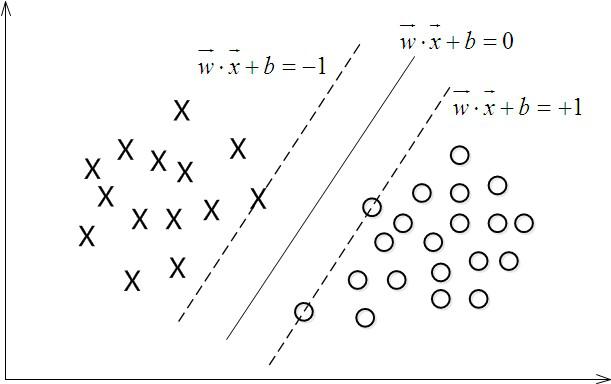
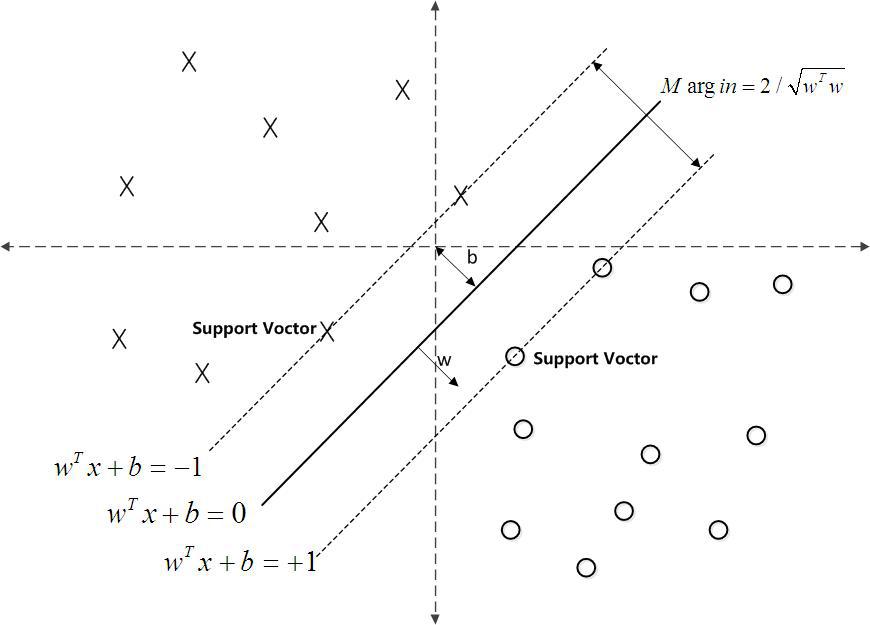
如下圖所示,中間的實線便是尋找到的最優超平面(Optimal Hyper Plane),其到兩條虛線的距離相等,這個距離便是幾何間隔,兩條虛線之間的距離等於2
,而虛線上的點則是支援向量。由於這些支援向量剛好在邊界上,所以它們滿足
(還記得我們把
functional margin 定為 1 了嗎?上節中:處於方便推導和優化的目的,我們可以令
=1),而對於所有不是支援向量的點,則顯然有
。
OK,到此為止,算是瞭解到了SVM的第一層,對於那些只關心怎麼用SVM的朋友便已足夠,不必再更進一層深究其更深的原理。
第二層、深入SVM2.1、從線性可分到線性不可分2.1.1、從原始問題到對偶問題的求解
接著考慮之前得到的目標函式:
由於求[img]file:///D:/Users/FLOYD/AppData/Local/Temp/TempPic/7MC_V(1%7B(25]VM%7BNDBE2[Y5.tmp[/img]


因為現在的目標函式是二次的,約束條件是線性的,所以它是一個凸二次規劃問題。這個問題可以用現成的QP (Quadratic Programming) 優化包進行求解。一言以蔽之:在一定的約束條件下,目標最優,損失最小。
此外,由於這個問題的特殊結構,還可以通過拉格朗日對偶性(Lagrange Duality)變換到對偶變數 (dual variable) 的優化問題,即通過求解與原問題等價的對偶問題(dual problem)得到原始問題的最優解,這就是線性可分條件下支援向量機的對偶演算法,這樣做的優點在於:一者對偶問題往往更容易求解;二者可以自然的引入核函式,進而推廣到非線性分類問題。
那什麼是拉格朗日對偶性呢?簡單來講,通過給每一個約束條件加上一個拉格朗日乘子(Lagrange multiplier),定義拉格朗日函式(通過拉格朗日函式將約束條件融合到目標函式裡去,從而只用一個函式表示式便能清楚的表達出我們的問題):

然後令
容易驗證,當某個約束條件不滿足時,例如,那麼顯然有
(只要令
即可)。而當所有約束條件都滿足時,則有
,亦即最初要最小化的量。
因此,在要求約束條件得到滿足的情況下最小化,實際上等價於直接最小化
(當然,這裡也有約束條件,就是
≥0,i=1,…,n)
,因為如果約束條件沒有得到滿足,
會等於無窮大,自然不會是我們所要求的最小值。
具體寫出來,目標函式變成了:
這裡用表示這個問題的最優值,且和最初的問題是等價的。如果直接求解,那麼一上來便得面對w和b兩個引數,而
又是不等式約束,這個求解過程不好做。不妨把最小和最大的位置交換一下,變成:

交換以後的新問題是原始問題的對偶問題,這個新問題的最優值用來表示。而且有
≤
,在滿足某些條件的情況下,這兩者相等,這個時候就可以通過求解對偶問題來間接地求解原始問題。
動筆寫這個支援向量機(support vector machine)是費了不少勁和困難的,原因很簡單,一者這個東西本身就並不好懂,要深入學習和研究下去需花費不少時間和精力,二者這個東西也不好講清楚,儘管網上已經有朋友寫得不錯了(見文末參考連結),但在描述數
因為需要,又不想自己寫,所以就移植了一個檔案系統。
