
深度理解跳躍連結串列:一種基於概率選擇的平衡樹
跳躍連結串列:一種基於概率選擇的平衡樹
作者:林子 時間:2014年9月宣告:歡迎指出錯誤,轉載不要去掉出處
跳躍連結串列簡介
二叉樹是一種常見的資料結構。它支援包括查詢、插入、刪除等一系列操作。但它有一個致命的弱點,就是當資料的隨機性不夠時,會導致其樹形結構的不平衡,從而直接影響演算法的效率。
跳躍連結串列(Skip List)是1987年才誕生的一種嶄新的資料結構,它在進行查詢、插入、刪除等操作時的期望時間複雜度均為O(logn),有著近乎替代平衡樹的本領。而且最重要的一點,就是它的程式設計複雜度較同類的AVL樹,紅黑樹等要低得多,這使得其無論是在理解還是在推廣性上,都有著十分明顯的優勢。
跳躍連結串列的最大優勢在於無論是查詢、插入和刪除都是O(logn),不過由於跳躍連結串列的操作是基於概率形成的,那麼它操作複雜度大於O(logn)的概率為,可以看出當n越大的時候失敗的概率越小。
另外跳躍連結串列的實現也十分簡單,在平衡樹中是最易實現的一種結構。例如像複雜的紅黑樹,你很難在不依靠工具書的幫助下實現該演算法,但是跳躍連結串列不一樣,你可以很容易在半個小時內就完成其實現。
跳躍連結串列的空間複雜度的期望為O(n),連結串列的層數期望為O(logn).
如何改進普通的連結串列?
我們先看看一個普通的連結串列

可以看出查詢這個連結串列O(n),插入和刪除也是O(n).因此連結串列這種結構雖然節省空間,但是效率不高,那有沒有什麼辦法可以改進呢?
我們可以增加一條連結串列做為快速通道。這樣我們使用均勻分佈,從圖中可以看出L1層充當L0層的快速通道,底層的結點每隔固定的幾個結點出現在上面一層。

我們這裡主要以查詢操作來介紹,因為插入和刪除操作主要的複雜度也是取決於查詢,那麼兩條連結串列查詢的最好的時間複雜度是多少呢?
一次查詢操作首先要在上層遍歷<=|L1|次操作,然後在下層遍歷<=(L0/L1)次操作,至多要經歷

次操作,其中|L1|為L1的長度,n為L0的長度.
那麼最好的時間複雜度,也就怎麼設定間隔距離才能使查詢次數最少有
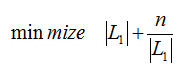
我們對|L1|的長度求導得
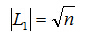
把上式代入函式,查詢次數最小也就是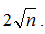
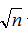
那麼三條連結串列呢

同理那麼我們讓L2/L1=L1/L0,然後同樣列出方程,求導可得L2=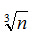
........................................................................
第k條鏈條.....查詢次數為
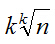
我們這裡取k=logn,代入的查詢次數為2logn.
