
程式動態分析工具調研
綜述
本文是對程式動態工具的調研,通對各種動態分析工具的原理、功能、優缺點等方面的調研分析來使讀者在使用工具時更有針對性。
作為調研,本文並不過多的涉及工具的細節,主要關注點在於工的原理、功能、優缺點(使用領域)。具體工具可做具體瞭解。
Gprof
簡介
Gprof 是GNU gnu binutils工具之一,預設情況下linux系統當中都帶有這個工具。Gprof給出了函式呼叫的次數、呼叫耗時以及函式的呼叫關係,通過分析產生的資料結果可以確定程式的執行流程,進而有針對性的對程式進行優化。
功能
可以獲得的幾種格式的資料:1
- flat profile :給出了每個函式的耗時以及函式被呼叫的次數。
- call graph:給出了函式呼叫關係,以及對函式耗時的一個估計。
- 註釋的原始碼--是程式原始碼的一個複本,標記有程式中每行程式碼的執行次數。
原理
實現原理2
gcc -pg 在應用程式的每個函式中添加了名為 mcount/mcount/_mcount的函式。 應用程式每個函式執行時都會執mcount,而mcount則會在記憶體中儲存一張函式呼叫圖,通過函式呼叫堆疊的形式,查詢子函式、父函式的地址,也儲存了與函式相關的呼叫時間、次數等資訊。
程式執行結束後,會在程式退出的路徑下生成一個 gmon.out檔案。這個檔案就是記錄並儲存下來的監控資料。可以通過命令列方式的gprof或圖形化的Kprof來解讀這些資料並對程式的效能進行分析。
另外,如果想檢視庫函式的profiling,需要在編譯是再加入“-lc_p”編譯引數代替“-lc”編譯引數,這樣程式會連結libc_p.a 庫,才可以產生庫函式的profiling資訊。如果想執行一行一行的profiling,還需要加入“-g”編譯引數。
結果產生與分析
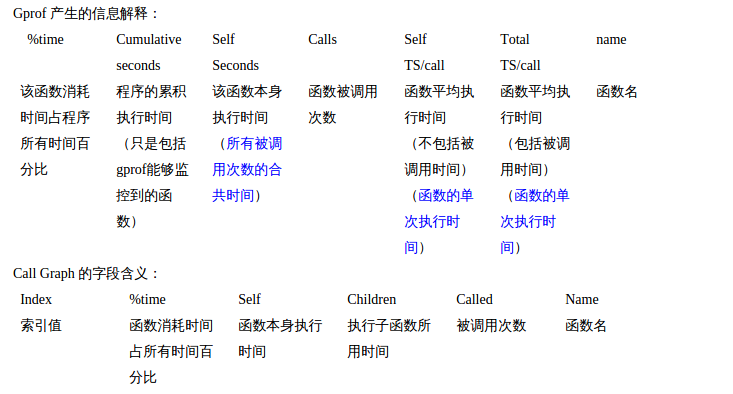
圖1 Gprof結果資訊 3
用法
- 在編譯和連結時 加上-pg選項。一般我們可以加在 makefile 中。
- 執行編譯的二進位制程式。執行引數和方式同以前。
- 在程式執行目錄下 生成 gmon.out 檔案。如果原來有gmon.out 檔案,將會被重寫。
- 結束程序。這時 gmon.out 會再次被重新整理。
- 用 gprof 工具分析 gmon.out 檔案。
優缺點4
優點
- Gprof為GNU binutils工具之一,預設情況下linux系統當中都帶有這個工具,使用方便。
- 生成結果包括函式呼叫時間以及函式呼叫關係,可以方便使用者利用該資料做進一步分析 。
缺點
- 使用插樁技術,消耗系統資源。函式的每次執行都會呼叫插樁函式mcount,並且mcount函式會在記憶體中維護一個函式呼叫圖,使得對CPU和記憶體資源都帶來消耗。
- 程式必須是正常退出才能生成gmon.out檔案,也就是說程式必須執行到main函式的return或者exit()。
- 如果程式執行的時間非常短,則Gprof可能無效,因為受到啟動、初始化、退出等函式執行時間的影響。
- 不支援多程序,如果分析多程序程式則可能一個程序的gmont.out檔案會覆蓋另一個程序的gmont.out檔案。 解決方法是在執行程式之前執行:export GMON_OUT_PREFIX=x.out 則之後生成的檔名就如x.out.pid,多程序的gmon.out就不會相互覆蓋。
- 不支援多執行緒。緣故是gprof使用ITIMER_PROF定時器, 當超時時由核心嚮應用程式傳送訊號。但多執行緒程式只有主執行緒接收ITIMER_PROF。 這裡有一個簡單的實現方法: 對pthread_create進行包裝,並以動態庫的形式在程式執行前載入。
- 只能分析應用程式在執行過程中所消耗掉的使用者時間,無法得到程式核心空間的執行時間。
Ftrace
簡介56
ftrace 的作用是幫助開發人員瞭解 Linux 核心的執行時行為,以便進行故障除錯或效能分析。最早 ftrace 是一個 function tracer,僅能夠記錄核心的函式呼叫流程。如今 ftrace 已經成為一個framework,採用 plugin (以下一般稱為tracer)的方式支援開發人員新增更多種類的 trace 功能。
ftrace一個鮮明的特點就是,對所有的操作都是對檔案的操作,比如,使用某一個tracer便將相應的函式名寫入current_tracer檔案中,# echo function tracer > current_tracer.