說下我的硬體和開發工具:接成 TRUE IDE
模式下的CF卡(也就是相當於一塊硬碟了),三星S3C2440的ARM9,開發工具是很老很老的D版的ADS1.2。
摘自:http://blog.163.com/[email protected]/blog/static/3278568820090710053782/
補充一點,FatFs的作者寫了兩個,一個是正宗的FatFs,比較適合大的RAM的裝置,另一個是FatFs/
(一)SVM的背景簡介
支援向量機(Support Vector Machine)是Cortes和Vapnik於1995年首先提出的,它在解決小樣本、非線性及高維模式識別中表現出許多特有的優勢,並能夠推廣應用到函式擬合等其他機器學習問題中[10]。
支援向量機方法是建立在
Git使用教程
Git是什麼
文章轉載自 程式碼飛:https://code.bywind.cn/2018/07/14/170/
Git是一個開源的分散式版本控制系統,用於敏捷高效地處理任何或小或大的專案。 Git是 Linus Torvalds 為了幫助管理 Li
這是一篇難得的絕世好文!值得收在手機裡經常看
每週讀一本書 每週讀一本書
01
人靜時,躺下來仔細想想,人活著真不容易,明知以後會死,還要努力的活著,人活一輩子到底是為什麼?
複雜的社會,看不透的人心,放不下的牽掛,經歷不完的酸
FreeMarker的模板檔案並不比HTML頁面複雜多少,FreeMarker模板檔案主要由如下4個部分組成: 1,文字:直接輸出的部分 2,註釋:<#-- ... -->格式部分,不會輸出 3,插值:即${...}或#{...}格式的部分,將使用資料
以下內容全部是網上收集:
FreeMarker的模板檔案並不比HTML頁面複雜多少,FreeMarker模板檔案主要由如下4個部分組成:
1,文字:直接輸出的部分
2,註釋:<#-- ... -->格式部分,不會輸出
3,插值:即
聽說有家叫Salesforce的CRM公司很厲害
你肯定聽說過不少國內CRM企業信誓旦旦地想做中國的Salesforce。作為CRM領域的標杆,Salesforce在國際市場上到底有多厲害?看看權威雜誌的這些資料你就明白了。
Salesfo
一篇很全的FreeMarker指令使用FreeMarker的模板檔案並不比HTML頁面複雜多少,FreeMarker模板檔案主要由如下4個部分組成:文字:直接輸出的部分 註釋:<#-- ... -->格式部分,不會輸出 插值:即${...}或#{...}格式的部分
深度學習caffe平臺--製作自己.lmdb格式資料集及分類標籤檔案
https://blog.csdn.net/guo1988kui/article/details/78356736
Caffe學習筆記3——製作並訓練自己的資料集
https://blog.csdn.net/hit20
copy自http://demojava.iteye.com/blog/800204
以下內容全部是網上收集:
FreeMarker的模板檔案並不比HTML頁面複雜多少,FreeMarker模板檔案主要由如下4個部分組成:
1,文字:直接輸出的部分
這些年來多從事Linux下PHP和C相關的開發,帶過很多專案和團隊,下面是根據經驗整理的PHP編碼規範,可以用作給大家的範例和參考,根據需要進行取捨和修改!