到此為主,我們應該知道了,期望上最好的層數是logn層,而且上下層結點數比為2,這樣查詢次數常數最小,複雜度保持在O(logn)。
跳躍連結串列的結構
跳躍表由多條鏈構成(L0,L1,L2 ……,Lh),且滿足如下三個條件:
- 每條鏈必須包含兩個特殊元素:+∞ 和 -∞(其實不需要)
- L0包含所有的元素,並且所有鏈中的元素按照升序排列。
- 每條鏈中的元素集合必須包含於序數較小的鏈的元素集合。
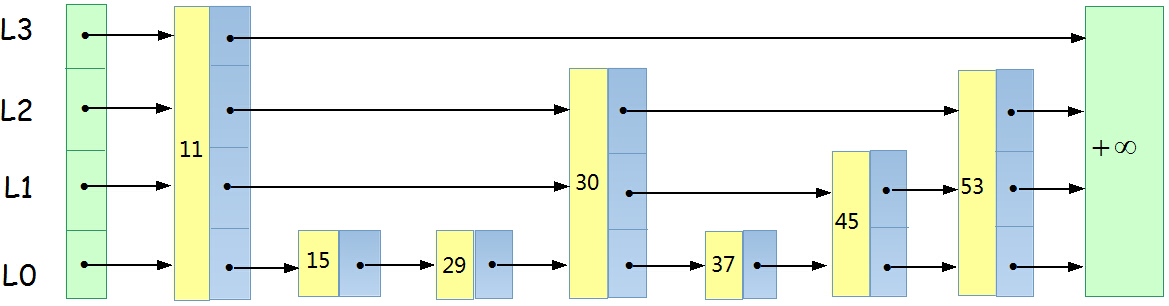
結點結構原始碼
struct node
{
int key;
struct node *forward[MAXlevel];
};MAXlevel可以是log(n)/log(2)
跳躍連結串列查詢操作
目的:在跳躍表中查詢一個元素x
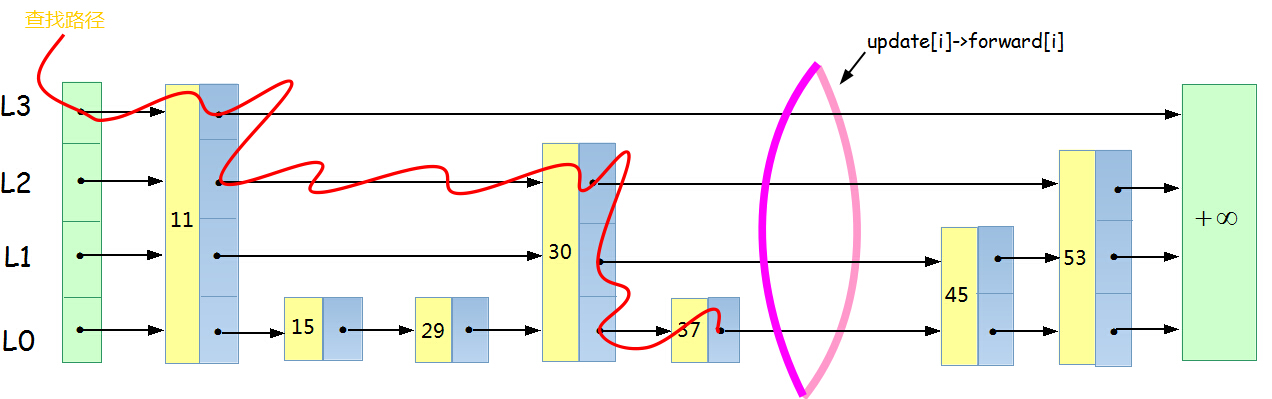
在跳躍表中查詢一個元素x,按照如下幾個步驟進行:
1. 從最上層的鏈(Lh)的開頭開始
2. 假設當前位置為p,它向右指向的節點為q(p與q不一定相鄰),且q的值為y。將y與x作比較
(1) x=y 輸出查詢成功及相關資訊
(2) x>y 從p向右移動到q的位置
(3) x<y 從p向下移動一格
3. 如果當前位置在最底層的鏈中(L0),且還要往下移動的話,則輸出查詢失敗
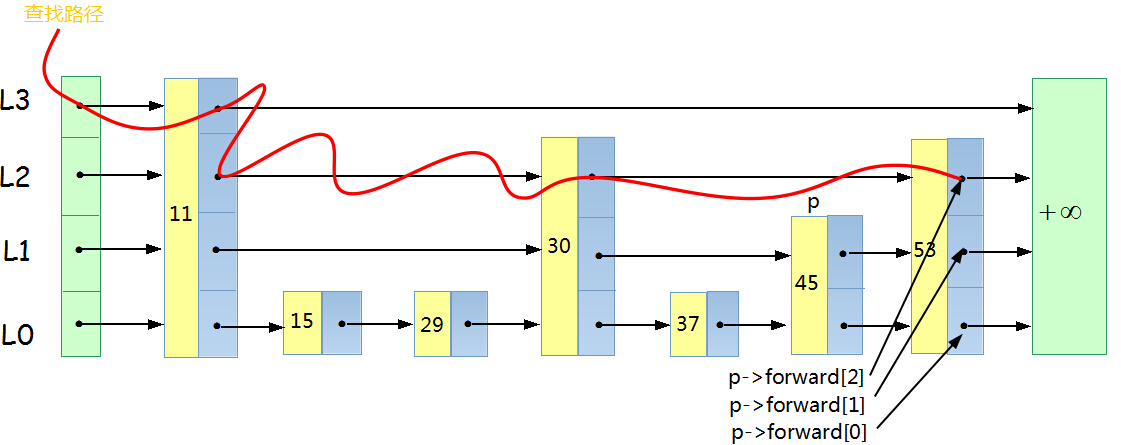
元素53的查詢路徑
struct node* search(struct node*head, int key, int level)
{
int i;
struct node *p;
p=head;
for(i=level;i>=0;i--)
while((p->forward[i]!=0)&&(p->forward[i]->key<key))
p=p->foward[i];
p==p->forward[0];//回到0級鏈,當前p或者空或者指向比搜尋關鍵字小
的前一個結點
if(p==0)//這時若p為空則推出檢索,返回0
return 0;
else if(p->key==key)//找到,返回成功
return p;
else
return 0;//否則仍然檢索失敗,返回0
}跳躍連結串列插入操作
目的:向跳躍表中插入一個元素x
首先明確,向跳躍表中插入一個元素,相當於在表中插入一列從S0中某一位置出發向上的連續一段元素。有兩個引數需要確定,即插入列的位置以及它的“高度”。
關於插入的位置,我們先利用跳躍表的查詢功能,找到比x小的最大的數y。根據跳躍表中所有鏈均是遞增序列的原則,x必然就插在y的後面。