功能
ftrace作為一個平臺,採用外掛的方式支援開發人員新增自定義的trace功能,簡而言之,開發人員可以根據自己的需求來使用已有功能或者根據ftrace提供的API來開發滿足自己需求的外掛。ftrace自帶外掛如下表7
| 外掛 | 功能描述 |
|---|---|
| function tracer | 僅能夠記錄核心的函式呼叫流程 |
| Schedule switch tracer | 跟蹤程序排程情況 |
| Wakeup tracer | 跟蹤程序的排程延遲,即高優先順序程序從進入 ready 狀態到獲得 CPU 的延遲時間。該 tracer 只針對實時程序。 |
| Irqsoff tracer | 當中斷被禁止時,系統無法相應外部事件,比如鍵盤和滑鼠,時鐘也無法產生 tick 中斷。這意味著系統響應延遲,irqsoff 這個 tracer 能夠跟蹤並記錄核心中哪些函式禁止了中斷,對於其中中斷禁止時間最長的,irqsoff 將在 log 檔案的第一行標示出來,從而使開發人員可以迅速定位造成響應延遲的罪魁禍首。 |
| Preemptoff tracer | 和前一個 tracer 類似,preemptoff tracer 跟蹤並記錄禁止核心搶佔的函式,並清晰地顯示出禁止搶佔時間最長的核心函式。 |
| Preemptirqsoff tracer | 同上,跟蹤和記錄禁止中斷或者禁止搶佔的核心函式,以及禁止時間最長的函式。 |
| Branch tracer | 跟蹤核心程式中的 likely/unlikely 分支預測命中率情況。 Branch tracer 能夠記錄這些分支語句有多少次預測成功。從而為優化程式提供線索。 |
| Hardware branch tracer | 利用處理器的分支跟蹤能力,實現硬體級別的指令跳轉記錄。在 x86 上,主要利用了 BTS 這個特性。 |
| Initcall tracer | 記錄系統在 boot 階段所呼叫的 init call 。 |
| Mmiotrace tracer | 記錄 memory map IO 的相關資訊。 |
| Power tracer | 記錄系統電源管理相關的資訊。 |
| Sysprof tracer | 預設情況下,sysprof tracer 每隔 1 msec 對核心進行一次取樣,記錄函式呼叫和堆疊資訊。 |
| Kernel memory tracer | 記憶體 tracer 主要用來跟蹤 slab allocator 的分配情況。包括 kfree,kmem_cache_alloc 等 API 的呼叫情況,使用者程式可以根據 tracer 收集到的資訊分析內部碎片情況,找出記憶體分配最頻繁的程式碼片斷,等等。 |
| Workqueue statistical tracer | 這是一個 statistic tracer,統計系統中所有的 workqueue 的工作情況,比如有多少個 work 被插入 workqueue,多少個已經被執行等。開發人員可以以此來決定具體的 workqueue 實現,比如是使用 single threaded workqueue 還是 per cpu workqueue。 |
| Event tracer | 跟蹤系統事件,比如 timer,系統呼叫,中斷等。 |
注意:
- 這裡只是列出了比較常用的tracer,並沒有列出所有的tracer,ftrace 是目前非常活躍的開發領域,新的 tracer 將不斷被加入核心。
- available_tracers檔案記錄了當前編譯進核心的跟蹤器的列表,換句話說,預設情況下,使用者的機器上並不支援上面所有tracer。
原理
實現原理