(可能最新的一些php5的規範不夠完整,今後有機會保持更新!)
目錄1 編寫目的2 整體要求3 安全規範3.1 包含檔
以下內容全部是網上收集:
FreeMarker的模板檔案並不比HTML頁面複雜多少,FreeMarker模板檔案主要由如下4個部分組成:
1,文字:直接輸出的部分
2,註釋:<#-- ... -->格式部分,不會輸出
3,插值:即${...}或#{...}格
一、對於執行緒同步和同步鎖的理解(注:分享了三篇高質量的部落格)
以下我精心的挑選了幾篇博文,分別是關於對執行緒同步的理解和如何選擇執行緒鎖以及瞭解執行緒鎖的作用範圍。
<一>執行緒同步鎖的選擇
2. 以上推薦的博文是以賣火車票為例,引出了非同步會導致的錯誤以及同步鎖(監視器)應該如果選擇,
今天在學校又雙叒叕提到了 Deep Reinforcement Learning That Ma 本文始發於個人公眾號:TechFlow,原創不易,求個關注
今天我們講的是LeetCode的31題,這是一道非常經典的問題,經常會在面試當中遇到。在今天的文章當中除了關於題目的分析和解答之外,我們還會詳細解讀深度優先搜尋和回溯演算法,感興趣的同學不容錯過。
連結
Next Permutation
難度
M package static 技術分享 整理 public out 計算 mage 數字 1.程序設計思想
先讓用戶輸入要計算的數字的個數,然後讓用戶輸入這幾個數,將字符型轉化為整數,然後求和,最後輸出所求得的和即可。
2.程序流程圖
3.源程序代碼
pack top exception 漢諾塔 一個數 resource valueof val 作業 回文數 信1605-3 於丁一 20163578
使用組合數公式利用n!來計算
設計思想:首先要判斷一個數的階乘如何表達,然後調用方法用組合數公式,最後求出組合數。
packag rac println 需要 如果 value const tps http 建立 1. spring整合struts的基本操作見我的上一篇博文:https://www.cnblogs.com/wyhluckdog/p/10140588.html,這裏面將spring與st 相關推薦
關於SVM一篇比較全介紹的博文
轉一篇比較詳細介紹FatFs檔案系統移植的文章 FatFs檔案系統的移植
轉一篇比較詳細介紹FatFs檔案系統移植的文章
SVM-支援向量機演算法概述 ---一篇非常深入淺出介紹SVM的文章
git使用教程-一篇文章全搞定哦
這是一篇難得的絕世好文!值得收在手機裡經常看
一篇很全面的freemarker 前端web教程
一篇很全面的freemarker教程
【睿遠諮詢】聽說你是小白?這裡有一篇Salesforce入門介紹,請查收!
一篇很全的FreeMarker指令使用1
caffe資料集的製作有幾篇csdn上的博文還是蠻有用的。我總結了一下給大家連結上
一篇很全的FreeMarker教程
整理了一份比較全面的PHP開發編碼規範.
一篇很全面的freemarker教程(收藏)
關於Java多執行緒的執行緒同步和執行緒通訊的一些小問題(順便分享幾篇高質量的博文)
這裡有一篇深度強化學習勸退文
LeetCode 31:遞迴、回溯、八皇后、全排列一篇文章全講清楚
將課程作業01的設計思想、程序流程圖、源程序代碼和結果截圖整理成一篇博文
將課程作業01、02、03的設計思想、源程序代碼和結果截圖整理成一篇博文。。
Spring整合Struts2框架的第一種方式(Action由Struts2框架來創建)。在我的上一篇博文中介紹的通過web工廠的方式獲取servcie的方法因為太麻煩,所以開發的時候不會使用。