而插入列的“高度”較前者來說顯得更加重要,也更加難以確定。由於它的不確定性,使得不同的決策可能會導致截然不同的演算法效率。為了使插入資料之後,保持該資料結構進行各種操作均為O(logn)複雜度的性質,我們引入隨機化演算法(Randomized Algorithms)。
我們定義一個隨機決策模組,它的大致內容如下:
產生一個0到1的隨機數r如果r小於一個常數p(通常取0.25或0.5),則執行方案A,否則,執行方案B.
int randX(int &level)
{
int i,j,t;
t=rand();
for(i=0;j=2;i<MAXlevel;i++,j+=j)
if(t>RAND_MAX/j)
break;
if(i>level)
level=i;
return i;
}RADN_MAX為隨機函式rand()能隨機到的最大值,每個結點的高度都由該隨機函式決定
初始時列高為1。插入元素時,不停地執行隨機決策模組。如果要求執行的是A操作,則將列的高度加1,並且繼續反覆執行隨機決策模組。直到第i次,模組要求執行的是B操作,我們結束決策,並向跳躍表中插入一個高度為i的列。
我們來看一個例子:
假設當前我們要插入元素“40”,且在執行了隨機決策模組後得到高度為4
步驟一:找到表中比40小的最大的數,確定插入位置
步驟二:插入高度為4的列,並維護跳躍表的結構
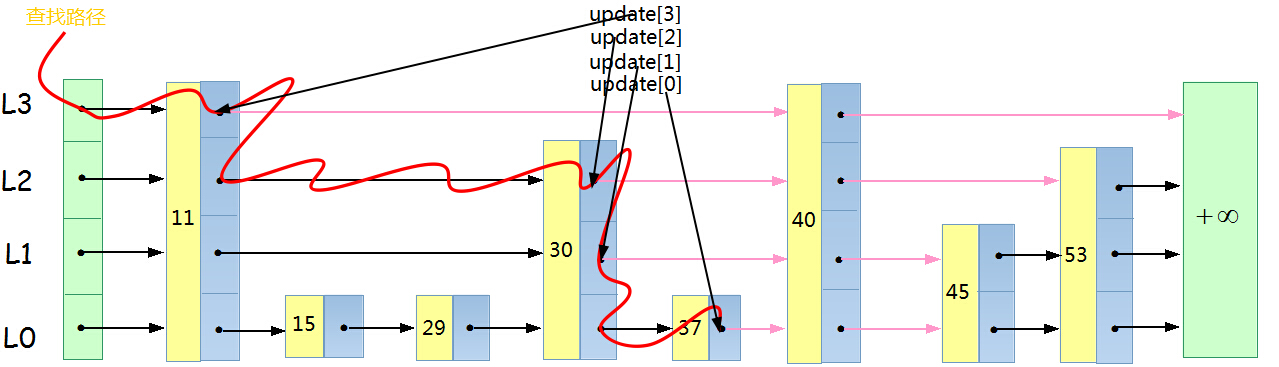
紫色的箭頭表示更新過的指標
void insert(struct node*head,int key,int &level)
{
struct node*p,*update[MAXlevel];
int i,newlevel;
p=head;
newlevel=randX(level);
for(i=level;i>=0;i---)
{
while((p->forward[i]!=0)&&(p->forward[i]->key<key))
p=p->forward[i];
update[i]=p;//update[i]記錄了搜尋過程中在各層中走過的最大的結點位置
}//設定新結點
p=new(struct node);
p->key=key;
for(i=0;i<MAXlevel;i++)
p->forward[i]=0;
for(i=0;i<=newlevel;i++)//插入是從最高的newlevel層直至0層
{
p->forward[i]=update[i]->forward[i];//插入到分配到的層數
update[i]->forward[i]=p;
}
}跳躍連結串列的刪除
目的:從跳躍表中刪除一個元素x
刪除操作分為以下三個步驟:
在跳躍表中查詢到這個元素的位置,如果未找到,則退出
將該元素所在整列從表中刪除
將多餘的“空鏈”刪除
刪除的過程即為插入的逆操作
int deletenode(struct node*head,int &level)