Ftrace 有兩大組成部分,一是 framework,另外就是一系列的 tracer 。每個 tracer 完成不同的功能,它們統一由 framework 管理。 ftrace 的 trace 資訊儲存在 ring buffer 中,由 framework 負責管理。 Framework 利用 debugfs 系統在 /debugfs 下建立 tracing 目錄,並提供了一系列的控制檔案。其架構圖如下:
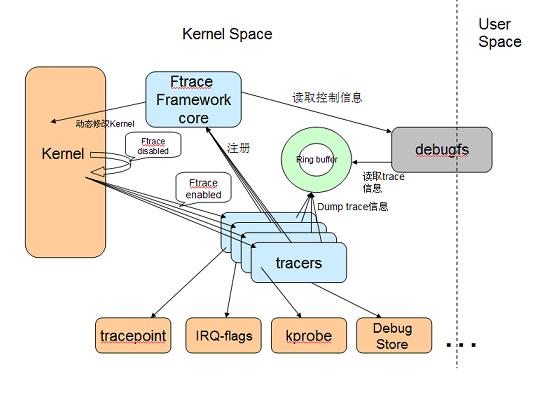
圖2 ftrace實現原理8
Ftrace本身也使用的是插樁技術, 原理類似於Gprof,但是ftrace沒有在記憶體中儲存函式呼叫圖,並且動態地使用mcount指令,只是在使用者需要時替換nop指令為mcount指令9。具體操作上,ftrace 採用 GCC 的 profile 特性在所有核心函式的開始部分加入一段 stub 程式碼,ftrace 過載這段程式碼來實現 trace 功能。gcc 的 -pg 選項將在每個函式入口處加入對 mcount 的呼叫程式碼。
結果產生與分析
由於ftrace針對不同的應用場景有不同的tracer來完成相應的工作,故而,各個tracer返回來的資料格式也不盡相同。這裡僅以ftrace中最常用的function tracer為例10:
# tracer: function
#
# TASK-PID CPU# TIMESTAMP FUNCTION
# | | | | |
bash-4251 [01] 10152.583854: path_put <-path_walk
bash-4251 [01] 10152.583855: dput <-path_put
bash-4251 [01] 10152.583855: _atomic_dec_and_lock <-dput可以看到,tracer 檔案類似一張報表,前 4 行是表頭。第一行顯示當前 tracer 的型別。第三行是 header 。對於 function tracer,該表將顯示 4 列資訊。首先是程序資訊,包括程序名和 PID ;第二列是 CPU,在 SMP 體系下,該列顯示核心函式具體在哪一個 CPU 上執行;第三列是時間戳;第四列是函式資訊,預設情況下,這裡將顯示核心函式名以及它的上一層呼叫函式。通過對這張報表的解讀,使用者便可以獲得完整的核心執行時流程。這對於理解核心程式碼也有很大的幫助。有志於精讀核心程式碼的讀者,或許可以考慮考慮 ftrace 。如上例所示,path_walk() 呼叫了 path_put 。此後 path_put 又呼叫了 dput,進而 dput 再呼叫 _atomic_dec_and_lock 。
用法
- 編譯核心使得核心支援所需要的trace。注意,ftrace是核心自帶的分析工具,如沒有特需的需求可不進行此步。
- 掛載debugfs,
# mount -t debugfs nodev /sys/kernel/debug。debugfs虛擬檔案系統是核心空間和使用者空間資料通訊的工具,掛載後,掛載點目錄下包含了ftrace相應的檔案。比如,記錄當前可用tracer的檔案available_tracers就在其中。 - 切換到目錄 /sys/kernel/debug/tracing/ 下。
- 檢視 available_tracers 檔案,獲取當前核心支援的跟蹤器列表。
5. 關閉 ftrace 跟蹤,即將 0 寫入檔案 tracing_enabled。在新的核心版本中,tracing_enabled 被刪除了,也就是說這步是不需要的,同理第9步關於tracing_enabled部分也是不需要的。關於原因13,有人問過 Ftrace 的維護人Steven Rostedt,他說使用 tracing_on 可以快速的開啟 Ftrace 的追蹤,這讓 tracing_enabled 顯得很輕量級或者說顯得比較冗餘,下面可以會說到,我們寫核心程式時可以使用Ftrace 提供的核心函式 tracing_on() or tracing_off() 直接開啟追蹤,這其實就是使用的 tracing_on ,所以在新核心中 tracing_enabled 這個看起來比較冗餘的選項已經被刪除# echo 0 > tracing_enabled - 啟用 ftrace_enabled ,否則 function 跟蹤器的行為類似於 nop;另外,啟用該選項還可以讓一些跟蹤器比如 irqsoff 獲取更豐富的資訊。建議使用 ftrace 時將其啟用。要啟用 ftrace_enabled ,可以通過 proc 檔案系統介面來設定:
# echo 1 > /proc/sys/kernel/ftrace_enabled。 - 將所選擇的跟蹤器的名字寫入檔案 current_tracer。
# echo funtion tracer > current_tracer。 - 跟蹤函式過濾。 將要跟蹤的函式寫入檔案 set_ftrace_filter ,將不希望跟蹤的函式寫入檔案 set_ftrace_notrace。通常直接操作檔案 set_ftrace_filter 就可以了。
9. 啟用 ftrace 跟蹤,即將 1 寫入檔案 tracing_enabled。還要確保檔案 tracing_on 的值也為 1,該檔案可以控制跟蹤的暫停如果是對應用程式進行分析的話,啟動應用程式的執行,ftrace 會跟蹤應用程式執行期間核心的運作情況。 - 通過將 0 寫入檔案 tracing_on 來暫停跟蹤資訊的記錄,此時跟蹤器還在跟蹤核心的執行,只是不再向檔案 trace 中寫入跟蹤資訊;或者將 0 寫入檔案 tracing_enabled 來關閉跟蹤。
- 檢視檔案 trace 獲取跟蹤資訊,對核心的執行進行分析除錯。
優缺點
優點
- 執行選擇性插樁,而非對所有的函式進行插樁,即,動態的使用mcount函式,只是在使用者需要的時候將nop替換為mcount,這樣就可以有針對的進行函式分析14。
- ftrace不需要將函式呼叫圖儲存在記憶體中,這樣就減輕了記憶體資源的消耗15。
- ftrace作為一個framework,本身自帶了各種特定功能的tracer,使用者可以直接使用。同時,使用者也可以根據自己的需求修改已有tracer或者呼叫ftrace提供的API編寫複合自己需求的tracer16。
缺點
- ftrace雖然執行的是選擇性插樁技術,但是還是會影響到程式本身效能。
SystemTap
簡介
SystemTap 是監控和跟蹤執行中的 Linux 核心的操作的動態方法。這句話的關鍵詞是動態,因為SystemTap 沒有使用工具構建一個特殊的核心,而是允許您在執行時動態地安裝該工具。它通過一個名為Kprobes 的應用程式設計介面(API)來實現該目的。
Kprobe機制,可以用來動態地收集除錯和效能資訊的工具,是一種非破壞性的工具,使用者可以用它跟蹤執行中核心任何函式或執行的指令等。相比之前的做法已經有了質的提高了,但Kprobe並沒有提供一種易用的框架,使用者需要自己去寫模組,然後安裝,對使用者的要求還是蠻高的。
相比Kprobe,systemtap更加簡單,提供給使用者簡單的命令列介面,以及編寫核心指令的指令碼語言。對於開發人員,systemtap是一款難得的工具。
功能
利用Kprobe機制動態的收集函式呼叫和程式效能相關的資訊,以此來實現動態地監控和跟蹤執行中的Linux核心。
原理
實現原理