{
int delkey;
struct node*r;
cout<<"請輸入要刪除的數字:";
cin>>delkey;
r=search(head,delkey,level);
if(r)
{
int i=level;
struct node*p,*q;
while(i>=0)
{
p=q=head;
while(p!=r&&p!=null)
{
q=p;
p=p->forward[i];
}
if(p)
{
if(i==level&&q=head&&p->forward[i]==0)
level--;
else
q->forward[i]=p->forward[i];
}
i--;
}
delete r;
return 1;
}
else
return 0;
}跳躍連結串列的搜尋時間複雜度為O(logn)
定理:n個元素的跳躍連結串列的每一次搜尋的時間複雜度有很高的概率為O(logn).
高概率:事件E以很高的概率發生意味著對於a>=1,存在一個合適的常數使得事件E發生的概率Pr{E}>=1-O(1/n^a).
其中a是任意選擇的一個數,不同的a影響搜尋時間複雜度的常數,即a*O(logn),這個在後面介紹.
我們要證跳躍連結串列的時間複雜度,不能只是證明一次搜尋的複雜度為,是要證明全部的搜尋都是O(logn),因為這是基於概率的演算法,如果光一次有效率並沒有多大作用.
我們定義時間Ei為某一次搜尋失敗的概率,那麼假設k次搜素,我們先假定失敗的概率為O(1/n^a),其中至少有一次失敗的概率為
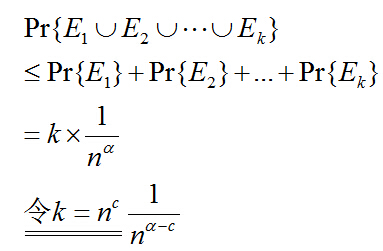
可以估算出k次有一次失敗的概率為1/n^(a-c),那麼我們只要讓a>=c+1或者a取無窮大,就可以證明每一次搜尋都具有高概率成功。
跳躍連結串列的層數有高概率為O(logn)
類似上面的方法,對於n個元素,如果有一個層數超過O(logn)就算失敗。那麼對於某一個元素超過clogn層,即失敗的概率為Pr{E}.那麼對於一次搜尋失敗的概率為

令a=c-1,則只要a>=1時,就有高概率的可能使得層數為O(logn)
跳躍連結串列單次查詢複雜度大於O(logn)的概率
每完成一次查詢,都肯定要從最頂層移動到最下面一層,這每改變一次層數是由概率選擇時候的p處於扔硬幣中的正面決定的。.既然上面知道層數高概率為clogn層,那麼扔正面的次數為clogn-1次.
我們假設扔了clogn個正面,超過10*clogn次是反面,則有


因為9-log(10e)中的9是線性增長,要遠遠大於log(10e)中的對數增長,因此超過10clogn的概率隨著10的增長變得越來越.所以全部的操作都在10logn以內,我們使用k替代10作為常數,即查詢次數為klogn,為O(logn).