SystemTap 用於檢查執行的核心的兩種方法是 Kprobes 和 返回探針。但是理解任何核心的最關鍵要素是核心的對映,它提供符號資訊(比如函式、變數以及它們的地址)。有了核心對映之後,就可以解決任何符號的地址,以及更改探針的行為。
Kprobes 從 2.6.9 版本開始就新增到主流的 Linux 核心中,並且為探測核心提供一般性服務。它提供一些不同的服務,但最重要的兩種服務是 Kprobe 和 Kretprobe。Kprobe 特定於架構,它在需要檢查的指令的第一個位元組中插入一個斷點指令。當呼叫該指令時,將執行鍼對探針的特定處理函式。執行完成之後,接著執行原始的指令(從斷點開始)。
Kretprobes 有所不同,它操作呼叫函式的返回結果。注意,因為一個函式可能有多個返回點,所以聽起來事情有些複雜。不過,它實際使用一種稱為 trampoline 的簡單技術。您將向函式條目新增一小段程式碼,而不是檢查函式中的每個返回點。這段程式碼使用 trampoline 地址替換堆疊上的返回地址 —— Kretprobe 地址。當該函式存在時,它沒有返回到呼叫方,而是呼叫 Kretprobe(執行它的功能),然後從 Kretprobe 返回到實際的呼叫方。
systemtap 的核心思想是定義一個事件(event),以及給出處理該事件的控制代碼(Handler)。當一個特定的事件發生時,核心執行該處理控制代碼,就像快速呼叫一個子函式一樣,處理完之後恢復到核心原始狀態。這裡有兩個概念:
事件(Event): systemtap 定義了很多種事件,例如進入或退出某個核心函式、定時器時間到、整個systemtap會話啟動或退出等等。
控制代碼(Handler):就是一些指令碼語句,描述了當事件發生時要完成的工作,通常是從事件的上下文提取資料,將它們存入內部變數中,或者打印出來。
Systemtap 工作原理是通過將指令碼語句翻譯成C語句,編譯成核心模組。模組載入之後,將所有探測的事件以鉤子的方式掛到核心上,當任何處理器上的某個事件發生時,相應鉤子上控制代碼就會被執行。最後,當systemtap會話結束之後,鉤子從核心上取下,移除模組。整個過程用一個命令 stap 就可以完成。
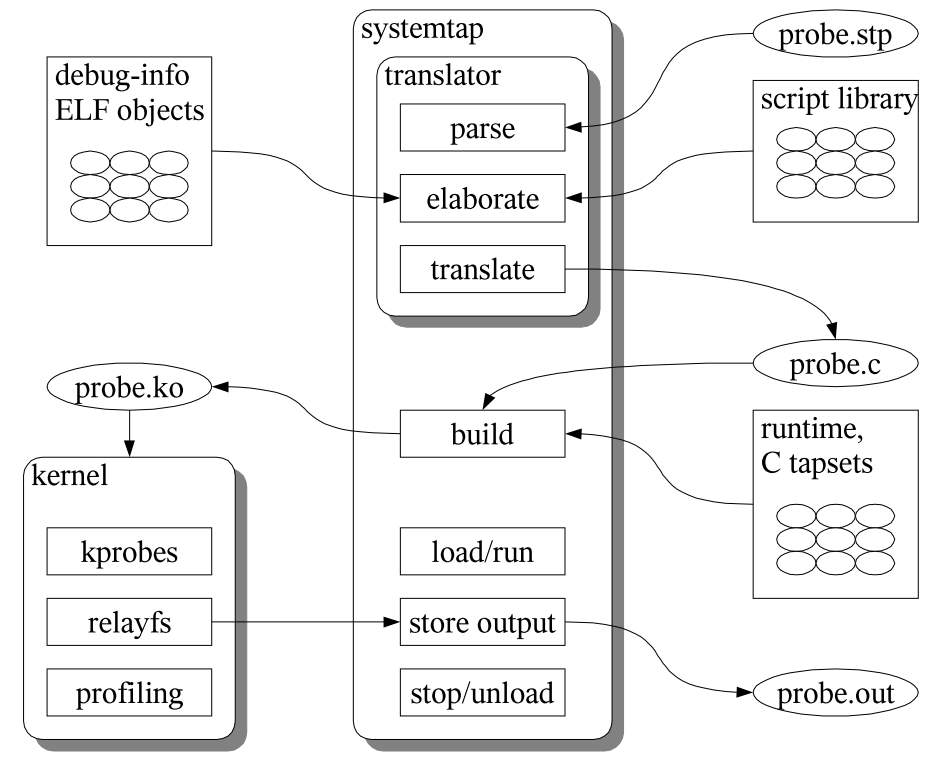
圖 3 SystemTap流程圖
資料產生與分析
由於在使用SystemTap時,使用者通過其提供的配套指令碼語言來實現自己所需功能,所以資料的產生和分析往往也是千差萬別的。往往使用者通過SystemTap提供的API獲取自己想要的資料,根據自己的需求對其進行格式化處理以便對其進行特定的分析。
用法
SystemTap的用法比較簡單靈活性也比較強,用根據其通過的指令碼語言規則和相應的API就可以很方便的得到自己想要的資料,並且按照自己需要的格式進行輸出。這裡,以一個監控 sync 系統呼叫應用作為例子17。
注意: 同Ftrace一樣SystemTap的使用需要獲取到也行系統的除錯資訊,在一般的Linux發行版本這些除錯資訊是被關閉的所以需要重新編譯核心並將這些需要的除錯選項勾選。一種更檔案簡單的方法是直接現在按照debug版本的核心。具體如何操作已經超出本文範圍,讀者可以參見參考文獻18給出的相關資料。
global syscalllist
probe begin {
printf("System Call Monitoring Started (10 seconds)...\n")
}
probe syscall.*
{
syscalllist[pid(), execname()]++
}
probe timer.ms(10000) {
foreach ( [pid, procname] in syscalllist ) {
printf("%s[%d] = %d\n", procname, pid, syscalllist[pid, procname] )
}
exit()
}指令碼包含一個全域性變數定義和 3 個獨立的探針。在首次載入指令碼時呼叫第一個探針(begin 探針)。在這個探針中,您可以發出一條表示指令碼在核心中執行的文字訊息。接下來是一個 syscall 探針。注意這裡使用的萬用字元 (*),它告訴 SystemTap 監控所有匹配的系統呼叫。當該探針觸發時,將為特定的 PID 和程序名增加一個關聯陣列元素。最後一個探針是 timer 探針。這個探針在 10,000 毫秒(10 秒)之後觸發。與這個探針相關聯的指令碼將傳送收集到的資料(遍歷每個關聯陣列成員)。當遍歷了所有成員之後,將呼叫 exit 呼叫,這導致解除安裝模組和退出所有相關的 SystemTap 程序。
指令碼的輸出如下所示。從這個指令碼中您可以看到執行在使用者空間中的每個程序,以及在 10 秒鐘內發出的系統呼叫的數量。
$ sudo stap profile.stp
System Call Monitoring Started (10 seconds)...
stapio[16208] = 104
gnome-terminal[6416] = 196
Xorg[5525] = 90
vmware-guestd[5307] = 764
hald-addon-stor[4969] = 30
hald-addon-stor[4988] = 15
update-notifier[6204] = 10
munin-node[5925] = 5
gnome-panel[6190] = 33
ntpd[5830] = 20
pulseaudio[6152] = 25
miniserv.pl[5859] = 10
syslogd[4513] = 5
gnome-power-man[6215] = 4
gconfd-2[6157] = 5
hald[4877] = 3
$優缺點
優點
- SystemTap沒有使用工具構建一個特殊的核心,而是採用在執行時動態地安裝該工具,它通過一個名為Kprobe的應用程式設計介面(API)來實現動態安裝。
- SystemTap提供語法結構比較簡單的指令碼語言,可以使的使用者根據自己的需求實現相應的指令碼來獲取相應的資料。
缺點
- SystemTap 專案是 Linux 社群對 SUN Dtrace 的反應,目標是達到甚至超越 Dtrace 。因此 SystemTap 設計比較複雜,Dtrace 作為 SUN 公司的一個專案開發了多年才最終穩定釋出,況且得到了 Solaris 核心中每個子系統開發人員的大力支援。 SystemTap 想要趕超 Dtrace,困難不僅是一樣,而且更大,因此她始終處在不斷完善自身的狀態下,在真正的產品環境,人們依然無法放心的使用她。不當的使用和 SystemTap 自身的不完善都有可能導致系統崩潰19。
- 需要支援某種程式設計介面讓使用者自定義 trace 行為,這無疑使得使用者必須對其有深入的理解,提高了使用門檻,並且需要使用者編寫大量的指令碼,這也增加了使用者的工作量。
總結
通過對Gprof、Ftrace、SystemTap三個工具的呼叫,我們不難得出如下結果:
| 工具 | 功能完備性 | 易用性 | 工具穩定性 |
|---|---|---|---|
| Gprof | + | + | + |
| SystemTap | ++ | ++ | ++ |
| Ftrace | +++ | +++ | +++ |
雖然,這些系統核心自帶的工具有些功能已經很強大,但是這些工具的使用前提都是系統必須是完全啟動的,也就是說對於系統啟動過程中的核心狀態函式的呼叫是完全無能為力的。如果要分析系統從啟動到執行整個過程的狀態必須藉助其他工具如S2E等